<Agent, VLM> CogAgent: A Visual Language Model for GUI Agents (2023.12)
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Tsinghua University, Zhipu AI]
- GUI에 대한 이해가 뛰어난 18B 사이즈의 Visual Language Model (VLM)을 도입
- low-resolution & high-resolution image encoder를 동시에 사용하고 cross attention
- VQA & GUI 벤치마크 둘 다에서 뛰어난 성능이 확인됨
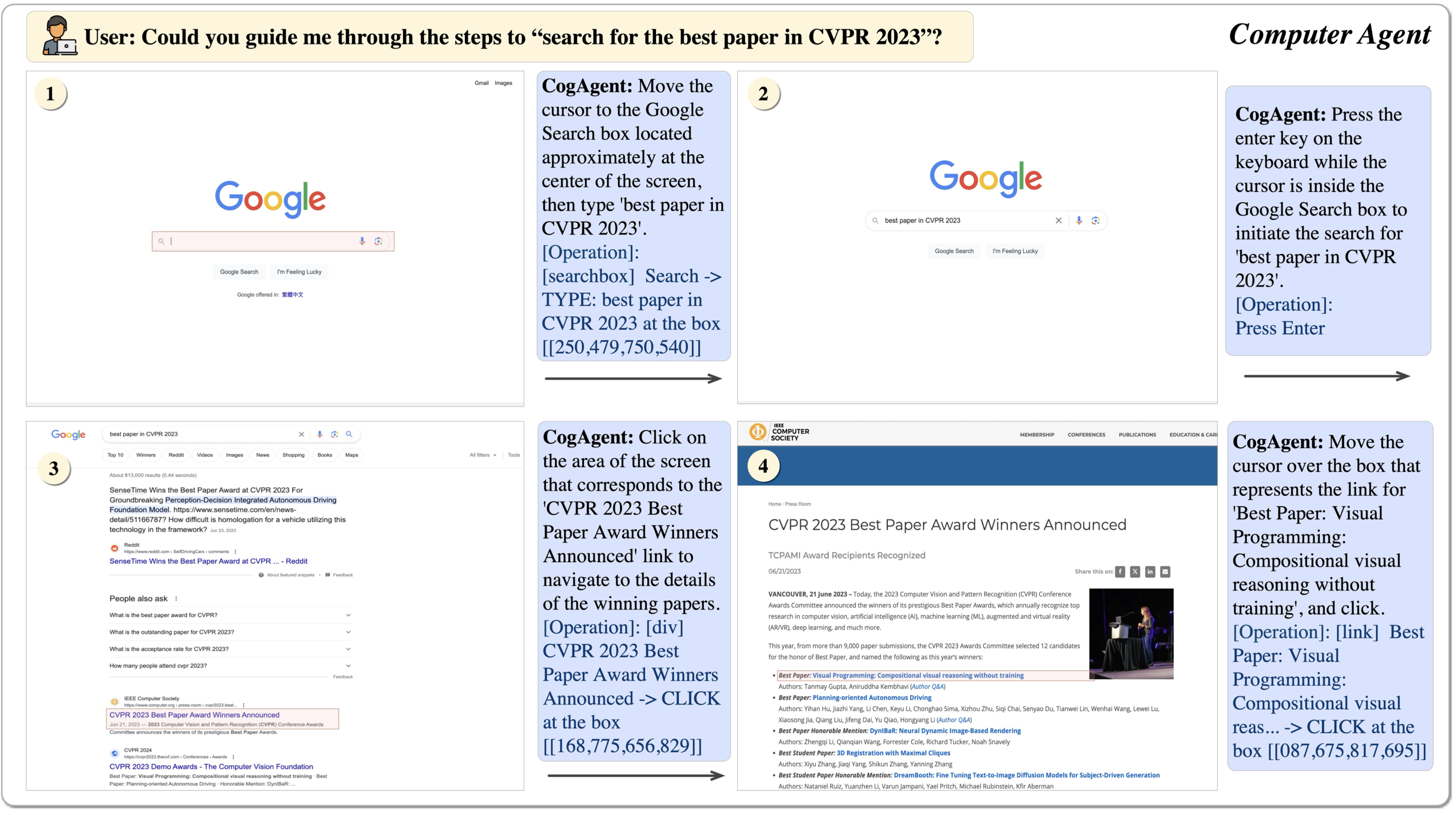
1. Introduction
- 최근 LLM을 바탕으로 한 agent의 성장세가 가파른 상황입니다.
