
BERT와 BERT 파생모델 비교(BERT, ALBERT, RoBERTa, ELECTRA, SpanBERT)
자연어처리 분야에서 아주 큰 입지를 차지하고 있는 모델인 BERT와 BERT 기반의 파생모델들에 대해 공부한 내용을 정리해봤습니다.
구글 BERT의 정석(한빛미디어)라는 책과 각 모델 관련 논문, 그리고 인터넷의 여러 게시물들을 참고하여 최대한 간략하게 정리했습니다.
순서는 다음과 같습니다.
1. BERT
2. ALBERT
3. RoBERTa
4. ELECTRA
5. SpanBERT
실제로 자연어처리 분야의 여러 태스크를 수행할 때 자주 사용되는 RoBERTa, ELECTRA와 같은 모델들이 어떤 배경에서 등장하고 어떤 특징을 지니고 있는지 간단히 확인할 수 있도록 비교했습니다.
혹시 제가 잘못 알고 있거나 잘못 작성한 내용이 있다면 피드백 부탁드리겠습니다 🤗
(참고로 노션에서 작성한 내용을 가져와 재구성한 것이라서 일부 내용은 가독성이 떨어질 수 있습니다 🥲)
1. BERT
1.1. BERT(Bidirectional Encoder Representation from Transformer)란?
: Transformer의 attention 기법을 이용한 embedding 모델
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
- QA, 텍스트 생성, 문장 분류 등과 같은 task에서 우수한 성능
- 문맥이 없는 워드투벡터(word2vec)과 같은 모델들과 달리 문맥을 고려한 임베딩 모델(동적 임베딩 생성)

1.2. BERT의 동작 방식
- 인코더-디코더가 있는 transformer와 달리 인코더만 사용
- 트랜스포머의 인코더는 애초에 양방향으로 문장을 읽을 수 있기 때문에 그 의미를 강조한 것으로 이해할 수 있다.
- 트랜스포머 인코더의 multi-head attention mechanism을 사용
1.3. BERT의 구조
컴퓨터 자원이 제한된 환경에서는 더 작은 BERT가 적합할 수 있다.
그러나 base와 같은 표준 구조가 더 정확한 결과를 제공하기 때문에 가장 널리 사용된다.
1.4. BERT 사전 학습
: 대규모 데이터셋에서 미리 학습을 진행하고 추가적인 task에 대해 가중치를 조정(파인튜닝)하도록 한다.
: BERT는 거대한 말뭉치를 기반으로 MLM, NSP 두 가지의 task를 사전 학습한다.
1.4.1. BERT의 입력 표현
- 토큰 임베딩(token embedding)
’my dog is cute’, ‘he likes playing’ 이라는 두 문장을 모두 토큰화한다.
그리고 첫 번째 문장 앞에만 [CLS] 토큰을 추가하고, 모든 문장의 마지막에 [SEP] 토큰을 추가한다.
이 토큰들을 embedding layer을 사용해 embedding으로 변환한다.
토큰 임베딩의 변수들은 사전 학습이 진행되며 학습된다. - 세그먼트 임베딩(segment embedding)
segment embedding은 주어진 두 문장을 구분하기 위한 지표로 사용된다.
위 예시에서는 첫 번째 [SEP]과 he를 경계로 E_A, E_B로 구분이 되어있다.
만약 문장이 한 개만 주어진다면 문장의 모든 토큰이 E_A로 매핑될 것이다. - 위치 임베딩(position embedding)
transformer에서와 마찬가지로 순서(위치)에 대한 정보를 제공할 필요가 있다.
문장에 추가하는 [CLS], [SEP] 토큰도 하나의 자리를 차지하는 것으로 보고 맨 앞에서부터 순서대로 위치 정보를 제공한다.
주어진 문장을 토큰으로 변환하여 각각 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩 레이어를 통해 임베딩을 얻는다.
최종적으로 이 세 임베딩을 합산하여 BERT에 입력으로 제공한다.
- 워드피스(WordPiece) 토크나이저 : BPE(Byte Pair Encdoing)를 활용
- 주어진 문장을 토큰화할 때 BPE를 이용한 것으로 이해할 수 있다.
