
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Renmin Univ. of China]
- diffusion model을 scratch부터 pre-training & supervised fine-tuning (SFT) 적용한 LLaDA
- 일부 벤치마크에서 Autoregressive models (ARMs)보다 강한 scalability를 보여줌
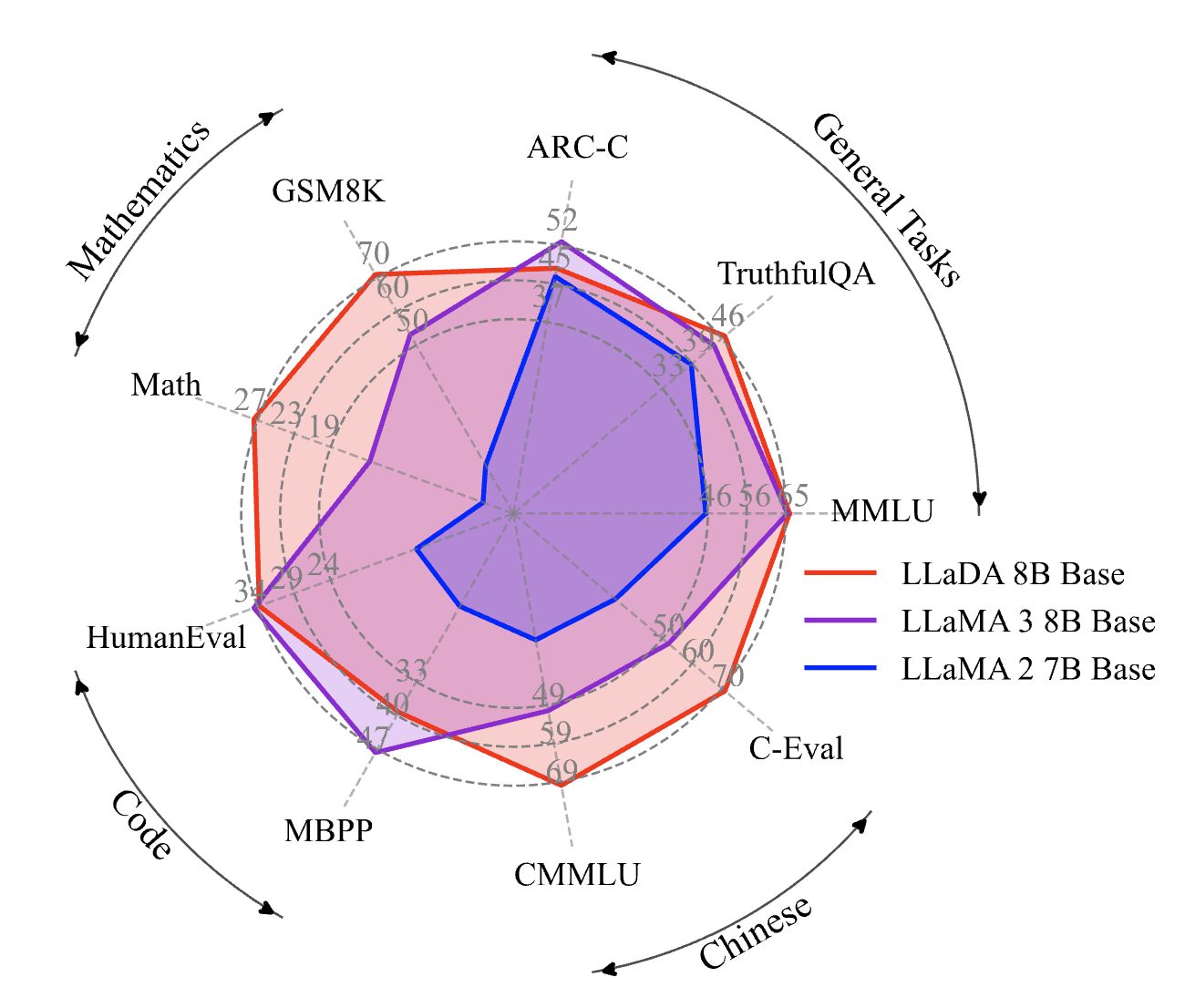
출처 : https://arxiv.org/abs/2502.09992
1. Introduction
최근 Diffusion(이하 디퓨전)을 LLM에 적용한 모델이 (상대적으로 작은 사이즈-7~8B-에서) 뛰어난 성능을 보여주며 화제가 되고 있습니다.
디퓨전은 특히 이미지/비디오 생성 분야에서 좋은 결과로 이어진 사례가 많아 관련 연구가 쏟아지고 있는데요.
(다들 이제는 잘 아시겠지만) 이와 달리 LLM은 현재 스텝에서 다음 스텝에 등장할 확률이 가장 높은 토큰 한 개를 예측하는 Autoregressive models (ARM) 방식입니다. (next-token prediction paradigm)
저자들은 이러한 방식이 현재 LLM과 같은 intelligence를 만들 수 있는 유일한 방식인지에 대해 의문을 제시하고요.
이를 바탕으로 Large Language Diffusion with mAsking, LLaDA를 제시합니다.