- 무려 15만 개의 star를 받은 AutoGPT를 시작으로 LLM의 능력을 다양한 application 활용에 사용하고자 하는 시도가 많습니다.
- 하지만 대부분의 application은 Graphical User Interfaces (GUIs)를 갖추고 있어 언어 기반 agent가 처리하기 어렵다는 문제를 안고 있습니다.
- 그 이유는 크게 세 가지로 다음과 같습니다.
- interaction을 위한 표준 API가 부족하다.
- icon, image 등과 같이 중요한 정보들은 단어(말)로 표현되기 어렵다.
- 웹 페이지와 같이 text-rendered GUI라고 할지라도 정확한 functionality를 파악하기 어려운 요소들이 있다. (예를 들어 canvas, iframe 등)
- 본 연구에서는 기존에 텍스트 또는 공간적 정보로 한정되던 VLM의 입력 데이터에 visual feature를 효과적으로 추가하는 방식에 대해 논하고 있습니다.
- 이를 통해 cross-modality task를 잘 수행하게 되는 것이 목표입니다.
- Contributions을 요약하면 다음과 같습니다.
- CogAgent는 GUI understanding & decision-making 벤치마크에서 최우수 성적을 거두었습니다.
- CogAgent는 GUI 뿐만 아니라 VQA 태스크에 대해서도 가장 뛰어난 성능을 보여주었습니다. (여러 태스크에서 SoTA 달성)
- high- & low-resolution branch가 독립적으로 동작함으로 인해 연산량(FLOPs)을 획기적으로 줄일 수 있었습니다. 1120 x 1120 사이즈의 이미지를 input으로 사용하면서도 490 x 490 사이즈를 입력으로 받는 모델보다 연산량이 낮습니다.
2. Method
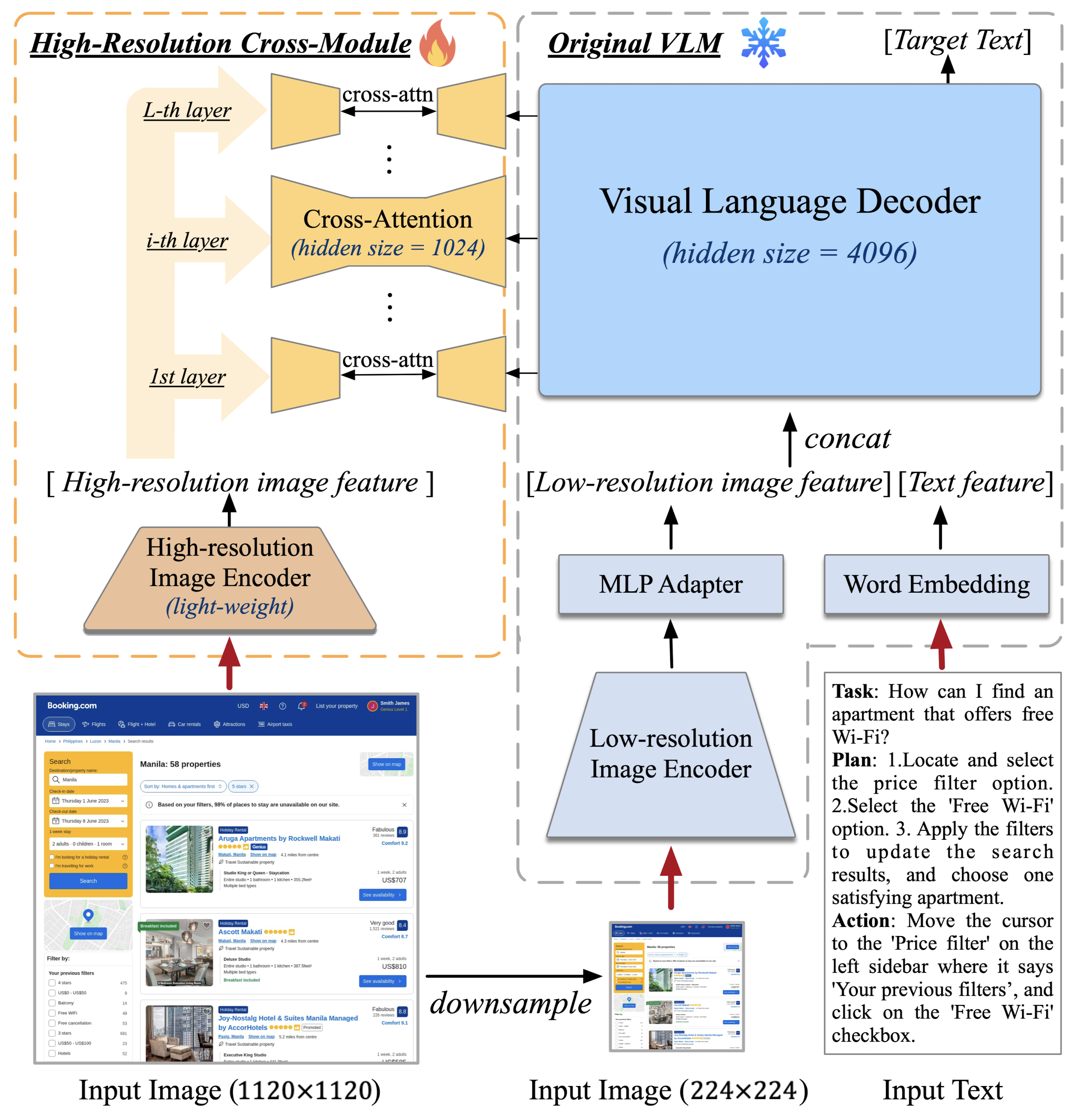
2.1. Architecture
- 사전 학습된 VLM, CogVLM-17B 모델을 사용합니다. (이미지에서 우측에 해당)
- 이 모델의 입력은 low-resolution이고 EVA2-CLIP-E를 encoder로 사용합니다. (224 x 224)
- 이 encoder를 통해 나온 벡터를 MLP Adapter에 통과시켜 VLM의 decoder의 feature space에 mapping 해줍니다.