- 단, BPE가 빈도를 기준으로 심볼 쌍을 병합했다면, WordPiece는 likelihood(가능도)를 기준으로 기호 쌍을 병합했다는 차이점이 있다.
- BPE를 공부하기엔 아래 블로그 게시물이 최고인듯
- 주어진 문장을 토큰화할 때 BPE를 이용한 것으로 이해할 수 있다.
[NLP]BPE 알고리즘(토크나이저)
BPE 알고리즘
ssunbell.github.io
1.4.2. 사전 학습 전략
- 언어 모델링 : 임의의 문장이 주어지고 단어를 순서대로 보면서 다음 단어를 예측하도록 모델을 학습시키는 것
- 자동 회귀 언어 모델링(auto-regressive language modeling) : 단방향
- 자동 인코딩 언어 모델링(auto-encoding language modeling) : 양방향
- 마스크 언어 모델링(MLM) : 주어진 입력 문장 중 전체 단어의 15%를 무작위로 마스킹하고 이를 예측하도록 모델을 학습시키는 것, 빈칸 채우기 태스크(cloze task)라고도 한다.
- 문제점 : fine-tuning할 때의 입력에는 [MASK] 토큰이 없기 때문에 학습 방식에 불일치가 발생한다.
- 해결책 : 80-10-10% 규칙
- 15% 중 80%만을 [MASK] 토큰으로 교체
- 15% 중 10%의 토큰을 임의의 토큰(다른 단어)로 교체
- 15% 중 나머지 10% 토큰은 그대로 보존
- 토큰화 및 마스킹 후 입력 토큰을 token, segment, position layer에 입력해 embedding을 얻는다.
- BERT에서 반환된 R_[MASK] 토큰을 feedforward network에 입력한다. 그러면 R_[MASK] 단어가 마스크된 단어가 될 확률을 반환한다(원래 무슨 단어였을지에 대한 확률).
- 전체 단어 마스킹(WWM, Whole Word Masking) 입력으로 주어진 문장을 토큰화하고 그 중 15%를 랜덤으로 마스킹한다.
이때 하위 단어가 마스킹 되었을 경우 관련 모든 단어를 마스킹하는 기법이다.
만약 추가로 마스킹을 하는 과정에서 총 마스크 비율이 15%를 초과하게 되면 다른 단어의 마스킹을 무시하도록 한다.
- 다음 문장 예측(NSP) : 두 문장을 입력하고 두 번째 문장이 첫 번째 문장의 다음 문장인지 예측하도록 하는 이진 분류 task
- NSP task를 수행함으로써 모델을 두 문장 사이의 관계를 파악할 수 있다.
→ 질문-응답 및 유사문장탐지와 같은 downstream task에서 유용 - 한 문서에서 연속된 문장을 isNext로 표시, 한 문장과 임의의 다른 문장을 가져와 notNext로 표시하여 50%의 균형을 유지하도록 한다.
- 여기서도 마찬가지로 R_[CLS] 토큰만 softmax를 적용하여 feed-forward network에 입력한다.
[CLS] 토큰은 기본적으로 모든 토큰의 집계 표현을 보유하고 있기 때문에 문장 전체를 대변하는 것이나 마찬가지기 때문이다.
- NSP task를 수행함으로써 모델을 두 문장 사이의 관계를 파악할 수 있다.
1.4.3. 사전 학습 절차
- 말뭉치에서 두 문장을 샘플링한다.
이때 두 문장의 총 토큰 수의 합은 512보다 작거나 같아야 한다.
두 문장을 샘플링할 때 두 문장 A,B에 대해, 전체의 50%는 B 문장이 A 문장의 후속 문장이 되도록, 나머지는 그렇지 않을 수 있도록 한다. - WordPiece tokenizer를 사용해 문장을 토큰화하고, 첫 번째 문장의 시작 부분에 [CLS] 토큰을 추가한다.
그리고 모든 문장의 끝에 [SEP] 토큰을 추가한다. - 80-10-10% 규칙에 따라 토큰의 15%를 무작위로 마스킹한다.
- 토큰을 BERT에 입력하고 마스크된 토큰을 예측하기 위해 모델을 학습시키면서 동시에 B 문장이 A 문장의 후속 문장인지 여부를 분류하게 한다.
