관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST]
- dense video captioning을 zeor-shot으로 처리하는 novel mothod, ZeroTA
- soft moment mask를 도입하고, 이를 언어 모델의 prefix parameters와 jointly optimizing
- soft momnet mask에 대해 pairwise temporal IoU loss를 도입
- supvervised method에 비해 OOD 시나리오에 대해 강건함
- 배경
- 기존의 Dense video captioning은 비디오에 나타난 temporal information의 정확한 representation과 이해가 필요했기 때문에 대량의 annotation이 필요하다는 문제점이 있었음
- Related Works
- Dense video captioning, Vision-language alignment, Moment localization
- Contributions
- pinonerring zero-shot dense video captioning method, ZeroTA (Zero-shot Temporal Aligner)
- temporal localization의 end-to-end optimization을 위한 soft moment masking, localized moments의 다양성을 위한 pairwise temporal IoU loss
- few-shot method를 outperform하기도.. out-of-domain scenarios에 대해 supvervised model보다 강건한 특성
- Method
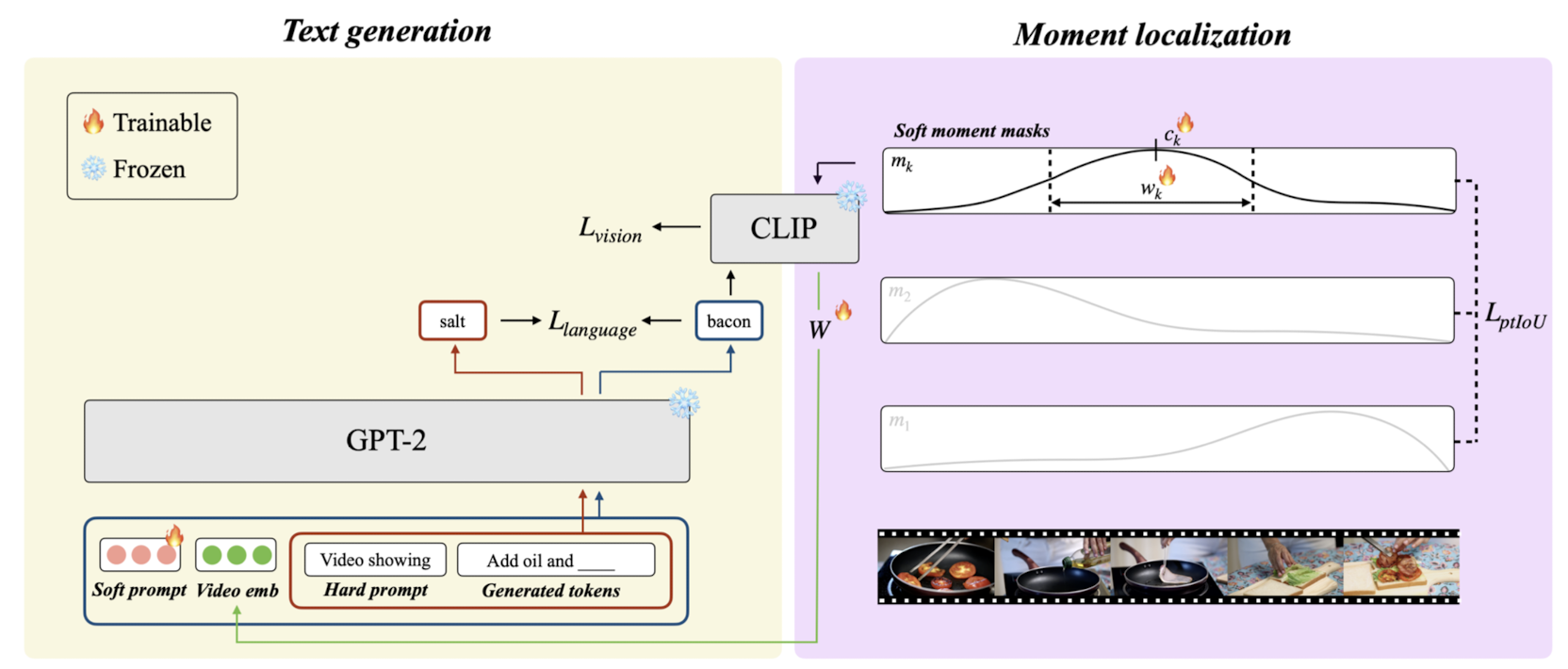
- Text generation
- Prefix context: soft prompt, projected video embedding, hard prompt
- Vision loss: vision-language alignment model CLIP를 통해 loss를 획득
- Language loss: prefix context를 포함하는 언어 모델과, 그렇지 않은 언어 모델로부터의 단어 확률 분포 간 average cross-entropy (CE)를 정량화
- Moment localization: video moment와 생성된 텍스트를 align
- Soft moment masking
- Pariwise temporal IoU loss
- Joint optimization: vision loss, language loss, pairwise temporal IoU loss의 weighted sum
- Text generation
- Benchmarks
- ActivityNet Captions, YouCook2
- Models
- ZeroTA: pre-trained CLIP ViT-L/14 + GPT-2 medium
- baselines: PySceneDetect + BLIP, PySceneDetect + TimeSformer + GPT-2, TimeSformer + GPT-2 + CLIP
- Results
- joint optimization이 two-stage method보다 효과적이다
- ZeroTA가 SoTA few-shot model을 outperform
- target task의 text space와 CLIP의 text space가 match될 필요가 있다
- ZeorTA는 out-of-domain setup에 robust하다
출처 : https://arxiv.org/abs/2307.02682
Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment
Dense video captioning, a task of localizing meaningful moments and generating relevant captions for videos, often requires a large, expensive corpus of annotated video segments paired with text. In an effort to minimize the annotation cost, we propose Zer
arxiv.org