- 이때 PLM의 decoder는 4096의 hidden size를 가지며, low-resolution 이미지로부터 획득한 벡터를 input text를 embedding한 벡터와 concat한 것을 입력으로 받습니다.
- high-resolution input (1120 x 1120)을 처리하는 모듈에 cross-attention을 추가했습니다. 각 layer마다 포함되어 있습니다.
- backbone 모델인 CogVLM도 마찬가지로 입력 이미지의 사이즈가 커지면 time & memory overhead가 발생하는 문제가 있습니다.
- 위 문제를 해결하기 위해 제시된 것이 cross-attention입니다.
2.2. High-Resolution Cross-Module
- 여기서는 훨씬 경량화된 pre-trained vision encoder를 사용합니다.
- 구체적으로는 EVA2-CLIP-L이며 0.30B 파라미터 사이즈입니다.
- 입력 이미지는 1120 x 1120 / 224 x 224 사이즈로 조정되어 각각 high-resolution cross-module과 low-resolution branch로 뿌려집니다.
- decoder는 decoder의 hidden state(low-resolution 이미지와 text로 부터 얻은)를 high-resolution 이미지로부터 획득한 벡터와 cross-attention하게 됩니다.
- 아래 수식은 decoder 내부의 Multi-head Self Attention (MSA)과 high-resolution encoder와의 Multi-head Cross Attention (MCA)을 나타내고 있습니다.
- $X_{in}$은 low-resolution 이미지로부터의 벡터와 input text로 부터의 embedding 벡터를 결합한 것을 말합니다.
- 둘을 합쳐 획득한 $X^{'}_{i}$와 high-resolution 이미지로부터 획득한 벡터를 cross-attention 한다는 것을 알 수 있습니다.
- 이때 두 식에서 파란색으로 표시한 것은 각각 MSA, MCA의 입력이 연산 결과에 그대로 더해지는 것이므로 residual connection 테크닉이 적용되었다는 것을 알 수 있습니다.