즉, MLM과 NSP 작업을 동시에 사용하여 BERT를 학습시킨다는 뜻이다.
BERT 학습 특징
- 훈련 데이터는 위키피디아(25억 단어) + BooksCorpus(8억 단어) ⇒ 약 33억 단어
- Batch size = 256, Learning rate = 1e-4(10^-4), Warmup = 10,000 step(scheduling), Dropout = 0.1
- Activation function = GELU

2. ALBERT
: A Lite version of BERT
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations and longer training times. To
arxiv.org
- BERT-base의 경우 1억 1천만 개의 변수로 구성되어 모델 학습이 어렵고 추론 시간이 많이 걸린다.
모델 성능은 좋지만 학습하는 것 자체가 어렵고 추론 시간이 많이 걸리며 자원을 많이 소모한다는 문제점을 안고 있는 것이다. - ALBERT는 위 문제를 해결하기 위해 두 가지 방법을 사용하여 BERT 보다 적은 숫자의 변수를 사용한다.
- cross-layer parameter sharing (크로스 레이어 변수 공유)
- factorized embedding layer parameterization (펙토라이즈 임베딩 레이어 변수화)
2.1. cross-layer parameter sharing (크로스 레이어 변수 공유)
- BERT-base의 경우 12개의 인코더 레이어로 구성되어 있다.
이때 각 인코더 레이어는 동일한 형태를 가지므로, 첫 번째 인코더 레이어의 변수를 다른 레이어와 공유하여 변수의 개수를 줄일 수 있다. - 계층 간의 변수를 공유하는 방법은 여러 가지가 있다.
- All-shared(default) : 첫 번째 인코더의 하위 레이어에 있는 모든 변수를 나머지 인코더와 공유
- Shared feedforward network : 첫 번째 인코더 레이어의 피드포워드 네트워크의 변수만 다른 인코더 레이어의 피드포워드 네트워크와 공유
- Shared attention: 첫 번째 인코더 레이어의 멀티 헤드 어텐션의 변수만 다른 인코더 레이어와 공유
2.2. factorized embedding layer parameterization (펙토라이즈 임베딩 변수화)
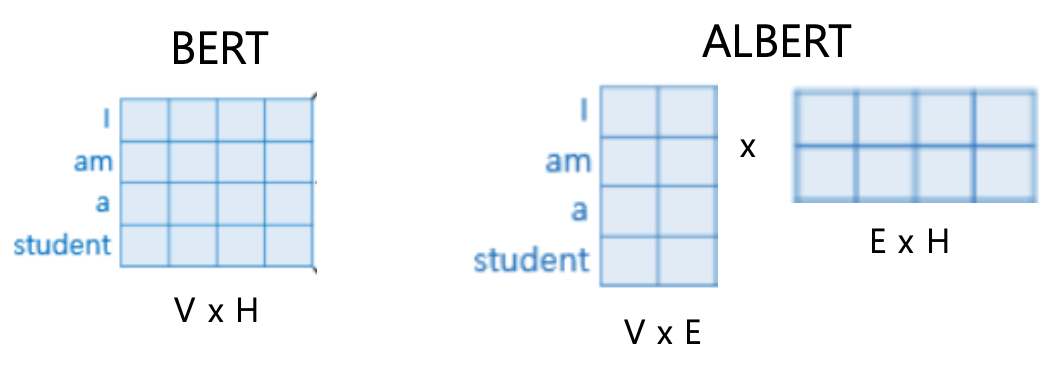
- WordPiece embedding size는 hidden size와 같다.
워드피스 임베딩은 비맥락적(non-contextual)인 표현이고, 원-핫 인코딩된 어휘 벡터(vocab)에서 학습이 이루어진다.
hidden layer embedding은 인코더를 통해 맥락적 의미를 가지는 형태로 학습이 이뤄진다. - 사전 크기 V = 30,000(BERT), hidden layer size H = 768, WordPiece embedding size E
→ hidden layer embedding size = V x H = 30,000 * 768
→ WordPiece embedding size = V x H(=E) = 30,000 * 768
⇒ 은닉 레이어의 임베딩 크기 H를 키우면 워드피스 임베딩 크기 E도 같이 증가한다. - factorization(행렬 분해)를 사용하여 원-핫 인코딩된 어휘 벡터를 은닉 공간(V x H)에 직접 투영하는 대신, 낮은 차원의 임베딩 공간(V x E)에 먼저 투영하고, 그 다음으로 은닉 공간(E x H)으로 투영한다.