물론 저자들 뿐만 아니라 수많은 연구자들이 이러한 의문을 제시하며 다양한 시도를 해왔으니 아직까지는 Mamba 정도를 제외하면 이정도 임팩트는 없었던 것 같습니다.
본론으로 들어가기 전 미리 이해하고 있으면 도움이 되는 내용 중 하나는 compuational cost입니다.
요즘은 갈수록 적은 자원(토큰, 파라미터 등)을 사용하여 기존과 동일하거나 그 이상의 성능을 내는 것에 집중하는 연구들이 많은데요.
디퓨전의 경우 자원이 굉장히 많이 드는 방식인데 이를 적절한 방식으로 조율해서 좋은 성과를 낸 점이 포인트라고 할 수 있겠습니다.
2. Approach
2.1. Probabilistic Formulation
기존 ARM과 달리 LLaDA는 forward process & reverse process를 통해 model distribution을 정의합니다.
forward process에서는 시퀀스가 $t=1$일 때 전부 maksed 될 때까지 $x_0$ 내의 토큰을 독립적으로 & 점진적으로 마스킹합니다.
따라서 $t \in (0,1)$에 대해서 시퀀스 $x_t$는 일부가 마스킹되어 있고, 각각은 $t$의 확률로 마스킹 되어 있을 것이며 나머지는 $1-t$의 확률로 마스킹되지 않은 채 존재합니다.
reverse process는 $t$가 1에서 0으로 변하는 동안 masked tokens이 원래 무엇이었는지를 반복적으로 예측함으로써 data distribution을 회복하는 과정입니다.
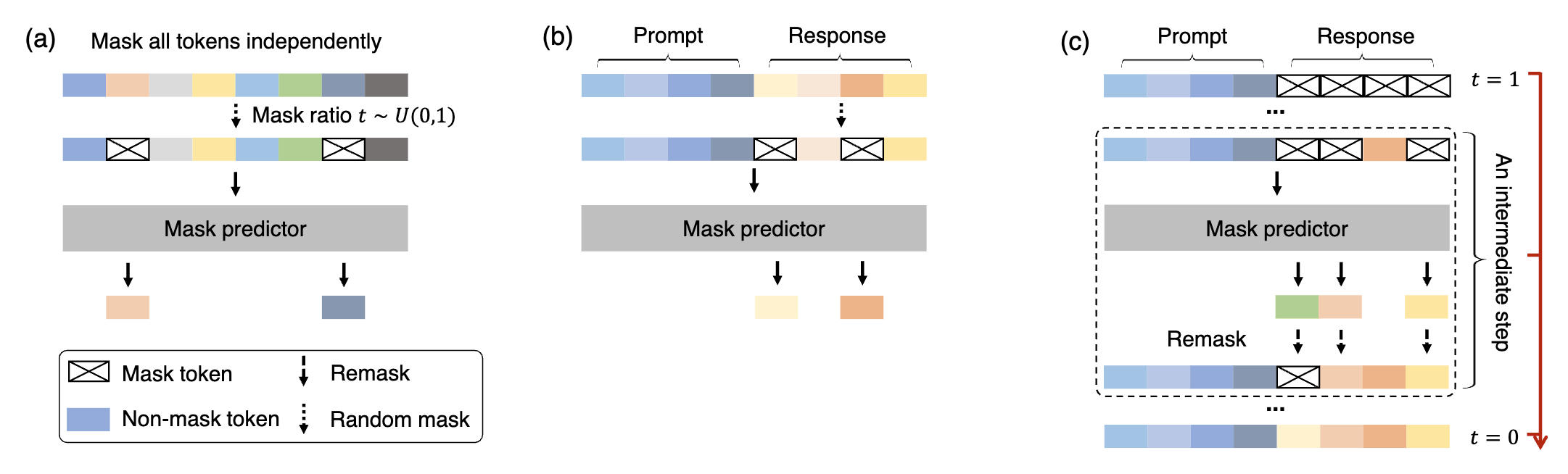
LLaDA의 핵심은 mask predictor로, $x_t$을 입력으로 받아 maskted tokens을 동시에 예측하는 parametric model $p_{\theta}(\cdot |x_t)$입니다.
엄청 심플하게도, masked tokens에 대해서만 적용된 cross-entropy loss를 계산하여 모델은 학습됩니다.
이를 수식으로 표현한 것은 아래와 같습니다.
$$\mathcal{L}(\theta) \triangleq -\mathbb{E}_{t,x_0,x_t} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbb{1}[x_t^i = M] \log p_\theta(x_0^i | x_t) \right]$$
$x_0$는 학습데이터로부터 샘플링하고, $t$는 $[0,1]$ 범위에서 uniformly 샘플링합니다.
$x_t$는 forward process에서 샘플링 됩니다.
$\mathbb{1}[\cdot]$은 loss가 maked tokens에 대해서만 계산될 수 있음을 보장하기 위한 요소입니다.
논문에 딱히 언급되어 있지는 않지만 $i$의 값이 1부터 $L$인 것은 시퀀스의 길이를 의미하는 것 같습니다.
