
Output accurate bounding boxes

- 이전의 sliding window 기법을 적용하면 연산 자체는 효율적이지만 위처럼 ground truth(실제 정답)에 해당하는 bounding box를 구할 수 없다는 문제점이 발생합니다.
YOLO algorithm

- 이 알고리즘은 주어진 이미지를 19 x 19개로 나누고 각 grid마다 label을 부여해서 학습하는 방식입니다.
- 강의에서는 편의상 9개의 grid로 나누었습니다.
- 각 label은 [ Pc, bx, by, bh, bw, c1, c2, c3 ] 로 구성됩니다. (8차원의 output)
- Pc = 0 인 경우 이전과 마찬가지로 나머지 값들은 'don't care'합니다.
- 결과적으로 target의 output은 (3, 3, 8) 차원을 갖게 됩니다. (현재 예시는 3 x 3으로 쪼갰으므로)
- 그러면 각 그리드에 물체가 존재하는지/존재하지 않는지, 그리고 존재한다면 그 위치는 어떻게 되는지, 존재하는 물체는 무엇인지를 함께 파악할 수 있게 됩니다.
- 같은 연산을 여러 번 반복하지 않아도 되므로 연산의 효율성도 굉장히 좋습니다.
Specify the bounding boxes
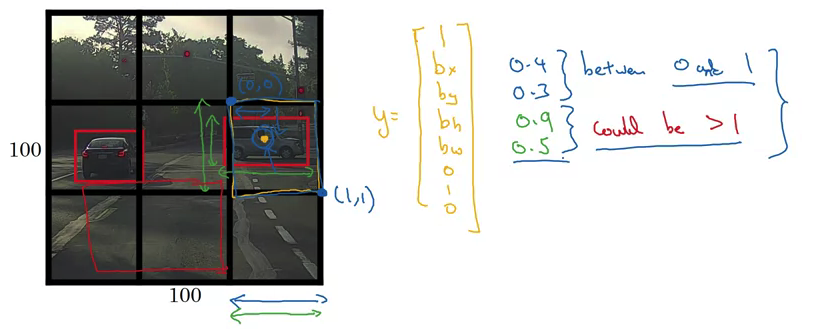
target vector의 구성 성분 중 bounding box에 대해 자세히 살펴봅니다.
- bounding box의 중간 좌표를 나타내는 bx, by 는 0에서 1사이의 값입니다.
bx의 경우 왼쪽에서 멀리 떨어질수록, by의 경우 위에서 멀리 떨어질수록 큰 값을 갖습니다. - 반면 bounding box의 높이와 폭을 나타내는 bh, bw는 1보다 큰 값을 가질 수 있습니다.
예시 이미지에는 없지만 여러 개의 grid에 걸쳐 bounding box가 존재하는 경우, 그 값은 1을 초과하는 것이 당연합니다. - 이 내용은 YOLO 논문에 제시된 convention을 따르는 것이라고 합니다.
출처: Coursera, Convolutional Neural Networks, DeepLearning.AI
'Convolutional Neural Networks > 3주차' 카테고리의 다른 글
| Anchor Boxes (0) | 2023.03.31 |
|---|---|
| Intersection Over Union, Non-max Suppression (0) | 2023.03.31 |
| Convolutional Implementation of Sliding Windows (0) | 2023.03.30 |
| Landmark / Object Detection (0) | 2023.03.30 |
| Object Localization (0) | 2023.03.30 |