- WordPiece Embedding size E = 128 일 때, → V x E = 30,000 * 128 → E x H = 128 * 768
- BERT : 30,000 * 768 = 23,040,000
ALBERT : 30,000 * 128 + 128 * 768 = 3,938,304
⇒ parameters의 수가 약 6배 차이나는 것을 확인할 수 있다.
2.3. ALBERT 모델 학습
- 영문 위키피디아 및 토론토 책 말뭉치 데이터셋 사용
- MLM은 사용하지만 NSP는 사용하지 않음
- 실제로 유용하지 않고 MLM 대비 난이도가 높지 않다.
- 문장의 일관성 뿐만 아니라 주제에 대한 예측을 포함하는 task임을 지적
⇒ 이런 문제점을 해결하기 위해 SOP task를 도입
- 문장 순서 예측(SOP)
- NSP와 유사한 이진 분류 형태의 태스크
- 한 쌍의 문장이 문장 순서가 바뀌었는지 여부를 예측하도록 모델을 학습시킨다.
- 문장 1: I love you . 문장 2: I love you, too. → positive (문장 순서가 바뀌지 않음)
- 문장 1: I love you, too. 문장 2: I love you. → negative (문장 순서가 바뀜)
2.4. ALBERT와 BERT 비교
BERT에서는 Hidden size와 Embedding size가 동일한 것과 달리,
ALBERT에서는 Hidden size가 늘어나더라도 Embedding size가 그대로임을 확인할 수 있다.
결과적으로 layer의 숫자는 동일하거나 더 커졌지만 parameters의 숫자는 적어졌다.
2.5. ALBERT에서 임베딩 추출
model = AlbertModel.from_pretrained('albert-base-v2')
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
sentence = "Paris is a beautiful city"
inputs = tokenizer(sentence, return_tensors="pt")
hidden_rep, cls_head = model(**inputs).to_tuple()
이런 식으로 사전 학습된 모델을 불러와 원하는 (downstream) task에 적용하는 것을 fine-tuning이라고 한다.
3. RoBERTa
: Robustly Optimized BERT pre-training Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperpar
arxiv.org
BERT 모델을 사전 학습시킬 때 사용할 수 있는 몇 가지 방법을 제안했다.
- MLM task에서 정적 마스킹이 아닌 동적 마스킹 방법을 적용 (동적 임베딩과 헷갈리지 말 것)
- NSP task를 제거하고 MLM task만 학습에 사용 (SOP를 사용한 ALBERT와 차이)
- 배치 크기를 증가시킴
- 토크나이저로 BBPE(byte-level BPE)를 사용
3.1. 정적 마스크 대신 동적 마스크 사용
- 기존 BERT에서는 한 문장에 대해 적용한 마스킹을 여러 epoch 동안에 동일한 input으로 사용했다.
ex) tokens = [ [CLS], we, arrived, at, the, airport, in, time, [SEP] ]
→ tokens = [ [CLS], we, [MASK], at, the, airport, in, [MASK], [SEP] ] - RoBERTa에서는 한 문장을 여러 개로 복사해 랜덤하게 다른 mask를 적용한다.
ex) tokens = [ [CLS], we, arrived, at, the, airport, in, time, [SEP] ]
→ tokens = [ [CLS], we, [MASK], at, the, airport, in, [MASK], [SEP] ]
→ tokens = [ [CLS], we, arrived, [MASK], the, airport, in, [MASK], [SEP] ]
→ tokens = [ [CLS], we, arrived, at, [MASK], airport, [MASK], time, [SEP] ] … - 만약 문장 1개를 10개로 복사하고 40번 epoch을 돌리면, 동일한 마스크된 토큰은 모델 학습시 네 번만 사용된다.
기존 BERT의 방식이었다면 40번의 epoch 동안 동일한 마스크된 토큰이 사용되었을 것이다.