위 내용들을 풀어서 생각해보자면,
0에서 1 사이의 값을 uniformly sampling 하여 획득한 $t$에 대하여,
마스킹을 적용하기 전 최초의 입력 $x_0$ 중 $i$번째 토큰이 무엇인지 모델이 예측해야 하고,
이때 $i$번째 토큰이 masked 되어 있을 때만 손실을 계산한 뒤,
$t$의 값으로 나눠 정규화를 해준 값의 기댓값이 곧 손실로 정의됩니다.
위의 수식은 이미 다른 논문에서 모델 분포에 대해 negative log-likelihood의 상한선임이 입증되어 있습니다.
$$-\mathbb{E}_{p_{\text{data}}(x_0)} \left[ \log p_\theta(x_0) \right] \leq \mathcal{L}(\theta)$$
이와 같은 방식으로 학습이 끝나면 mask predictor에 의해 parameterized reverse process를 시뮬레이션 할 수 있고,
model distribution $p_{\theta}(x_0)$를 $t=0$일 때 유도된 marginal distribution으로 정의할 수 있게 됩니다.
논문에서는 이와 관련하여 in-context learning과 Fisher consistency에 대해 언급하고 있는데 저는 후자는 전혀 모르겠네욥..
2.2. Pre-training
위에서 언급한 것처럼 LLaDA의 가장 중요한 요소는 mask predictor입니다.
LLaDA는 Transformer를 mask predictor로 사용하지만 causal mask는 사용하지 않습니다.
당연한 거지만 한 시점에서 입력 전체를 확인해야 하기 때문입니다.
저자들은 이 모델을 1B와 8B 사이즈로 학습했습니다.
요즘은 대부분의 LLM을 학습할 때 grouped query attention (GQA)를 사용하는데, LLaDA에서는 KV caching을 지원하지 않기 때문에 vanilla multi-head attention을 사용했다고 밝혔습니다.
이는 결과적으로 동일한 개수의 attention layer를 사용한다고 가정했을 때, 더 많은 파라미터를 갖게 된다는 것을 의미합니다.
따라서 다른 ARM과 사이즈를 맞춰주기 위해서 FFN(Feed Forward Network)의 차원(dimension)을 낮춰서 조절했다고 언급하고 있습니다.
LLaDA는 2.3T tokens의 dataset으로 학습되었으며, 4k tokens의 고정된 시퀀스 길이로 학습되었습니다.
단, 이후 다양한 길이의 텍스트에 대응이 가능할 수 있도록, 전체 사전학습 데이터의 1% 정도는 [1, 4096] 에서 uniformly sampled 된 길이의 데이터로 학습했다고 합니다.
이때 사용된 총 자원의 양은 0.13M H800 GPU 시간으로 유사한 사이즈의 ARM과 비슷한 수준임을 언급하고 있습니다.
학습 관련된 기타 디테일은 논문에서 직접 확인하실 수 있습니다.
2.3. Supervised Fine-Tuning
LLaDA가 instruction을 follow 할 수 있도록 paired data $(p_0, r_0)$로 SFT 했다고 합니다.
아주 직관적으로 $p_0$는 prompt, $r_0$는 response를 의미합니다.
학습을 구현하는 것은 pre-training과 크게 다를 것은 없습니다.
다만, prompt가 원래 무엇이었는지를 예측해서 얻을 것은 없으므로, prompt는 그대로 두고 response 내의 tokens만 독립적으로 masking 해줍니다.
이를 수식으로 표현한 것은 아래와 같습니다.
$$-\mathbb{E}_{t,p_0,r_0,r_t} \left[ \frac{1}{t} \sum_{i=1}^{L'} \mathbb{1}[r_t^i = M] \log p_\theta(r_0^i | p_0, r_t) \right]$$
$L'$이 dynamic length를 의미한다는 점을 제외하면 이전과 동일합니다.
($p_0$와 $r_0$를 이어 붙이면 사실상 사전학습 데이터 $x_0$ 그 자체가 됩니다)
이러한 SFT는 4.5M 쌍의 데이터셋으로 수행했다고 합니다.
구체적인 내용이 더 있는지는 모르겠습니다만, 이러한 데이터셋을 구축하는데 LLM을 사용했다고 언급하는 것으로는 봐서 대부분이 합성데이터일 것으로 예상됩니다.
위와 마찬가지로, 학습 관련된 기타 디테일(학습률 등)은 논문에서 직접 확인하실 수 있습니다.
2.4. Inference
프롬프트 $p_0$가 주어지면, fully maksed response에서 시작합니다.
reverse process를 discretize하여 모델 분포 $p_{\theta}(r_0|p_0)$로부터 sampling합니다.
이때 몇 번의 sampling으로 추론할 것인지는 하이퍼파라미터로 결정됩니다.
따라서 정확성과 효율성 간의 trade-off가 일어나는 요소가 됩니다.
유사하게, 생성되는 길이(generation length)도 하이퍼파라미터로 조정하는데, 학습을 마친 모델의 성능이 여기에 대해서는 insensitive 했다고 설명하고 있습니다.
중간 과정에 대한 디테일을 잠깐 설명하는데요,
중간 step $t \in (0, 1]$부터 $s \in [0,t)$에 대해서 $p_0$과 $r_t$를 mask predictor에게 입력으로 제공하면 masked tokens 전체를 동시에 예측하게 됩니다.