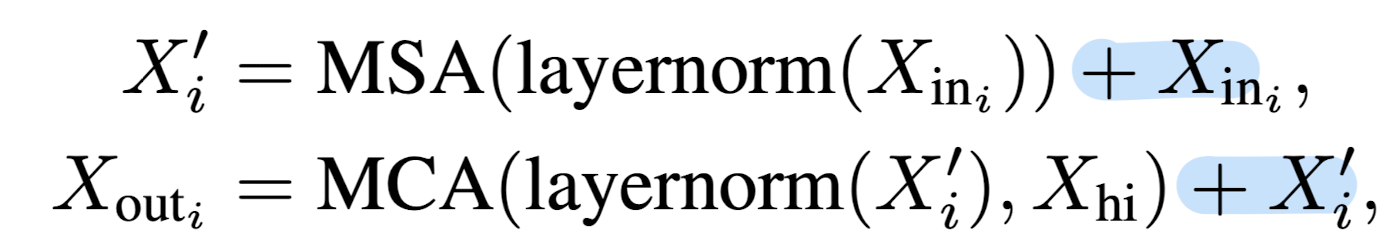
2.3. Pre-training
- Text recognition: 이를 위해서는 다음 총 세 개의 데이터셋이 포함되었습니다.
- Synthetic rendering with text from language pre-training dataset (80M)
- Optical Character Recognition (OCR) of natural images (18M)
- Academic documents (9M)
- Visual grounding
- 이미지 내의 다양한 요소들을 이해하고 위치를 파악하는 것이 GUI agent에게는 중요한 능력입니다. 이를 위해서 다양한 ground data를 pre-training 단계에 포함시켰습니다.
