<Uncertainty> I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token (2024.12) (NeurIPS 2024)
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[HPI]
- [IDK] 라는 스페셜 토큰을 모델 vocab에 추가
- 잘못된 예측에 대한 probability mass를 스페셜 토큰으로 옮겨주는 objective function 도입
- 큰 사이즈의 corpus에 대해 objective function 교체 후 self-supervised learning (pre-training) 적용

출처 : https://arxiv.org/abs/2412.06676
1. Introduction
LLM은 뛰어나지만 아직까지도 hallucination 문제가 해결되지 않고 있죠.
이제는 LLM에게서 이러한 문제점이 나타난다는 것을 잘 알고 있기 때문에 큰 위화감조차 없지만..
많은 상황들에서는 LLM의 이러한 불확실성 때문에 LLM의 활용을 기피하거나, 이를 해결하고자 하는 시도들이 있어왔습니다.
예를 들어 금융쪽에서 LLM을 활용한다고 했을 때, 거래 규모가 큰 건에 대해 발생하는 hallucination을 탐지하기 못하게 되는 경우 기대되는 손실액이 너무 커질 수 있다는 걸 생각해 볼 수 있겠죠..
개인적으로는 이러한 문제 발생의 원인이 거의 해결하기 어려운 것에 가깝고 (확률적 모델의 특성이니까..),
사람이 직접 처리하거나 다른 솔루션을 도입하면 100퍼센트 해결 가능하냐는 것도 당연히 아니라고 답할 수밖에 없어서 아주 까다로운 문제라고 인식하고 있습니다.
어쨌든 최근에는 모델의 이러한 불확실성을 최소화하기 위해 callibration 컨셉의 연구도 꽤 이뤄지고 있는 것 같습니다.
본 연구에서는 흥미롭게도 [IDK] 라는 스페셜 토큰을 추가하고, 확실하지 않은 정보에 대해서는 다음에 등장할 토큰으로 해당 스페셜 토큰을 예측하게끔 학습을 유도함으로써 문제를 해결하고자 합니다.
컨셉은 생각보다 엄청 간단한 것 같고..
그런데도 이러한 논문이 이제야 accepted 된 것은 실제로 의미 있는 결과 (수치적으로, 수식적으로)를 도출해 내기가 어렵다는 뜻인 것 같기도 합니다.
2. IDK-tuning
2.1. The [IDK] token
이 토큰을 추가하는 이유는 모델의 '지식 부족(불확실성)'을 표현(represent)하기 위함입니다.
대부분의 hallucination은 모델이 관련 지식이 부족함에도 불구하고 다음에 등장할 토큰을 어떻게든 예측하는 과정이 반복됨으로 인해 발생하는 것이기 때문이므로..
어떻게든 다음 토큰을 예측할 수밖에 없는 모델이 '불확실성을 나타내는 토큰'을 예측 및 생성하도록 유도하는 것이 목적이 되겠습니다.
예를 들어 '프랑스의 수도는' 이라는 입력이 주어졌을 때 다음으로는 '파리이다'가 와야 할 것입니다.
그런데 이때 '서울이다'라는 말로 잘못 예측이 되었다면, 모델의 입장에서는 이 내용에 대해 지식이 부족한, 즉 불확실성이 높은 상황이라고 이해할 수 있을 것입니다.
그렇다면 모델이 '서울이다'라고 예측할 확률 (질량)을 '[IDK]' 라는 스페셜 토큰으로 옮겨줌으로써 모델의 불확실성에 대한 표현력을 높일 수 있다고 보는 것이죠.
2.2. The IDK Training Objective
위 컨셉을 구체화하는 데에는 Uncertainty Factor라는 개념이 사용되고 $\lambda$로 표기됩니다.
식은 이렇습니다.
$$ \lambda = \Pi \times \left ( 1 - \frac{\text {prob}y_t = \left[ \text{gold}\right] | y_{<t}, x}{\text{max}_i \left( \text{prob} \left(y_t=i|y_{<t},x\right)\right)} \right)$$
이는 기존 Cross Entropy를 대체하는 새로운 objective 수식에 반영되는 factor이고, 전체 수식은 아래와 같습니다.
$$L_{\text{IDK}} = L_{\text{CE}} \left(\hat{y}, (1-\lambda)y + \lambda1_{\left[\text{IDK}\right]} \right)$$
내용을 하나씩 살펴보겠습니다.
우선 objective를 보면 $\hat{y}$과 $(1-\lambda)y + \lambda1_{\left[\text{IDK}\right]}$의 Cross Entropy가 됩니다.