그리고 예측된 토큰의 $\frac {s}{t}$를 remask하여 $r_s$를 획득하는데, 이는 forward process와 reverse process를 align 해주기 위함입니다.
또한 SFT 이후의 LLaDA에 대해서는 시퀀스를 여러 blocks로 쪼개고 left to right 방향으로 생성하는 semi-autoregressive remaksing을 적용했다고 합니다.
conditional likelihood evaluation을 위해 상한선을 적용한 수식은 아래와 같습니다.
$$-\mathbb{E}_{l,r_0,r_l} \left[ \frac{L}{l} \sum_{i=1}^{L} \mathbb{1}[r_l^i = M] \log p_\theta(r_0^i | p_0, r_l) \right]$$
3. Experiments
3.1. Scalability of LLaDA on Language Tasks
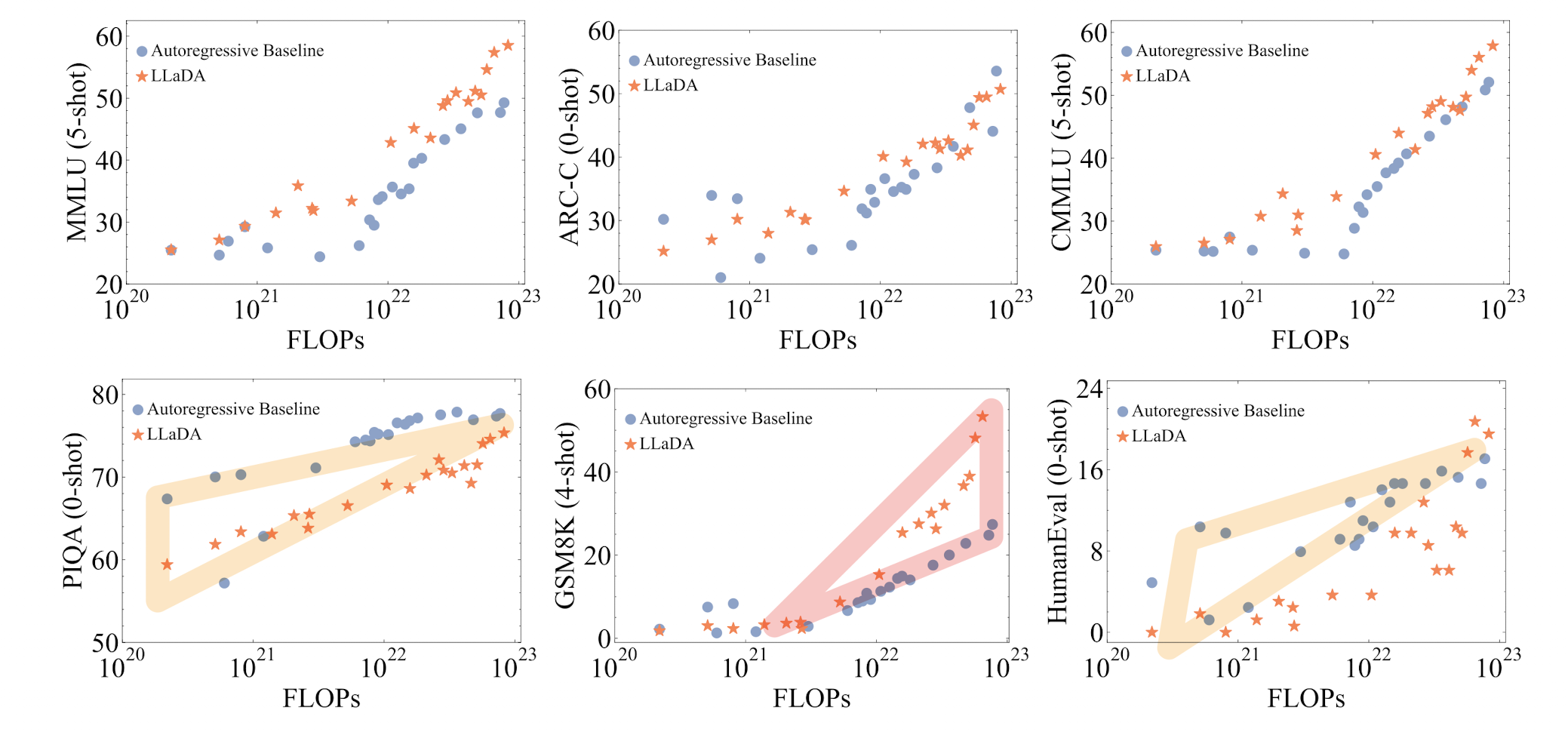
구체적으로 태스크별로 설명을 달지는 않겠습니다.
결과만 간단히 언급하자면 LLaDA가 뛰어난 scalability를 보여줬다는 것입니다.
빨간색으로 표시된 것은 학습을 많이 할수록 기존 ARM 모델과의 갭이 커졌다는 것을 의미합니다.
반대로 노란색으로 표시된 것은, 학습 초반에는 ARM 베이스라인의 성능이 더 좋았으나, 학습을 진행할수록 그 갭이 줄거나 성능 역전이 발생된 것을 의미합니다.