3.2. NSP 태스크 제거
NSP 태스크의 중요성을 확인하기 위한 실험은 다음과 같다.
- SEGMENT-PAIR + NSP : NSP를 사용해 BERT를 학습시킨다.
원래 BERT 모델의 학습 방법과 유사하며, 입력은 512개 이하의 토큰 쌍으로 구성한다. - SENTENCE-PAIR + NSP : NSP를 사용해 BERT를 학습시킨다.
입력값은 한 문서의 연속된 부분 또는 다른 문서에서 추출한 문장을 쌍으로 구성하고, 512개 이하의 토큰 쌍을 입력한다. - FULL SENTENCES : NSP를 사용하지 않고 BERT를 학습시킨다.
여기서 입력값은 하나 이상의 문서에서 지속적으로 샘플링한 결과를 사용한다. 입력 토큰은 512 토큰이다.
하나의 문서 마지막까지 샘플링을 한 이후에는 다음 문서에서 샘플링 작업을 이어간다. - DOC SENTENCES : NSP를 사용하지 않고 BERT를 학습시킨다.
입력값은 하나의 문서에서만 샘플링한 결과만 입력한다. 즉, 다음 문서의 내용을 사용하지 않는다.
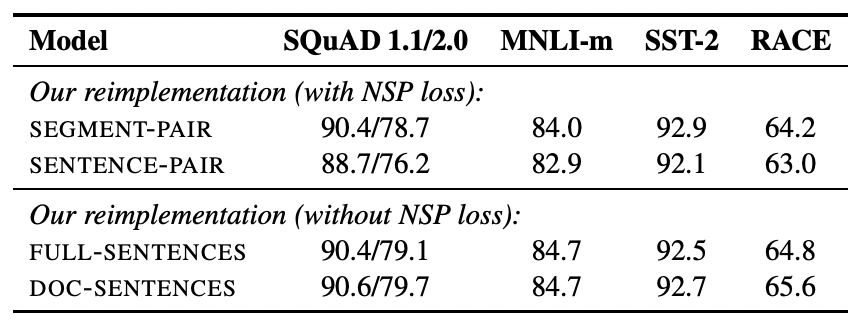
❗ BERT는 NSP 태스크를 수행하지 않고 학습하는 것이 성능 향상으로 이어진다는 결론을 내릴 수 있다.
단일 문서에서 문장을 샘플링하는 DOC-SENTENCES가 더 좋은 성능을 가지는 것으로 보인다.
그러나 이는 문서에 따라 배치 크기가 달라지기 때문에, 그 영향을 받지 않을 수 있는 FULL-SENTENCES 설정을 사용해 학습을 진행한다.
⇒ NSP 제외, MLM만 사용 / 하나 이상의 문서에서 지속적으로 샘플링하여 입력 / 최대 512개 토큰
3.3. 데이터 & 배치
3.3.1. 데이터
- BERT : 영어 위키피디아 + 토론토 책 말뭉치 → 16GB
- RoBERTa : BERT + CC-News, Open WebText, Stories → 160GB (BERT의 약 10배 수준)
3.3.2. 큰 배치 크기로 학습
- BERT : 256개 배치, 100만 스텝
- RoBERTa : 8,000개 배치, 30만 스텝 (or 8,000개 배치, 50만 스텝 가능)
❗ 배치 크기를 키우면 학습 속도를 높일 수 있고 모델 성능 또한 향상시킬 수 있다.
3.4. BBPE 토크나이저 사용
- BERT : 사전크기 3만, WordPiece tokenizer(BPE와 유사, but 빈도가 아닌 가능도(likelihood) 기반)
- RoBERTa : 사전크기 5만, BBPE tokenizer(byte 형태의 sequence)
from transformers import RobertaConfig, RobertaModel, RobertaTokenizer
model = RobertaModel.from_pretrained('roberta-base')
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
tokenizer.tokenize(' It was a great day') # 공백을 추가하여 비교
tokenizer.tokenize('I had a sudden epiphany')
4. ELECTRA
: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, the
arxiv.org
- BERT에서 MLM task를 사전 학습에 사용하는 것과 달리, ELECTRA는 replaced token detection(교체한 토큰 탐지) task를 통해 사전 학습을 진행한다.