기존의 CE라면 단순히 $y$와 비교하게 되겠지만, 여기서는 $\lambda$를 이용하여 $y$에 대한 예측 정확도 signal과 불확실성에 대한 signal $1_{\left[\text{IDK}\right]}$ 를 비교 요소에 포함하고 있습니다.
$\lambda$를 전체적으로 살펴보면 값의 범위가 최소 0에서 최대 1이 될 수 있도록 설계되어 있습니다.
($\Pi \in \left[ 0,1\right]$ 범위의 하이퍼 파라미터입니다)
분모는 입력이 주어졌을 때 등장할 확률이 가장 높은 토큰의 확률이 얼마인지를 구하고 있고, (각 토큰의 확률 질량-probability mass- 중 최댓값)
분자는 입력이 주어졌을 때 정답 토큰이 등장할 확률이 얼마인지를 구하고 있습니다. (gold token에 대한 확률 질량)
즉, 모델이 다음으로 등장할 것으로 예측한 토큰이 실제 정답이라면 분수 전체는 1이 될 것이고 괄호 안 계산 결과는 0이 됩니다.
따라서 $\lambda$ 전체가 0이 됩니다.
반대로 모델이 정답을 예측할 확률이 다른 최대 확률 질량을 갖는 토큰에 비해 작다면(불확실하다면) 분수값이 0에 가까워지면서 $\lambda$값 자체는 1에 가깝게 됩니다.
정리하면 $\lambda$값은
1) 모델이 정답을 잘 예측할수록(확실할수록) 0에 수렴
2) 모델이 정답을 잘 예측하지 못할수록(불확실할수록) 1에 수렴
하게 된다는 뜻입니다.
그러면 이 $\lambda$와 직접적으로 곱해지게 되는 1_{\left[\text{IDK}\right]}는 무엇일까요?
이는 [IDK] 토큰의 인덱스의 값은 1, 나머지는 0의 값을 갖는 one-hot vector 입니다.
[IDK] 토큰에 대해서만 cross entropy값을 구하고 불확실한 정도를 $\lambda$값으로 구하여 sacling 한다는 뜻이고, 나머지 가중치만큼은 기존 정답 토큰에 대한 cross entropy를 구하여 둘을 합산하는 식이 되겠습니다.
그런데 저자는 이 새로운 objective를 적용할 때, 모델이 너무 많은 false positive [IDK]를 예측하게 될 상황을 우려합니다.
이를 방지하기 위해 uncertainty regularization을 적용하는데 이에 대한 수식은 이렇습니다.
$$L_{\text{FP-reg}} = -\log \left( 1 - prob \left(y_t = [\text{IDK}]|y_{<t}, x \right) \right)$$
$$\mathcal{L} =
\begin{cases}
\mathcal{L}_{\text{CE}} + \mathcal{L}_{\text{FP-reg}} & \text{if } \lambda = 0 \\
\mathcal{L}_{\text{IDK}} & \text{otherwise.}
\end{cases}$$
$\lambda$가 0일 때, 즉 모델이 정답 토큰을 정확하게 예측하고 있을 때만 해당 term을 original CE에 추가 적용하는 것을 알 수 있습니다.
의미를 살펴보면 입력이 주어졌을 때, [IDK] 토큰을 예측할 확률을 1에서 제외하고, 이를 음의 로그에 적용한 값이 됩니다.
이 식에서 음의 로그에 입력으로 주어지는 값은 0에서 1 사이가 되고, 0에서 1 사이의 값을 음의 로그에 적용하게 되면 무한대부터 0에 수렴하는 출력 범위를 갖게 됩니다.

음의 log의 입력으로 주어지는 값은 [IDK]에 대한 예측 확률이 높을수록 0에 가까워지고 (1에서 1을 빼는 것일 테므로), 반대로 [IDK]를 예측할 확률이 낮을수록 1에 가까워집니다 (그대로 보존되므로)
결과적으로 음의 로그 결과값은 [IDK] 예측 확률이 높을수록 무한대로 커지고, [IDK] 예측 확률이 낮을수록 0에 수렴하게 됩니다.
즉, 모델의 불확실성이 클수록 강하게 부정적인 signal을 보내는 셈이 됩니다. (Loss 값 전체가 커지므로)
근데 이는 모델이 정답 토큰을 정확하게 예측하여 $\lambda$의 값이 0일 때만 적용하는 regularization term이라고 했습니다.