위에서 밝힌대로 LLaDA는 1B, 8B 두 사이즈의 모델로 공개되었는데요, ARM 베이스라인은 LLaMA2 7B, LLaMA3 8B 모델입니다.
3.2. Benchmark Results
Pre-trained LLMs
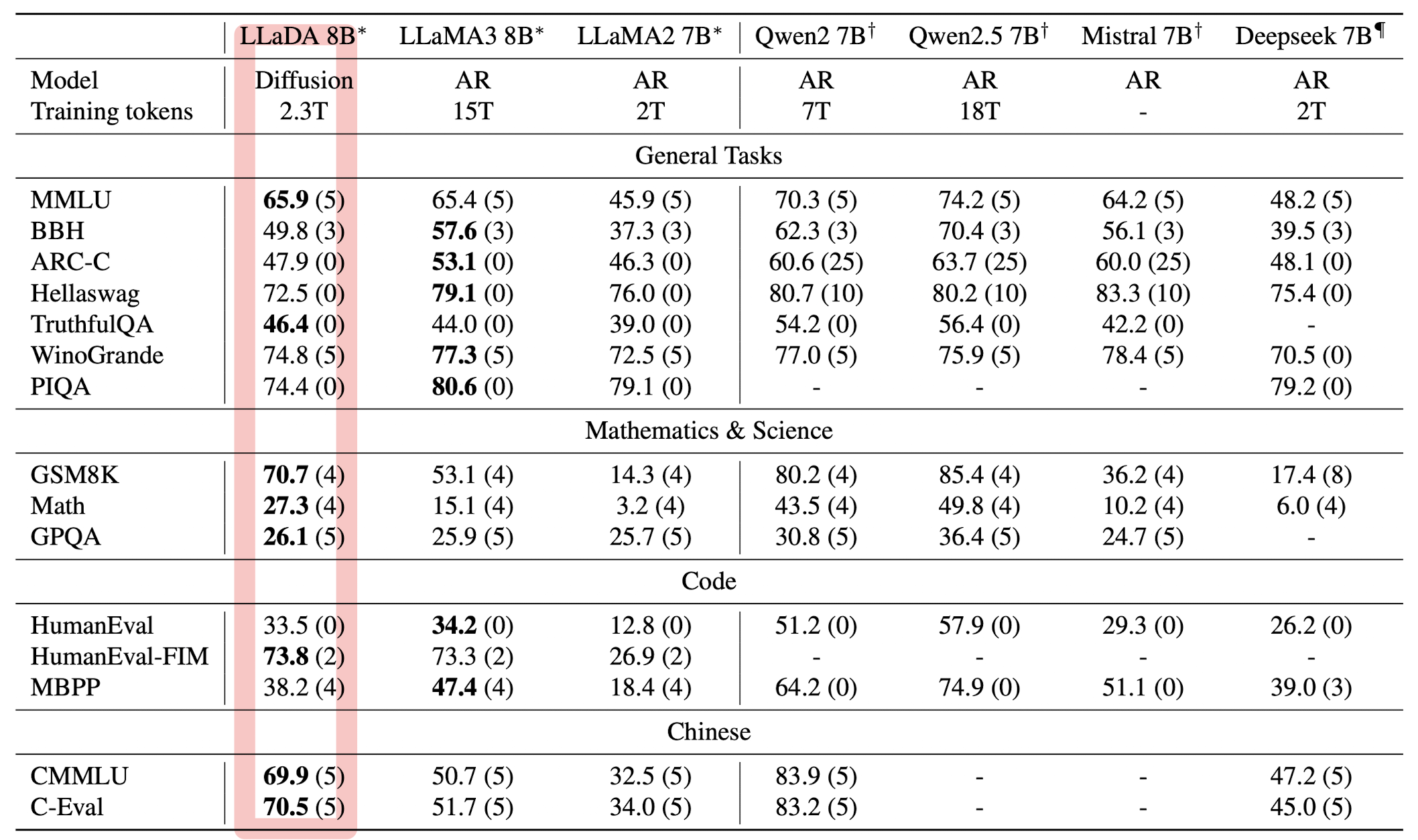
2.3T 토큰으로 학습된 LLaDA 모델은 거의 모든 태스크에서 LLaMA2 7B 모델보다 우수한 성능을 거두었습니다.
하지만 LLaMA3 8B 모델은 수학과 중국어에서 LLaDA보다 강세를 보였는데, 저자는 이것이 closed-source datasets에 기인한 것이라고 추측합니다.
