
Machine Learning
Supervised Learning
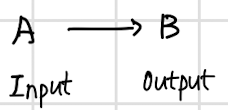
- Input(A): email, audio, English...
- Output(B): spam, text transcript, Chinese...
- Application: spam filtering, speech recognition, machine translation
Why now?

- AI가 급부상하게 된 것은 머신러닝과 인공신경망을 기반으로한 딥러닝의 발전 덕분이다.
- 발전 정도를 도식화하면 위와 같다.
- 따라서 우리는 large neural network와 big data가 필요하다고 말할 수 있다.
What is data?
Example of a table of data(dataset)

- A와 B 자리에는 무엇이든지 내가 원하는 것이 오게 될 것이다.
Acquiring data
- Manual labeling
- From observing behaviors
- ex) commerce websites
- ex) behaviors of machine
- Download from websites / partnerships
Use and mis-use of data
- Don't throw data at an AI team and assume it will be valuable.(over-investing)
- 단순히 데이터의 양이 많다고 해서 가치있는 결과물을 내리라 보장할 수 없다.
- 데이터를 모아서 AI team에게 전달한다는 것은 의미가 없다. 처음부터 AI team의 가이드와 피드백을 따라야 한다.
Data is messy
- Garbage in, garbage out
- Data problems
- Incorrect labels
- Missing values
- Multiple types of data
- (unstructured) images, audio, text
출처: Coursera, AI For Everyone, DeepLearning.AI
'AI For Everyone > 1주차' 카테고리의 다른 글
| Non-technical explanation of deep learning(Part 1,2 optional) (0) | 2022.09.22 |
|---|---|
| What machine learning can and cannot do (0) | 2022.09.22 |
| What makes an AI company? (0) | 2022.09.22 |
| Introduction (0) | 2022.09.21 |