이 term은 모델의 불확실성이 클수록 높은 패널티를 부여하는데, 정답일 때만 부여한다는 뜻입니다.
왜냐하면 모델이 정답을 잘 예측했는데 [IDK] 토큰에 대한 확률 질량을 갖는다는 건 불확실성을 내포하고 있다는 뜻이기 때문입니다.
만약 이런 패널티가 없다면 정답을 잘 맞혔더라도 [IDK]에 큰 확률 질량을 부여할 수도 있습니다.
가상의 시나리오를 생각해 보면 이렇습니다.
후보 토큰 A, B, [IDK] 세 개가 있고, 각각에 대한 현시점의 예측 확률이 0.5, 0.2, 0.3 입니다.
이때 실제 정답 토큰은 A 입니다.
이때 $\lambda$값을 계산하면 $\Pi=\frac {1} {2}$에 $(1 - \frac {0.5} {0.5})=0$ 을 곱하게 되어 0이 됩니다. ($\Pi$는 하이퍼파라미터라고 위에서 밝혔습니다)
그런데 모델이 정답을 잘 예측했음에도 불구하고 불확실 토큰이 전체 확률 질량의 30퍼센트나 차지하게 되죠.
이를 줄이지 않게 된다면 실제로 다른 토큰을 예측할 확률과 해당 스페셜 토큰을 예측할 확률이 비슷하거나 후자가 더 큰 경우가 꽤나 많이 등장하게 될 것입니다.
그러면 False Positive, 실제로는 [IDK] 가 아닌데 [IDK] 로 잘못 예측하는 케이스가 굉장히 빈번해질 것입니다.
단순하게 생각해 봐도 vocab 내에는 굉장히 여러 개의 토큰이 존재하는데, 몇 만 개 이상 되는 후보와 한 개의 스페셜 토큰을 비교하게 되면 후자에 쏠리는 현상이 쉽게 발생할 수 있음을 생각해 볼 수 있습니다.
(묻고 따지지도 않고 [IDK]로 예측해도 손해볼 게 없으므로)
3. Experiments
3.1. IDK-tuning Setup
상세한 세팅이 궁금하시다면 논문을 직접 참고하시길 바라고..
조금 특이한 점은 베이스라인으로 가져가는 모델 종류인데요,
- bert-base-cased
- mistralai/Mistral-7B-v0.1
- EleutherAI/pythia-70m-2.8B
세 개의 모델을 사용했다고 합니다.
3.2. Evaluation Setup
Benchmarks
- subject-relation-object facts
- LAMA, PopQA
- trivia questions
- TriviaQA
- multiple choice question answering (lm-evaluation-harness)
- ARC, HellaSwag, MMLU, TruthfulQA, WinoGrande, GSM8K
이때 TriviaQA, PopQA에 대해서는 질문을 문장 형식으로 변형하기 위해 GPT-4 모델을 사용했다고 합니다.
Methodologies
IDK-tuning과 비교할 baseline은 아래와 같습니다.
- confidence-based baseline: predicted probability mass를 활용
- P(True) baseline: "Please answer either with 'true' or 'false' only"
- Semantic Entropy baseline: SoTA semantic encoder를 활용하여 K개의 generated text를 인코딩
Metrics
Metric으로는 위 태스크들에 맞는 Precision, Recall, F1을 사용하는데요,
IDK-tuning 성능을 제대로 측정하기 위한 IDK recall 과 IDK error rate를 정의하여 비교한 결과도 함께 제시하게 됩니다.
- IDK recall: base 모델이 정답을 예측하지 못한 상황에서, 학습된 모델은 [IDK]를 제대로 반환한 케이스
- IDK error rate: base 모델은 정답을 맞혔는데, 학습된 모델이 [IDK]로 잘못 반환한 케이스
4. Results
4.1. Main Results


Mistral-7B-v0.1 모델의 경우, LAMA, TriviaQA, PopQA에 대해서(Table 1), 그리고 MCQA에 대해서(Table 2) 성능 저하 없이 정답에 대한 확신도만 높아진 결과를 보여줍니다.