Post-trained LLMs
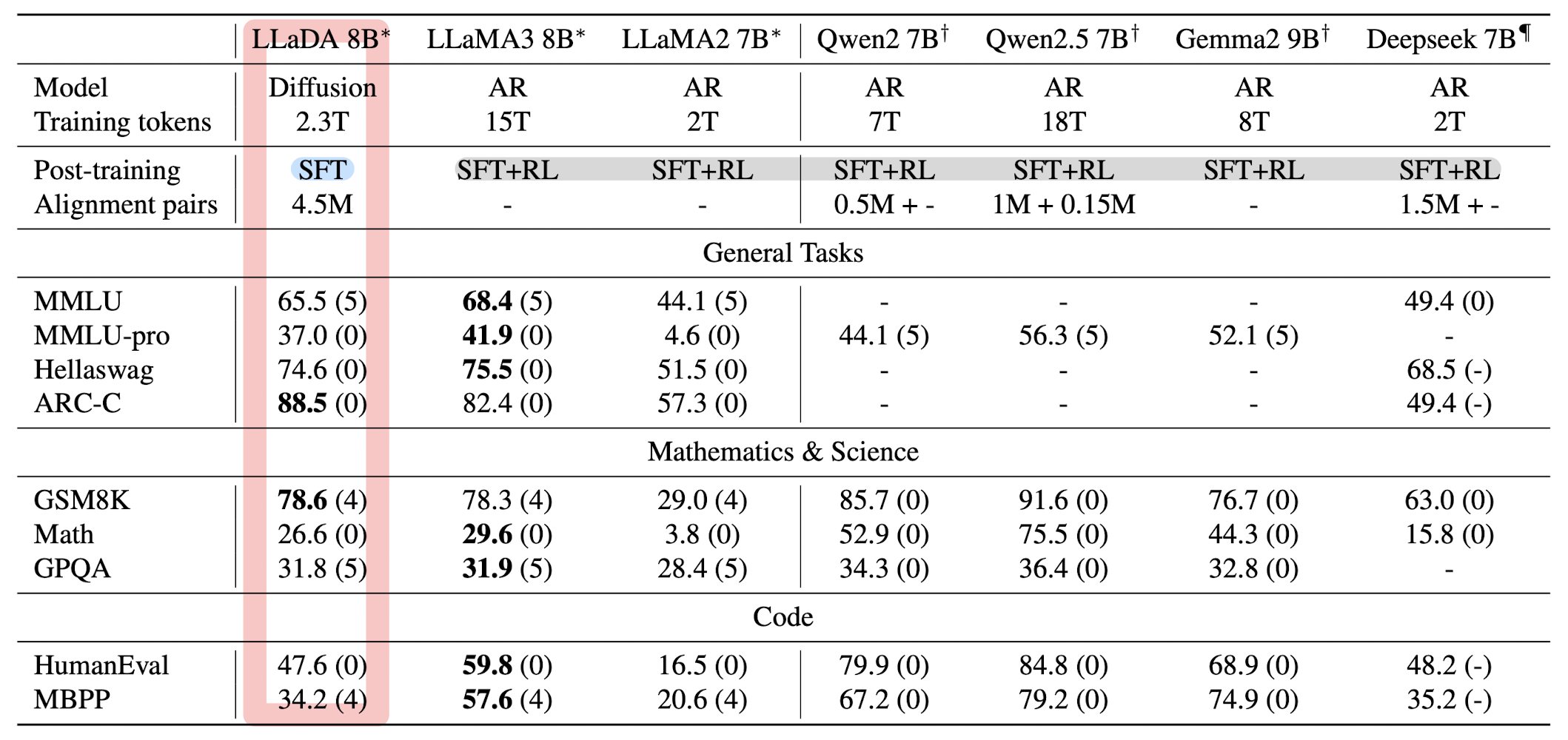
MMLU와 같은 벤치마크에서 낮은 성능을 기록한 것은 SFT 데이터셋의 품질 이슈 때문이라고 설명합니다.
꽤 많은 합성 데이터를 사용한 것으로 보이는데 왜 이런 설명이 있는 것인지 잘 이해되지는 않습니다.
그럼에도 포인트는 이 모델엔 RL이 적용되어 있지 않다는 점입니다.
(RL을 적용한 모델들으 비교군으로 삼고 있습니다)
이것이 의도적인 건지 알 수는 없지만 이를 효율적인 것이라고 언급하고 있습니다.
개인적으로는 RL을 똑같이 적용하면 되지 않나 싶긴 합니다..
3.3. Reversal Reasoning and Analyses
496개의 Chineses peom sentence pairs로 구성된 데이터셋을 구성하여 reversal reasoning 능력을 평가합니다.
모델은 짝을 이루는 데이터 중에서 한 개만을 입력으로 받아, 해당 텍스트에 이어지는 내용(forward)을 생성하거나 앞선 내용(reversal)을 생성해야 합니다.
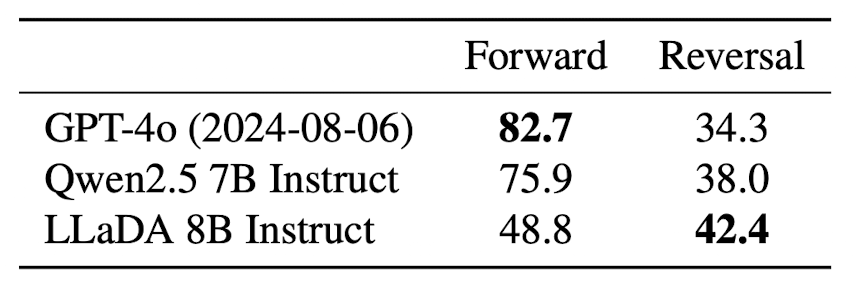
많은 LLM들이 이렇게 단순히 텍스트의 순서를 변경하는 것만으로도 큰 성능 하락폭을 보였는데, LLaDA는 이에 대해 아주 강건한 모습을 보이고 있습니다.