- 이미지 내 요소들의 위치는 [[x0, y0, x1, y1]]로 표현되고 (x0, y0), (x1, y1)은 각각 좌상단/우하단 좌표를 나타냅니다. 이 값은 [000, 999]로 normalized 되어 있습니다.
- GUI imagery: 두 개의 새로운 GUI grounding tasks를 도입했습니다.
- GUI Referring Expression Generation (REG)
- GUI Referring Expression Comprehension (REC)
- 많은 양의 데이터가 사용되었지만, 특히 publicly available text-image dataset 또한 포함되었습니다.
2.4. Multi-task Fine-tuning and Alignment
- 모델의 성능을 높이기 위해서는 다양한 태스크에 대해 학습되어야 하고, GUI 환경에서 주어지는 다양한 유저의 지시를 잘 따를 수 있어야 합니다.
- 연구진들은 이를 위해 핸드폰과 컴퓨터에서 약 2,000여 장에 달하는 스크린샷을 수집하고 구성 요소와 태스크에 대해 직접 annotate 했습니다.
- Mind2Web, AITW 데이터셋도 활용했습니다.
- 추가로 publicly available한 VQA 데이터셋도 활용했다고 합니다.
3. Experiments
3.1. Foundational Visual Understanding
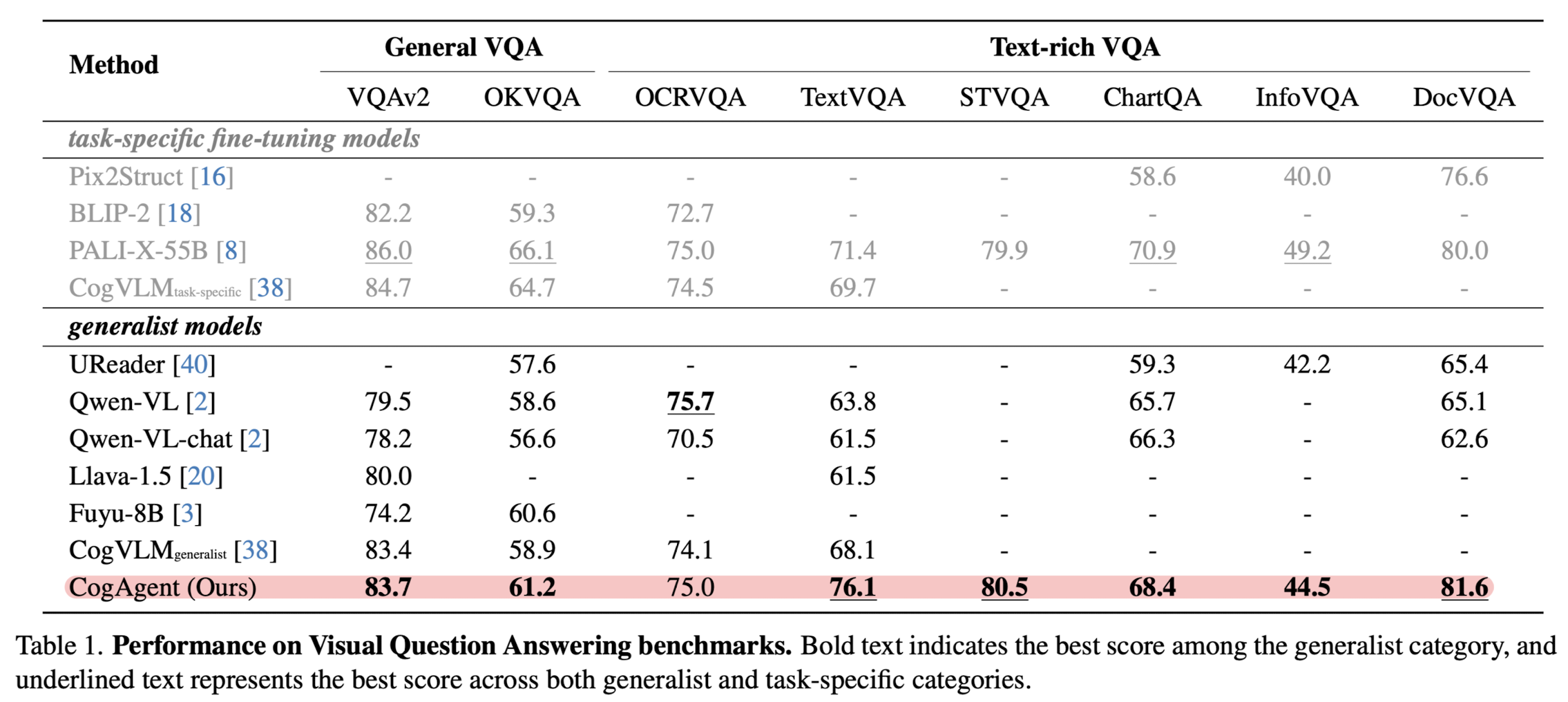
- 8개의 VQA 벤치마크에 대한 성능을 확인합니다. 굉장히 뛰어난 성능을 보인다는 것이 확인됩니다.