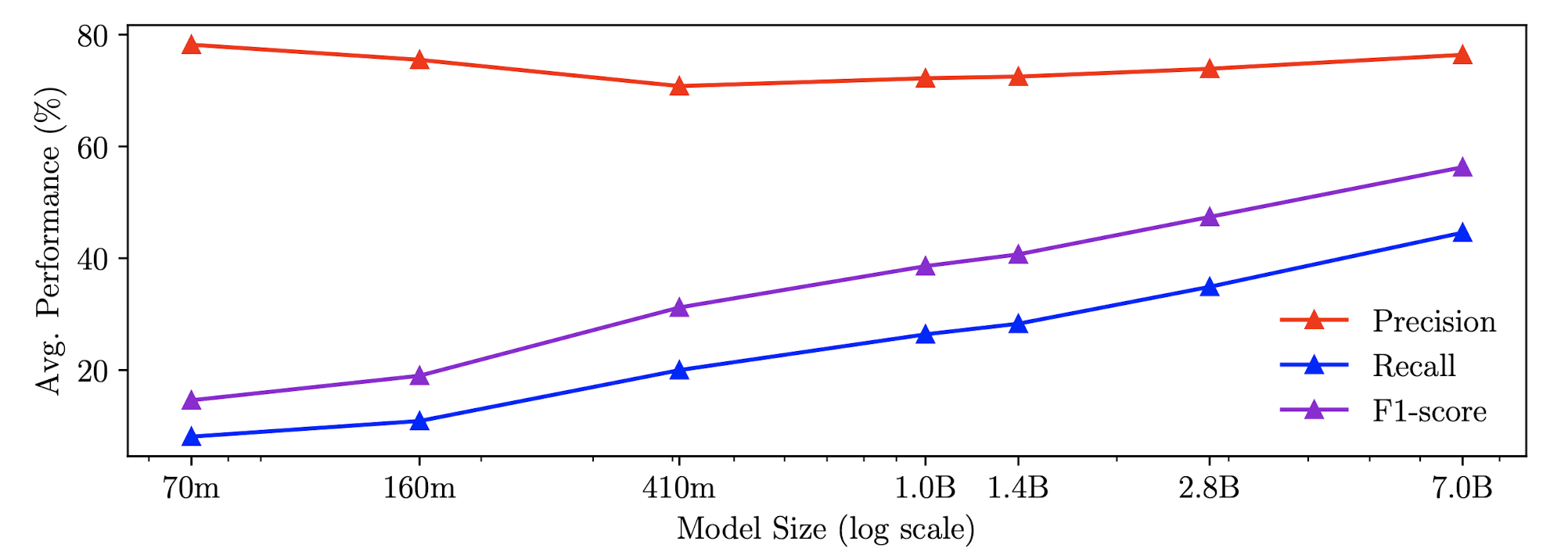
모델의 사이즈와 recall & F1-score 사이에 log-linearly 관계가 명확히 나타나는 것을 관측할 수 있습니다.
빨간색으로 표시된 precision에는 변화가 없지만, 각각 파란색과 보라색으로 표시된 recall, F1-score는 모델 사이즈에 비례하여 우상향 하고 있습니다.
위 실험 결과는 closed-book factual sentence completion benchmark 로부터 획득한 것입니다.

bert 모델은 조금 다른 양상을 보입니다.
Precision이 큰 폭으로 향상되었고, Recall은 (상대적으로) 소폭 하락했습니다.
저자는 이를 Factuality의 개선으로 설명하는데, 위와 상반되는 이 결과에 대한 해석/분석을 제시하지는 않았습니다.
4.2. Ablations
- Adaptive nature of the Uncertainty Factor $\lambda$
- adaptive $\lambda$ formulation을 사용하는 것이 더 낮은 IDK error rate 로 이어짐. IDK recall 은 소폭 하락.
- Effect of the $L_{\text{FP-reg}}$ regularization
- regularization을 적용하는 것이 더 낮은 IDK error rate로 이어짐. IDK recall은 소폭 하락.
- Effect of the upper bound hyperparameter $\Pi$
- 이 값을 늘릴수록 [IDK]로 예측할 때의 정확도는 향상. 그러나 IDK error rate도 함께 상승한다는 문제점.
- 적절한 trade-off가 필요
- Effect of knowledge contained in The Pile
- 사전학습으로 사용되는 The Pile 데이터셋의 영향이 있을 수 있는지에 대해 확인
- Mistral 모델로 확인한 결과, 기존 objective를 갖고 학습하는 것과 대체로 큰 차이가 없었음
4.3. Analysis of Optimization Stability
Collapse to [IDK]
cross-entropy를 단순 대체하는 경우 training collapse가 우려되므로, 이에 대한 대책으로 하이퍼파라미터 $\Pi$와 regularization term을 추가했음을 위에서 설명했습니다.
저자의 설명에 따르면 확실히 $\Pi=0.5$로 설정하고, regularization term을 사용하는 것이 도움이 된다고 합니다.