기존에는 다음 토큰을 예측하는 방식(Next Token Prediction)으로 학습되었기 때문에 단순히 순서를 변경하는 것만으로도 모델 성능에 치명적인 영향을 줄 수 있다는 게 일반적인 설명인데요, 이러한 관점에서 LLaDA는 시퀀스 전체를 보며 학습했기 때문에 강건한 것으로 해석할 수 있겠습니다.
하지만 '중국어' 데이터셋이라는 점에서 굳이 신뢰가 가지는 않습니다.
일반적인 LLM들은 중국어로 학습된 비중이 훨씬 적기 때문에..
굳이 이 성능을 확인하고자 했다면 영어로 된 데이터셋으로 평가해봐야 하지 않았나 싶습니다.
4. Conclusion and Discussion
확실히 기존에 있던 것들이더라도 뛰어난 수준으로 발전시켜 실험적으로 입증할 수 있다면 그 자체로 논문거리가 되고 화제도 불러일으킬 수 있는 것 같습니다.
LLaDA는 분명 높은 scalability, in-context learning, instruction-following을 보여줬다고 평가할 수 있어 보입니다.
아직은 아쉬운 면들이 꽤 보이지만 잘 다듬으면 어쩌면 새로운 모델 패러다임을 정말로 제시할 수도 있을까 싶은 생각도 드네요.
저자들은 한계점으로 자원 부족, 그리고 attention과 position embedding의 관점에서 특화된 것을 제공하지 않은 점 등을 단점으로 꼽고 있습니다만..
저는 이게 앞으로 연구해볼 수 있는 주제들을 나열한 것으로밖에 보이지는 않습니다.
여튼, 꽤나 크게 화제가 되고 있는 논문을 오랜만에 조금 디테일하게 살펴봤는데 꽤 흥미롭네요.
예상했던 것보다 복잡한 메커니즘은 아니긴 한데 코드 구현상으로는 꽤 어려울수도 있겠다는 생각이 들었습니다.
이것도 한 번 파볼 필요가 있을 것 같고요..
다만, 성능적으로는 특히나 reversal reasoning에 대한 평가가 너무 편향되어 있는 것 같다는 생각이 들었고..
또 항상 이러한 방법론들이 히트라고 소개된 이후 수십 billion 사이즈의 모델까지 등장하며 경쟁 구도를 갖춘 사례가 없어 기대 & 걱정 되기도 합니다.
유의미한 방법론의 등장임이 입증되는 것은 최소 30B 이상 사이즈의 모델이 히트를 치는 순간이 아닐까 싶은데 이미 관련 연구가 진행되고는 있겠죠?
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Renmin Univ. of China]
- diffusion model을 scratch부터 pre-training & supervised fine-tuning적용한 LLaDA
- 일부 벤치마크에서 Autoregressive models보다 강한 scalability를 보여줌
출처 : https://arxiv.org/abs/2502.09992
1. Introduction
최근 Diffusion
디퓨전은 특히 이미지/비디오 생성 분야에서 좋은 결과로 이어진 사례가 많아 관련 연구가 쏟아지고 있는데요.
저자들은 이러한 방식이 현재 LLM과 같은 intelligence를 만들 수 있는 유일한 방식인지에 대해 의문을 제시하고요.
이를 바탕으로 Large Language Diffusion with mAsking, LLaDA를 제시합니다.
물론 저자들 뿐만 아니라 수많은 연구자들이 이러한 의문을 제시하며 다양한 시도를 해왔으니 아직까지는 Mamba 정도를 제외하면 이정도 임팩트는 없었던 것 같습니다.
본론으로 들어가기 전 미리 이해하고 있으면 도움이 되는 내용 중 하나는 compuational cost입니다.
요즘은 갈수록 적은 자원
디퓨전의 경우 자원이 굉장히 많이 드는 방식인데 이를 적절한 방식으로 조율해서 좋은 성과를 낸 점이 포인트라고 할 수 있겠습니다.
2. Approach
2.1. Probabilistic Formulation
기존 ARM과 달리 LLaDA는 forward process & reverse process를 통해 model distribution을 정의합니다.
forward process에서는 시퀀스가
따라서
reverse process는
LLaDA의 핵심은 mask predictor로,
엄청 심플하게도, masked tokens에 대해서만 적용된 cross-entropy loss를 계산하여 모델은 학습됩니다.
이를 수식으로 표현한 것은 아래와 같습니다.
논문에 딱히 언급되어 있지는 않지만
위 내용들을 풀어서 생각해보자면,
0에서 1 사이의 값을 uniformly sampling 하여 획득한
마스킹을 적용하기 전 최초의 입력
이때
위의 수식은 이미 다른 논문에서 모델 분포에 대해 negative log-likelihood의 상한선임이 입증되어 있습니다.
이와 같은 방식으로 학습이 끝나면 mask predictor에 의해 parameterized reverse process를 시뮬레이션 할 수 있고,
model distribution
논문에서는 이와 관련하여 in-context learning과 Fisher consistency에 대해 언급하고 있는데 저는 후자는 전혀 모르겠네욥..