- MLM에서 [MLM] 토큰으로 마스킹할 대상이 되는 토큰들을 ‘다른 토큰’으로 변경한 뒤, 이 토큰이 실제 토큰인지 아니면 교체한 토큰인지를 판별하는 형태로 학습을 진행한다.
- replaced token detection task를 수행하는 이유 :
MLM task의 문제는 [MLM] 토큰을 사전 학습에서만 사용하고 fine tuning task에서는 사용하지 않는다는 점이다.
→ upstream task - downstream task 간의 토큰에 대한 불일치 발생
→ 따라서 사전 학습과 파인 튜닝 사이의 불일치 문제를 해결하기 위한 것으로 이해할 수 있다.
4.1. 교체한 토큰 판별 태스크 이해하기
- 주어진 입력 문장 ‘The chef cooked the meal’을 tokenizing 한다.
→ tokens = [ the, chef, cooked, the, meal ] - 전체 토큰 중 15%를 [MASK] 토큰으로 교체한다.
→ tokens = [ [MASK], chef, [MASK], the, meal ] - 토큰을 다른 BERT 모델에 입력해 마스크된 토큰을 예측한다.
이때 BERT가 토큰에 대한 확률 분포를 결과로 제공하기 때문에, BERT를 generator(생성자)라고 부른다. - 주어진 문장의 토큰을 generator가 생성한 토큰으로 교체한다.
→ tokens = [ the, chef, ate, the, meal ] - 교체된 토큰을 discriminator(판별자)에 입력하여 주어진 토큰이 원래인지 아닌지를 판별하도록 모델을 학습시킨다.
이때 discriminator가 ELECTRA 모델이다.
학습 후에는 generator를 제거하고 discriminaotr를 ELECTRA 모델로 사용한다.
4.2. ELECTRA의 생성자와 판별자 이해하기
- 생성자(generator)
- 생성자는 위에서 설명한 것처럼 BERT 모델이다.
즉, transformer의 encoder(base 기준 12개)를 통해 계산을 수행한다. - 입력 토큰 X를 생성자에 입력하면 여러 개의 인코더를 거쳐 사전의 각 단어의 확률 결과를 출력해준다.
이때 softmax 함수를 사용하여 사전의 각 단어가 마스크된 단어일 확률을 출력한다.
여기서 e는 토큰 임베딩을 의미한다(아래 수식 사진 참고). - 위 확률 분포를 기반으로 확률이 가장 높은 단어를 마스킹한 토큰으로 선택한다.
이제 입력 토큰을 예측 토큰으로 변경하고 이를 판별자(discriminator)에 입력한다.
- 생성자는 위에서 설명한 것처럼 BERT 모델이다.
- 판별자(discriminator)
- 주어진 토큰이 생성자(generator)에 의해 만들어진 것인지 원래 토큰인지를 판별
- 생성자를 통해 변경된 토큰을 판별자에 입력으로 주어 새로운 토큰을 얻는다. (판별자도 12개의 인코더를 가지고 있다)
→ 이 토큰을 시그모이드 함수를 가지고 있는 feed-forward network의 분류기에 입력해 주어진 토큰이 원래 것인지 아닌지를 판별하는 값을 얻는다.
- ELECTRA의 장점
- BERT는 전체 토큰의 15%만 마스킹하여 학습을 진행한다.
즉, 모델 학습이 15%의 마스크된 토큰을 예측하는 것을 중심으로 이뤄진다. - ELECTRA는 주어진 토큰의 원본 여부를 판별하는 방법으로 학습을 진행한다.
- BERT는 전체 토큰의 15%만 마스킹하여 학습을 진행한다.
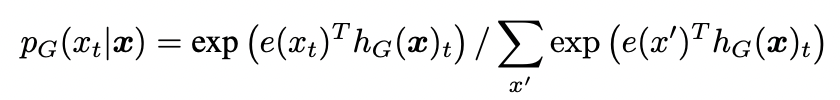
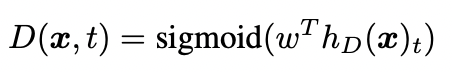
4.3. ELECTRA 모델 학습
주어진 입력 X에 대해 일부 위치를 마스킹 한 것을 X^masked, 이를 generator에 입력하여 출력된 예측 결과를 X^corrupted라고 한다.
