![]()
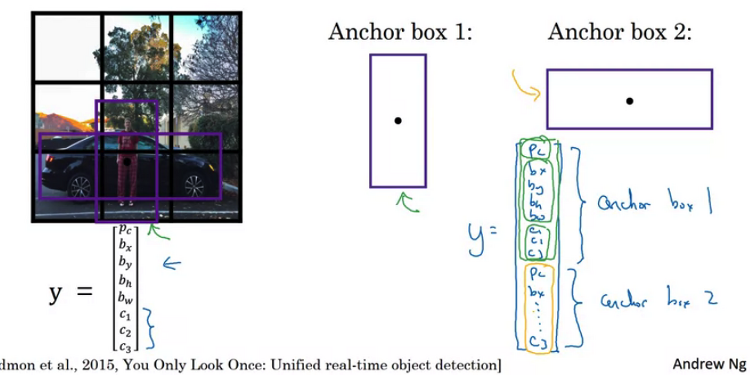
Training 지금까지의 내용을 종합한 YOLO 알고리즘에 대한 예시입니다. 이전 예시와 마찬가지로 anchor box는 두 개이고 class는 세 개이므로 출력 차원은 (3, 3, 16)이 됩니다. 기본적으로 anchor box 한 개는 Pc, x, y, h, w 다섯 개의 정보를 가지고 있습니다. 여기에 클래스의 개수 3을 더하면 각 anchor box는 8차원이 됩니다. 3 x 3 은 이미지를 9개의 cell로 쪼갰기 때문입니다. 실제로는 19 x 19 라고 이전 강의에서 언급되었습니다. Making predictions 이전 내용을 기억하실지 모르겠습니다만, Pc=0인 경우 bounding box나 class에 대한 결과는 무시됩니다. don't care라는 표현을 썼었습니다. 그렇지 않고 Pc..
![]()
Overlapping objects: 만약 위처럼 이미지 내에 물체가 겹치는 경우 Anchor box 개념을 이용할 수 있습니다. 쉽게 말하자면 축이 되는 box를 미리 정해두고 예측 벡터의 차원을 늘리는 것이죠. 위 예시에서는 Anchor box 두 개를 정해뒀습니다. 여기서 각 그리드에서 나온 예측 결과는 두 anchor에 대한 예측을 포함하고 있을 것입니다. 이런 방식으로 여러 물체가 겹쳐 있는 경우에 대해서도 bounding box를 정확히 예측할 수 있도록 유도할 수 있습니다. Anchor box algorithm 따라서 출력 차원은 anchor box의 개수에 비례합니다. 위 예시에서는 2개의 anchor box를 사용하고 있으며 분류하고자 하는 객체의 종류가 세 개이므로 위와 같은 차원으로 ..
![]()
Intersection Over Union Evaluating object localization Intersection over Union(IOU)은 bounding box에 대한 예측이 정확했는지를 확인하는 지표입니다. 예측과 실제 정답이 겹치는 노란 부분 / 예측과 실제 정답의 합 위 분수식을 계산한 결과가 0.5 이상이면 'correct' 판정을 줄 수 있습니다. 이 threshold가 높아지면 높아질수록 더 정확한 예측이 가능할 것입니다. Non-max Suppression Non-max suppression example IOU로 bounding box를 예측하다 보면 위처럼 여러 개가 중첩되어 있을 수 있습니다. 이미지를 여러 개의 grid로 쪼개어 위치를 예측하기 때문이죠. 따라서 예측된 ..
![]()
Output accurate bounding boxes 이전의 sliding window 기법을 적용하면 연산 자체는 효율적이지만 위처럼 ground truth(실제 정답)에 해당하는 bounding box를 구할 수 없다는 문제점이 발생합니다. YOLO algorithm 이 알고리즘은 주어진 이미지를 19 x 19개로 나누고 각 grid마다 label을 부여해서 학습하는 방식입니다. 강의에서는 편의상 9개의 grid로 나누었습니다. 각 label은 [ Pc, bx, by, bh, bw, c1, c2, c3 ] 로 구성됩니다. (8차원의 output) Pc = 0 인 경우 이전과 마찬가지로 나머지 값들은 'don't care'합니다. 결과적으로 target의 output은 (3, 3, 8) 차원을 갖게 ..
![]()
Turning FC layer into convolutional layers 지난 시간까지 알아본 것은 어떻게 이미지 내에서 사물/물체를 탐지할 수 있을까에 대한 것이었습니다. 그런데 한 이미지 내에서 여러 물체를 탐지하기 위해서는 sliding window 기법이 필요했습니다. sliding window 기법은 너무 많은 연산량을 필요로 한다는 문제점이 있었고 이를 해결하기 위해서 FC layer를 Convolutional layer로 바꾸는 기법을 소개하고 있습니다. 모든 노드 간의 연결이 업데이트 되상이 되어 파라미터 수가 굉장히 많은 FC와 달리, Convolutional layer는 필터만 업데이트 대상으로 파라미터 수가 굉장히 적습니다. 따라서 기존에 FC를 거치면서 나오는 출력 형태는 유사하..
![]()
1. Landmark Detection 사람의 얼굴은 여러 가지 특징을 갖고 있습니다. 우리는 이 특징들을 기반으로 윤곽을 잡는 등 인식의 정확도를 높일 수 있죠. 예를 들어 눈의 가장 자리, 코의 가장 자리, 입의 가장 자리 등을 캐치할 수 있습니다. 이를 landmark라고 부릅니다. 이 예시에서는 얼굴이라는 사물에 64개의 landmark가 존재하는 경우를 보고 있습니다. 따라서 출력 차원의 벡터는, '이 사진에 얼굴이 있는지 없는지'와 'x, y' 좌표 64개쌍을 포함합니다. 결과적으로 129 차원이 됩니다. 이와 같은 개념을 사람의 신체 구조를 따는데도 적용할 수 있습니다. 2. Object Detction Car detection example 이번에는 한 이미지 내에서 여러 개의 사물을 탐지..