1. Deep Learning Frameworks 이 강의가 제작되던 시기에도 이미 딥러닝 분야에서 활용할 수 있는 다양한 프레임워크들이 존재했다. 어떤 프레임워크를 사용할 것인지는 사용자의 선호에 따라 달라질 수 있다. 하지만 현재 오픈 소스인 것이 이후에는 어떤 이유에 의해서든지 아니게 될 수가 있으므로 장기적으로는(개인의 관점은 아닌듯하다) 어떤 프레임워크를 선택할 것인지에 대해 보다 신중한 판단이 요구된다. 2. TensorFlow Motivating problem Cost Function이 위와 같다고 했을 때 TensorFlow를 사용하면 W와 b를 간편하게 구할 수 있다. import numpy as np import tensorflow as tf w = tf.Variable(0, dtype..
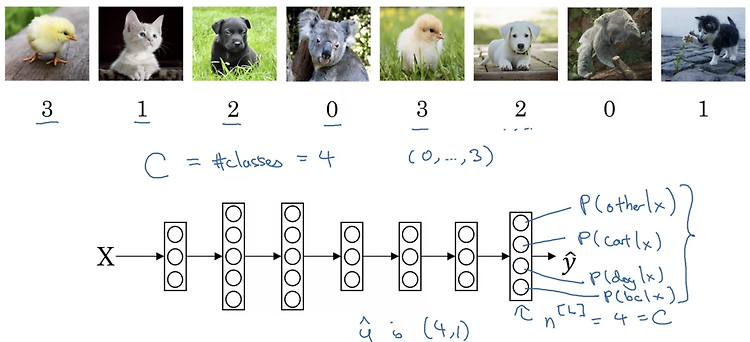
1. Softmax Regression Recognizing cats, dogs, and baby chicks 이전에 다룬 내용은 두 개의 class로 분류하는 것이었습니다. 이를 테면 고양이인지 아닌지를 구분하는 binary classification이라고 할 수 있습니다. 이번에는 두 개의 class가 아닌 여러 개의 class로 구분하는 상황을 가정해보겠습니다. 위 예시에서는 cat, dog, chick, others로 구분합니다. 따라서 neural network의 output layer는 [4,1]의 shape을 갖게 되고 이 벡터는 입력 x가 주어졌을 때 각 class에 해당될 확률을 뜻하게 됩니다. Softmax layer 여러 개의 class가 존재할 때 이를 분류하는 학습을 하는 netw..
1. Normalizing Activation in a Network Normalizing inputs to speed up learning gradient descent 과정에서 빠르게 local minima에 도달하는데 normalization이 도움이 된다는 것은 이전에 배웠다. 그렇다면 neural network에서, 즉 hidden layer가 여러 개인 경우에는 normalization을 언제언제 적용해야 할까? 다시 말하자면 input만 normalization을 해야할까? 아니면 activation function을 통해 나온 결과값에도 적용을 해야할까? 교수님은 둘 다 하는 것을 default로 생각하라고 하셨다. activation function의 결과가 어떻게 나올지는 확실히 예측할..
1. Optimization Algorithms (Quiz) minibatch, layer, example에 대한 notation 각각 { }, [ ], ( ) 기호를 사용한다. vectorization Batch gradient descent는 한꺼번에 모든 데이터를 묶어 학습하겠다는 것이다. 따라서 memory의 문제만 없다면 vectorization을 가장 많이 수행하는 학습법일 것이다. 그러나 batch gradient descent는 progress를 진행하기 전에 전체 training set을 처리해야 한다는 문제점이 있다. 한편 stochastic gradient descent는 여러 example을 vectorization 할 수 없다는 단점이 있다. iteration - cost(J) g..
1. Learning Rate Decay Learning Rate Decay 일반적인 mini-batch를 이용하면 파란색과 같은 그래프가 그려진다. 즉, 어느 정도의 noise를 포함한 형태이면서 절대 global minimum에 convergence(수렴)하지 못하고 주변을 배회(wandering)하게 된다. 이를 해결하기 위해 제시된 것이 Learning Rate Decay로 학습이 진행됨에 따라 learning rate을 감소시키는 것을 말한다. 그러면 위 그림에서 초록색과 같은 그래프가 그려진다. 즉, 초반에는 큰 폭으로 학습이 진행되고 이후에는 그 폭을 줄이면서 global minimum에 convergence(수렴)하게 된다. Leraning rate decay epoch는 주어진 데이터를 ..
1. Gradient Descent with Momentum Gradient descent example 빨간 점을 global minimum이라고 본다면 일반적인 Gradient Descent를 수행했을 때는 파란색 그래프와 같은 양상이 나타날 것이다. 우리는 위 아래로 흔들리는 폭을 줄이면서도 보다 큰 보폭으로 global minimum에 접근할 수 있도록 하는 방법을 떠올려볼 수 있다. 대표적인 방식 중 하나가 Momentum이다. 이는 gradient descent를 수행하는 매 step이 독립적인 것이 아니라 현재 step에 이전 step이 영향을 주는 것으로 받아들이는 방식이라고 볼 수 있다. 즉, exponentially weighted averages를 구하는 방식처럼 현재항과 이전항에 가..