Collapse for small models pythia-70m and pythia-160m
사이즈가 너무 작은 모델들은 이러한 collapse 현상이 더욱 쉽게 관측되는 것 같습니다.
구체적으로는 predicted distributions이 uniform distribution으로 collapse 된다고 합니다. (최악의 경우에는 0%의 정확도)
이는 작은 모델들이 [IDK] 토큰에 대해 갖는 probability mass가 너무 작은 까닭입니다.
이것이 곧 $L_{\text{IDK}}$ loss를 너무 크게 만들어 비정상적인 graident norm으로 이어지고 학습이 제대로 이뤄지지 않게 되는 것이죠.
그나마 학습이 조금이라도 제대로 되는 경우에 속하는 pythia-410m 모델의 경우에도 [IDK] 토큰에 대한 초기 확률 질량이 $5 \times 10^-9$ 수준이라는 점을 참고할 만합니다.
4.4. Text Generation

요약 태스크에 대한 RougeL score를 기록한 표입니다.
IDK-tuning을 적용했을 때, 생성형 모델로 가장 많이 수행하는 태스크에서 성능 하락이 없다는 점은 꽤나 고무적으로 느껴집니다.
그러나 더 다양한 생성형 태스크에서의 성능을 비교해 주면 좋았을 것 같습니다.
게다가 요즘은 요약 성능을 이런 식으로 잘 평가하지도 않는데 의심스러운 표 구성입니다.
4.5. Error Analysis
저자들은 각 데이터셋으로부터 40개씩 sampling 하여 총 200개의 random sample에 대한 정성적 분석을 수행했습니다.
그리고 에러 유형을 다음과 같이 네 개로 구분합니다.
- No Effect
- original & tuned 모델 둘 다 틀린 답을 생성
- Noise
- original 모델은 올바른 답변을, tuned 모델은 틀린 답변을 생성
- White Noise
- original & tuned 모델 둘 다 틀린 답변을 생성. tuned 모델이 기존과 다른 답변을 생성
- Abstain
- tuned 모델이 "unknown" 또는 "mystery"와 같은 텍스트로 답변을 삼가는 경우

위 결과를 심플하게 정리하면 이렇습니다.
- 모델이 클수록 모델 생성 결과의 변화가 적다 (강건하다)
- 모델이 클수록 답변을 삼가는 능력의 향상된다
5. Conlusion & Limitations
본 논문에서는 모델이 확실하지 않은 내용에 대해 hallucination을 일으키지 않도록 새로운 pre-training 기법을 제시했습니다.
방법론 자체는 [IDK] 라는 스페셜 토큰을 vocab에 추가한 뒤 large corpus에 대해 self-supervised tuning을 수행하는 것으로 꽤나 단순합니다.
다만 모델이 이 학습 과정에서 collapse 되는 것을 방지하기 위한 하이퍼파라미터 조정과 regularization term을 추가한 것이 꽤나 중요한 포인트라고 볼 수 있겠습니다.
그런데 이 방식은 결국 사전학습과 동일한 것으로 엄청난 양의 자원을 필요로 한다는 문제점이 있습니다.
논문에서도 최대 7B 사이즈의 모델로 심플하게 실험해 보고 결과를 제시한 이유가 자원 상의 한계 때문일 것으로 예상이 되고요.
데이터의 관점에서도, 요즘에야 물론 활용 가능한 데이터셋도 많지만.. 그건 영어 데이터 기준이라는 점이 가장 문제인 것 같습니다.
대부분 영어 데이터로 학습된 모델에 대해 다른 언어로 IDK-tuning을 수행해도 괜찮을지에 대한 확신이 들지 않네요.
논문의 실험 자체에 대해서만 지적해 보자면 너무 한정적인 태스크로 모델 성능을 평가했다는 생각이 듭니다.
사실 모델이 확실하지 않은 내용을 생성함으로써 문제를 일으키는 건 open-ended question에서 가장 심각한데, 무엇이라도 찍을 수 있는 n지선다 태스크 중심으로 성능 평가를 한 것이 타당한지는 잘 모르겠습니다.
확실치는 않지만 체리피킹 가능성이 좀 높지 않을까 싶고..
개인적으로는 이를 사전학습이 아니라 downtream task에 대해 fine-tuning 하는 단계에서 (혹은 instruction tuning 정도) 적용 가능하다면 굉장히 좋을 것 같다는 생각이 듭니다.
보통 스페셜 토큰에 대한 적절한 임베딩을 갖기 위해서는 꽤 많은 데이터가 필요할 것 같고요.