![]()
U-Net 위와 같은 모델의 architecture 때문에 U-Net이라는 이름이 붙었다고 하네요. 원래는 의료 분야에 유용할 것이라는 생각이 있었는데, 예상과 달리 computer vision과 같은 분야에서 크게 빛을 발했다고 합니다. Conv, RELU를 실행하면 channel은 증가하고 height와 width는 줄어듭니다. Max Pooling을 실행하면 channel은 그대로지만 height와 width는 줄어듭니다. Trans Conv를 실행하면(파란색 블록) channel은 줄어들지만 height와 width가 증가합니다. 최종 결과는 h x w x n(class)로 input과 동일한 차원을 갖게 됩니다. 출처: Coursera, Convolutional Neural Networks, D..
![]()
Transpose Convolutions 일반적인 Convolution은 filter를 통해 계산하면 그 차원수가 줄어듭니다. 하지만 Transpose Convolution을 적용하면 오히려 차원이 커지는 것을 볼 수 있습니다. 위 예시에서는 2 x 2 input이 3 x 3 필터를 만나 4 x 4가 되었습니다. input은 2x2, filter는 3x3, padding은 1, stride는 2인 예시를 살펴봅시다. 필터의 모든 값은 input의 각 값을 변수로 받아 제곱을 계산합니다. 계산된 제곱은 패딩을 제외한 구역에 더해집니다. 만약 여러 계산이 중첩되는 경우 계산된 값을 더하여 누적하면 됩니다. 패딩에 해당하는 값들은 계산하지 않고 무시합니다. U-Net에서는 이런 방식을 이용하여 이미지를 다시 ..
![]()
Object Detection vs. Semantic Segmentation 각 픽셀이 연결되어 있는지 그렇지 않은지를 구분하는 방식입니다. 특정 분야에서 효용성이 더 좋습니다. Motivation for U-Net 예시에서 볼 수 있는 것처럼 의료 분야에서 어떤 질병이 있는지 없는지를 판단하는데 큰 도움을 줄 수 있습니다. Per-pixel class labels label을 어떻게 설정하는지를 고민해봅시다. 위 이미지에서는 자동차인 부분은 1, 그렇지 않은 부분은 0이 될 것입니다. 만약 건물까지 구분하고 싶다면, 건물을 2로 할당할 수 있습니다. 여기에 도로까지 구분한다면 도로 부분은 3이 될 것입니다. bounding box를 예측할 때와 다르게 학습할 수 있습니다. Deep Learning fo..
![]()
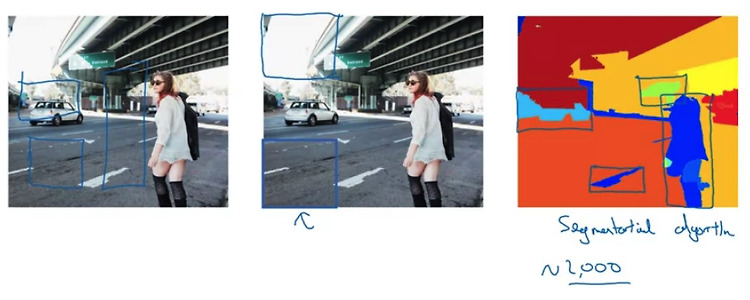
Region proposal: R-CNN 정확히 내용을 이해하지는 못했지만.. 맨 우측과 같이 Segmentation Algorithm에 대한 이야기를 하신 것 같습니다. 기존의 sliding window 방식을 떠올려보면 실제로 object(객체)가 존재하지 않는 수많은 지역에 대해서 연산이 수행됩니다. 굉장히 비효율적이라는 뜻이죠. 따라서 어떤 객체가 존재할만한 지역에 대해서만 sliding window를 적용할 수 있도록 하면 훨씬 빠른 연산이 가능할 것입니다. 맨 우측 사진의 박스, 즉 각 블록이 실제로 sliding window의 대상이 되는 것입니다. 이 블록은 대략 2,000여개 정도까지 반영된다고 합니다. 물론 그것보다 적을 수도 있겠지만요. Faster algorithms 객체 탐지와 관..
![]()
Training 지금까지의 내용을 종합한 YOLO 알고리즘에 대한 예시입니다. 이전 예시와 마찬가지로 anchor box는 두 개이고 class는 세 개이므로 출력 차원은 (3, 3, 16)이 됩니다. 기본적으로 anchor box 한 개는 Pc, x, y, h, w 다섯 개의 정보를 가지고 있습니다. 여기에 클래스의 개수 3을 더하면 각 anchor box는 8차원이 됩니다. 3 x 3 은 이미지를 9개의 cell로 쪼갰기 때문입니다. 실제로는 19 x 19 라고 이전 강의에서 언급되었습니다. Making predictions 이전 내용을 기억하실지 모르겠습니다만, Pc=0인 경우 bounding box나 class에 대한 결과는 무시됩니다. don't care라는 표현을 썼었습니다. 그렇지 않고 Pc..
![]()
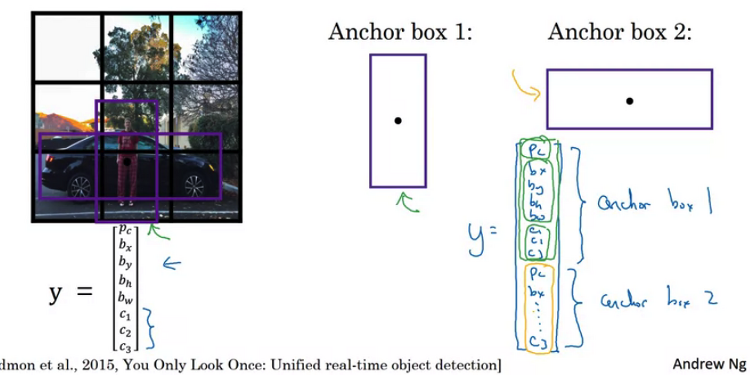
Overlapping objects: 만약 위처럼 이미지 내에 물체가 겹치는 경우 Anchor box 개념을 이용할 수 있습니다. 쉽게 말하자면 축이 되는 box를 미리 정해두고 예측 벡터의 차원을 늘리는 것이죠. 위 예시에서는 Anchor box 두 개를 정해뒀습니다. 여기서 각 그리드에서 나온 예측 결과는 두 anchor에 대한 예측을 포함하고 있을 것입니다. 이런 방식으로 여러 물체가 겹쳐 있는 경우에 대해서도 bounding box를 정확히 예측할 수 있도록 유도할 수 있습니다. Anchor box algorithm 따라서 출력 차원은 anchor box의 개수에 비례합니다. 위 예시에서는 2개의 anchor box를 사용하고 있으며 분류하고자 하는 객체의 종류가 세 개이므로 위와 같은 차원으로 ..