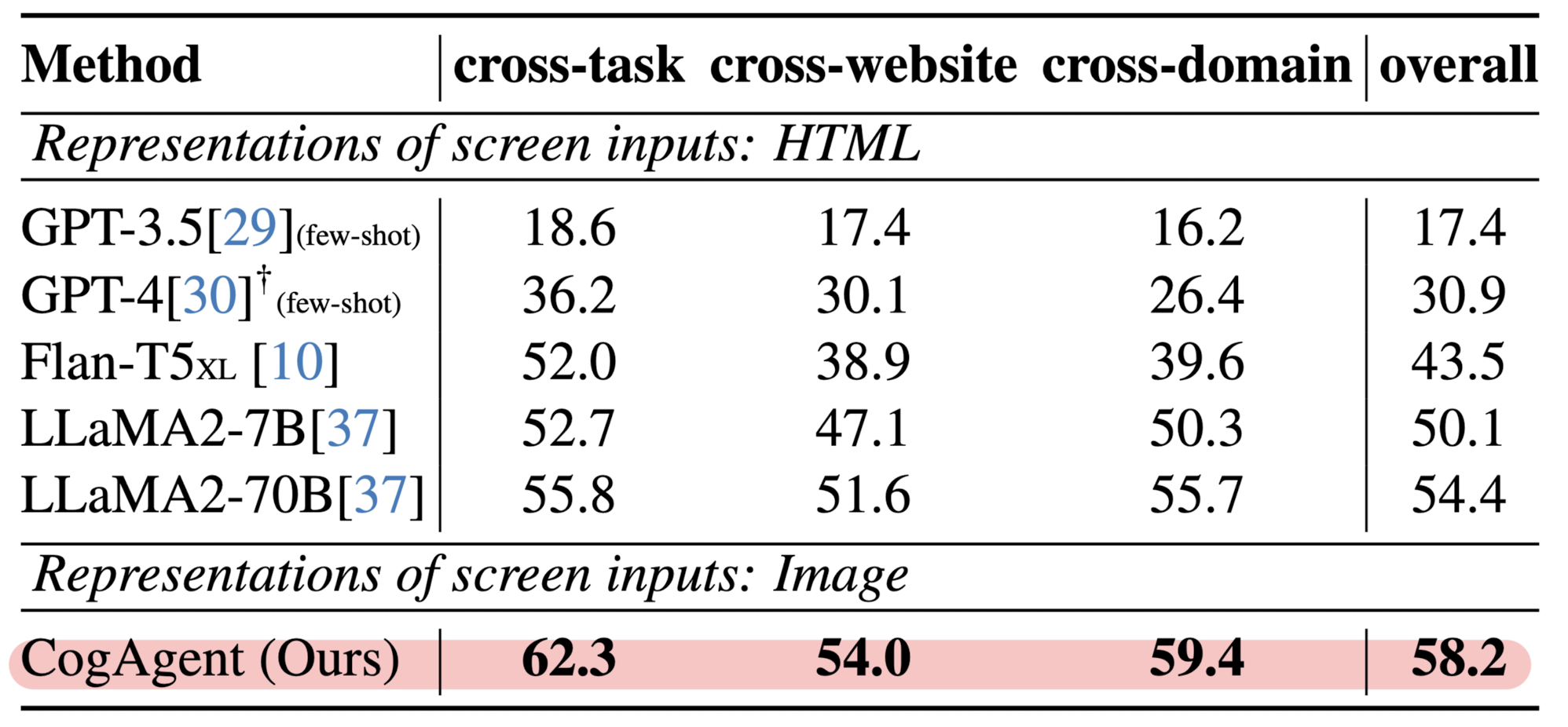
3.2. GUI Agent: Computer Interface
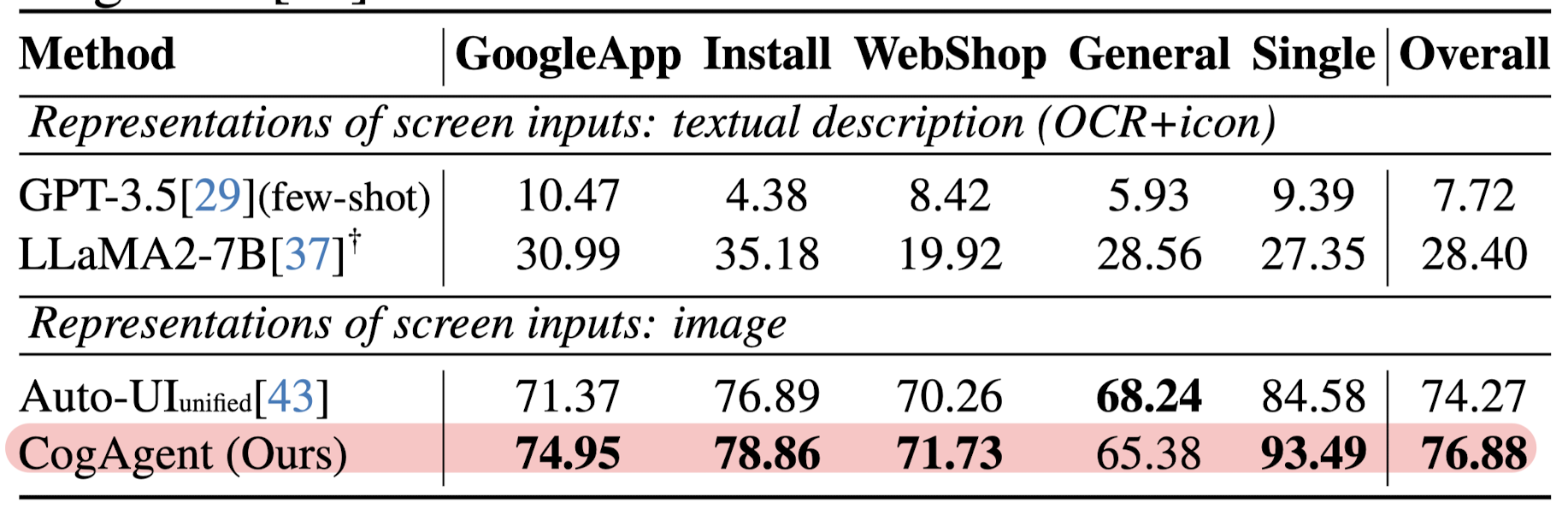
3.3. GUI Agent: Smartphone Interface
4. Ablation Study
4.1. Model Architecture
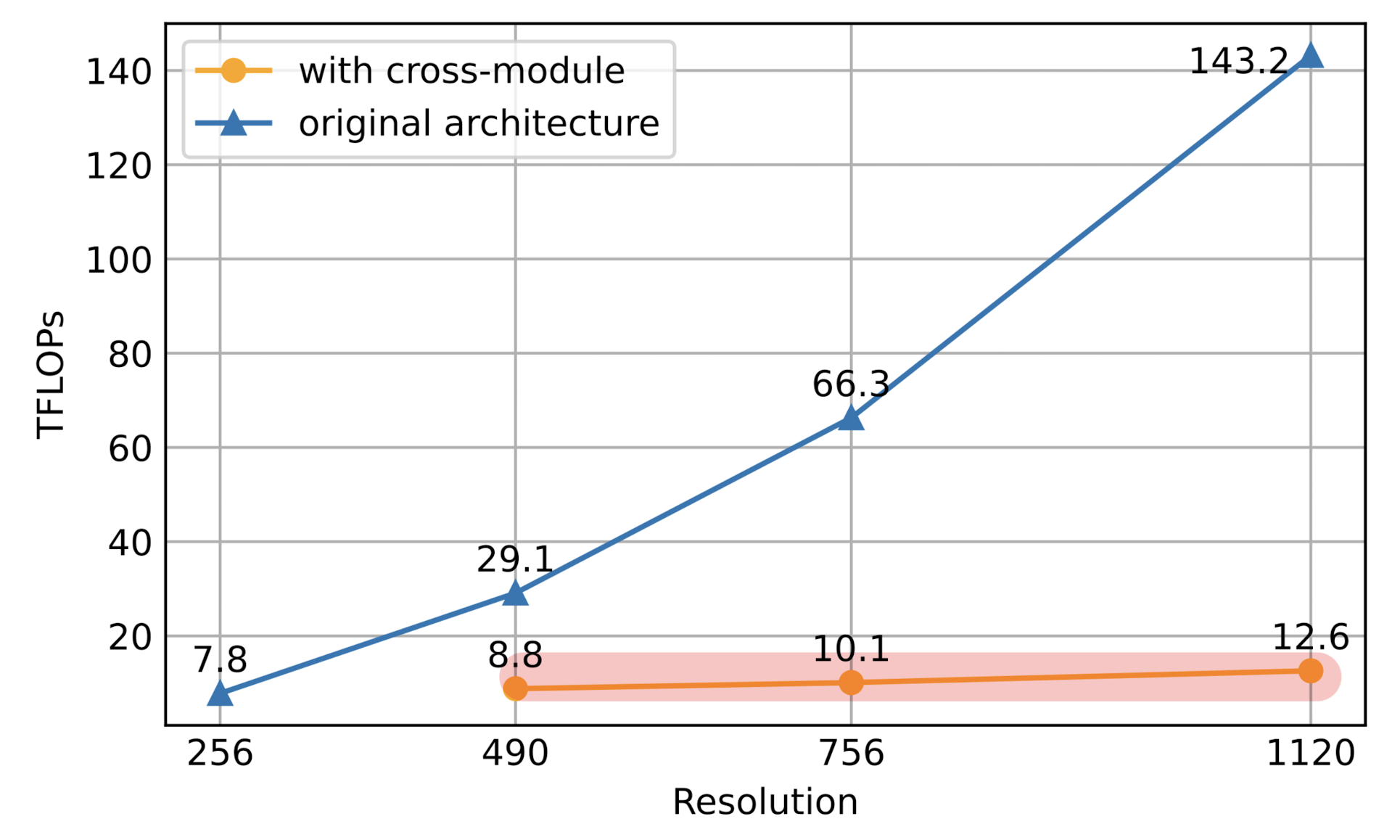
- 고해상도의 이미지를 처리할 때, cross-module을 사용하는 것과 그렇지 않은 것의 연산량을 FLOPs로 비교한 결과입니다.
- 사용한 경우가 빨간색으로 덧칠되어 있는데 1120 해상도 이미지를 처리하더라도 총 연산량에 큰 변화가 없음을 알 수 있습니다.