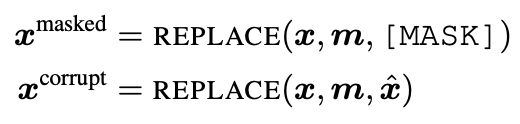
생성자의 손실 함수는 다음과 같다.
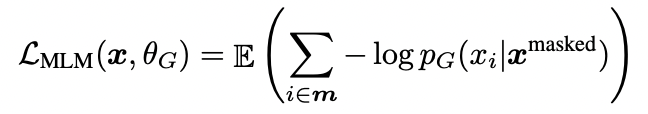
변경한 토큰 X^corrupted를 discriminator에 입력하면, 판별자는 해당 토큰이 원래 토큰인지 아닌지를 판별한다.
이때 판별자의 손실 함수는 다음과 같다.
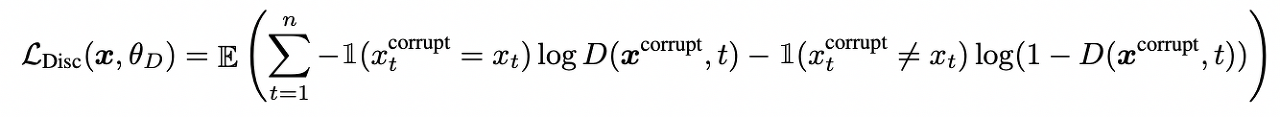
생성자와 판별자의 손실을 최소화하는 방식으로 ELECTRA 모델을 학습시킨다. 이때 손실의 합은 다음 수식과 같다.
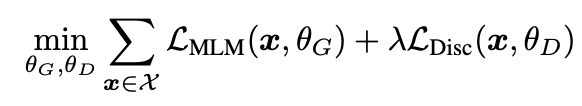
- 위 식에서 θ_G, θ_D는 각각 생성자와 판별자의 변수를 의미한다.
- X는 대규모 텍스트 말뭉치를 의미한다.
4.4. 효율적인 학습 방법 탐색
- 생성자와 판별자의 가중치를 공유한다.
(생성자와 판별자 크기가 같다면 인코더의 가중치를 공유할 수 있다.) - 하지만, 생성자와 판별자의 크기가 같다면 학습 시간이 늘어난다.
이를 방지하기 위해 생성자 크기를 작게 해 모델 학습을 진행한다.
→ 임베딩의 학습 시간을 줄일 수 있다. - ELECTRA-small : 12개의 encoder, hidden size = 256
ELECTRA-base : 12개의 encoder, hidden size = 768
ELECTRA-large : 24개의 encoder, hidden size = 1,024
from transformers import ElectraTokenizer, ElectraModel
model = ElectraModel.from_pretrained('google/electra-small-discriminator') # 판별자
model = ElectraModel.from_pretrained('google/electra-small-generator') # 생성자
5. SpanBERT
: 텍스트 범위를 예측하는 질문-응답 task에 주로 사용된다.
SpanBERT: Improving Pre-training by Representing and Predicting Spans
SpanBERT: Improving Pre-training by Representing and Predicting Spans
We present SpanBERT, a pre-training method that is designed to better represent and predict spans of text. Our approach extends BERT by (1) masking contiguous random spans, rather than random tokens, and (2) training the span boundary representations to pr
arxiv.org
5.1. SpanBERT의 architecture
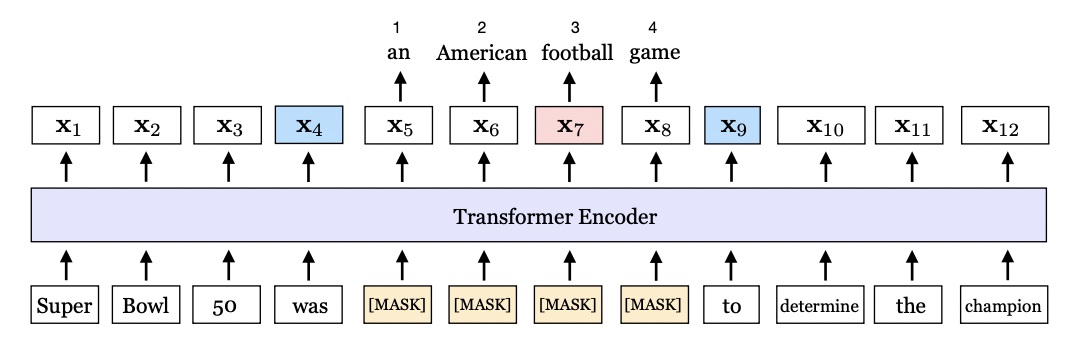
- 주어진 문장을 토큰화 한다.
tokens = [ Super, Bowl, 50, was, an, American, football, game, to, determine, the, champion ] - 토큰의 연속 범위를 무작위로 마스킹한다.
→ tokens = [ Super, Bowl, 50, was, [MASK], [MASK], [MASK], [MASK], to, determine, the, champion ] - masked된 토큰들을 SpanBERT 모델에 입력한다.
architecture에서 볼 수 있듯이 SpanBERT도 Transforemr의 Encoder를 사용한다.
위 architecture에서 출력은 X로 표현된다. - masked된 토큰을 예측하기 위해 MLM과 새로운 목적 함수인 SBO(Span Boundary Objective)를 사용하여 SpanBERT를 학습시킨다.
- span의 경계가 되는 두 토큰만을 사용한다.(MLM과의 차이점)
여기서는 파란색으로 표시된 x4, x9만을 이용하는 것이다. - span 내부의 토큰들을 구분하기 위해서 position embedding을 같이 사용한다.
위 예시에는 x5, x6, x7, x8에 대해 p1, p2, p3, p4이 할당된다.
❗ SBO를 위해 ‘span 경계 토큰의 표현(x4, x9)’과 ‘마스크된 토큰의 position embedding(p1, … , p4)’을 함께 사용한다.
5.2. SpanBERT 탐색
$$ x_s, x_e => (R_{s-1}, R_{e+1}), p_{i-s+1} $$
- 마스크된 토큰의 시작 지점을 x_s, 종료 지점을 x_e라고 할 때, 이를 토큰에 대한 표현 R로 편경하면 span의 경계는 R_s-1, R_e+1이 된다.
- 또한 마스크된 토큰의 위치 임베딩은 p_i-s+1이 된다. 결국 경계 두 개와 위치 임베딩을 사용하는 함수는 다음과 같이 표현된다.
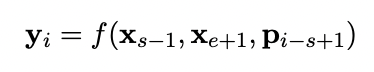
- 함수 f는 2개의 feed-forward network와 GeLU 활성화 함수로 구성되어 있다.
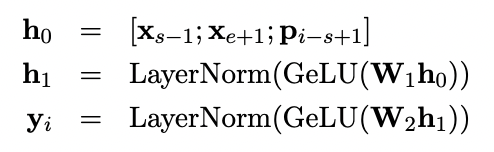
- 마스크된 토큰 x를 예측하기 위해서는 y 표현만 사용하면 된다.
이를 분류기(discriminator)에 입력하면 사전 안의 모든 단어가 마스크된 단어일 확률을 얻게 된다.
→ SBO에서 마스크된 토큰 x를 예측할 때는 ‘span 경계 토큰 표현’과 ‘마스크된 토큰의 위치 임베딩 정보를 가진 y’를 함께 사용한다.
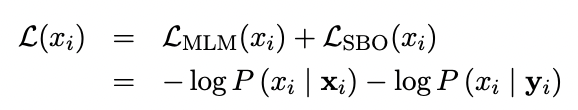
- SpanBERT의 손실 함수는 MLM과 SBO 로스를 더한 값이다. 이를 최소화하기 위한 방향으로 SpanBERT를 학습시킨다.
5.3. SpanBERT QA 예시
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model='mrm8488/spanbert-large-finetuned-squadv2',
tokenizer='SpanBERT/spanbert-large-cased'
)
results = qa_pipeline({
'question': 'What is machine learning?',
'context': "Machine learning is a subject of artificial intelligence. It is widely for creating a variety of applications such as email filtering and computer vision"
})
print(results['answer'])