4.2. Pre-train Data
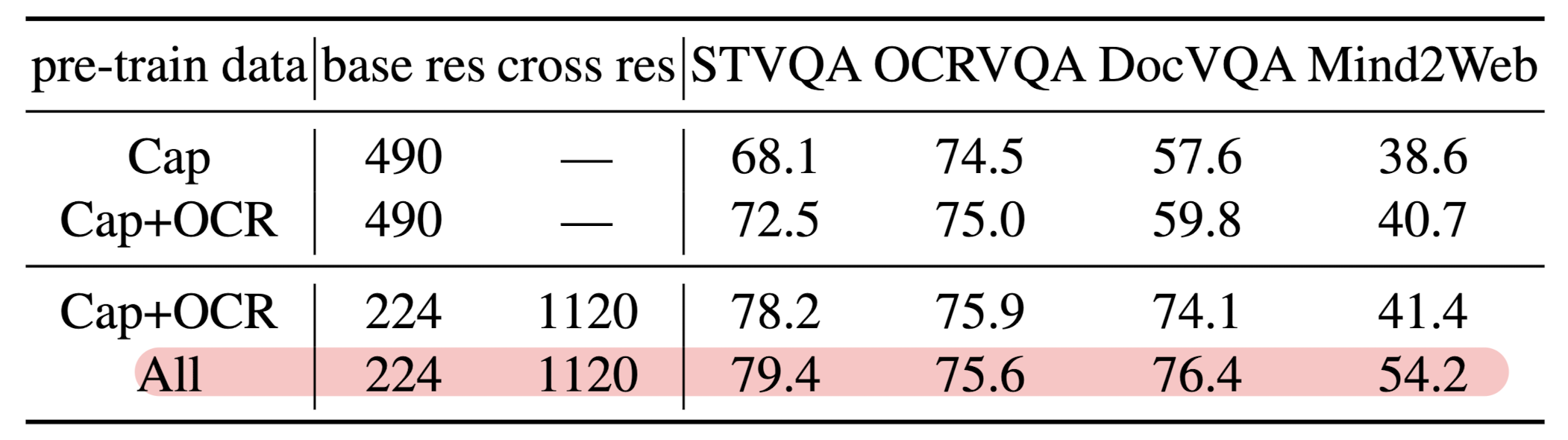
- 사전 학습에 사용된 데이터들의 영향력을 평가하는 실험입니다.
- 데이터셋을 모두 활용할 때까지 성능이 고른 형태로 scaling up 되고 있다는 것을 알 수 있습니다.
- 이때의 벤치마크는 VQA와 GUI-Web 입니다.
5. Insights
저는 이러한 agent 관련 연구들이 앞으로 AI가 산업과 일상에서 가장 많이 활용될 분야에 관한 것이라는 인상이 있어서, 가장 high-level의 접근 방법들이 필요한 영역이라서 재밌게 보고 있습니다.
두 개의 image encoder를 활용하고 이에 대한 feature selection 결과를 cross attention 한다는 것이 재밌는 포인트였던 것 같습니다.
항상 VQA 관련된 모델들이 왜 작동이 잘 되는가에 대한 의문이 있는데 이것 역시 그런 느낌은 있긴 한 것 같고요 ㅋㅋㅋ..
다만 하나의 이미지를 두 개의 사이즈로 resize하여 독립적으로 처리한 뒤 결과를 합치는 것이 어떤 논리적인 근거를 갖는지에 대해서는 전혀 납득이 되지 않습니다.
고해상도 이미지를 패치 단위로 나눠서 이걸 독립적으로 처리한 결과랑 합치면 지엽적인 것과 전체적인 것을 함께 살펴보는 메커니즘이 될 수도 있을 것 같은데(연산 효율이 많이 떨어지겠지만 cross attention을 적용함으로써 이미 꽤나 연산 효율을 벌어들였으니..?) 지금의 방식이 타당한 게 맞는지는 잘 모르겠습니다.
출처 : https://arxiv.org/abs/2312.08914
CogAgent: A Visual Language Model for GUI Agents
People are spending an enormous amount of time on digital devices through graphical user interfaces (GUIs), e.g., computer or smartphone screens. Large language models (LLMs) such as ChatGPT can assist people in tasks like writing emails, but struggle to u
arxiv.org