2.2. Pre-training
위에서 언급한 것처럼 LLaDA의 가장 중요한 요소는 mask predictor입니다.
LLaDA는 Transformer를 mask predictor로 사용하지만 causal mask는 사용하지 않습니다.
당연한 거지만 한 시점에서 입력 전체를 확인해야 하기 때문입니다.
저자들은 이 모델을 1B와 8B 사이즈로 학습했습니다.
요즘은 대부분의 LLM을 학습할 때 grouped query attention
이는 결과적으로 동일한 개수의 attention layer를 사용한다고 가정했을 때, 더 많은 파라미터를 갖게 된다는 것을 의미합니다.
따라서 다른 ARM과 사이즈를 맞춰주기 위해서 FFN
LLaDA는 2.3T tokens의 dataset으로 학습되었으며, 4k tokens의 고정된 시퀀스 길이로 학습되었습니다.
단, 이후 다양한 길이의 텍스트에 대응이 가능할 수 있도록, 전체 사전학습 데이터의 1% 정도는 [1, 4096] 에서 uniformly sampled 된 길이의 데이터로 학습했다고 합니다.
이때 사용된 총 자원의 양은 0.13M H800 GPU 시간으로 유사한 사이즈의 ARM과 비슷한 수준임을 언급하고 있습니다.
학습 관련된 기타 디테일은 논문에서 직접 확인하실 수 있습니다.
2.3. Supervised Fine-Tuning
LLaDA가 instruction을 follow 할 수 있도록 paired data
아주 직관적으로
학습을 구현하는 것은 pre-training과 크게 다를 것은 없습니다.
다만, prompt가 원래 무엇이었는지를 예측해서 얻을 것은 없으므로, prompt는 그대로 두고 response 내의 tokens만 독립적으로 masking 해줍니다.
이를 수식으로 표현한 것은 아래와 같습니다.
이러한 SFT는 4.5M 쌍의 데이터셋으로 수행했다고 합니다.
구체적인 내용이 더 있는지는 모르겠습니다만, 이러한 데이터셋을 구축하는데 LLM을 사용했다고 언급하는 것으로는 봐서 대부분이 합성데이터일 것으로 예상됩니다.
위와 마찬가지로, 학습 관련된 기타 디테일
2.4. Inference
프롬프트
reverse process를 discretize하여 모델 분포
이때 몇 번의 sampling으로 추론할 것인지는 하이퍼파라미터로 결정됩니다.
따라서 정확성과 효율성 간의 trade-off가 일어나는 요소가 됩니다.
유사하게, 생성되는 길이
중간 과정에 대한 디테일을 잠깐 설명하는데요,
중간 step
그리고 예측된 토큰의
또한 SFT 이후의 LLaDA에 대해서는 시퀀스를 여러 blocks로 쪼개고 left to right 방향으로 생성하는 semi-autoregressive remaksing을 적용했다고 합니다.
conditional likelihood evaluation을 위해 상한선을 적용한 수식은 아래와 같습니다.
3. Experiments
3.1. Scalability of LLaDA on Language Tasks
구체적으로 태스크별로 설명을 달지는 않겠습니다.
결과만 간단히 언급하자면 LLaDA가 뛰어난 scalability를 보여줬다는 것입니다.
빨간색으로 표시된 것은 학습을 많이 할수록 기존 ARM 모델과의 갭이 커졌다는 것을 의미합니다.
반대로 노란색으로 표시된 것은, 학습 초반에는 ARM 베이스라인의 성능이 더 좋았으나, 학습을 진행할수록 그 갭이 줄거나 성능 역전이 발생된 것을 의미합니다.
위에서 밝힌대로 LLaDA는 1B, 8B 두 사이즈의 모델로 공개되었는데요, ARM 베이스라인은 LLaMA2 7B, LLaMA3 8B 모델입니다.
3.2. Benchmark Results
Pre-trained LLMs
2.3T 토큰으로 학습된 LLaDA 모델은 거의 모든 태스크에서 LLaMA2 7B 모델보다 우수한 성능을 거두었습니다.
하지만 LLaMA3 8B 모델은 수학과 중국어에서 LLaDA보다 강세를 보였는데, 저자는 이것이 closed-source datasets에 기인한 것이라고 추측합니다.
Post-trained LLMs
MMLU와 같은 벤치마크에서 낮은 성능을 기록한 것은 SFT 데이터셋의 품질 이슈 때문이라고 설명합니다.
꽤 많은 합성 데이터를 사용한 것으로 보이는데 왜 이런 설명이 있는 것인지 잘 이해되지는 않습니다.
그럼에도 포인트는 이 모델엔 RL이 적용되어 있지 않다는 점입니다.
이것이 의도적인 건지 알 수는 없지만 이를 효율적인 것이라고 언급하고 있습니다.
개인적으로는 RL을 똑같이 적용하면 되지 않나 싶긴 합니다..
3.3. Reversal Reasoning and Analyses
496개의 Chineses peom sentence pairs로 구성된 데이터셋을 구성하여 reversal reasoning 능력을 평가합니다.
모델은 짝을 이루는 데이터 중에서 한 개만을 입력으로 받아, 해당 텍스트에 이어지는 내용
많은 LLM들이 이렇게 단순히 텍스트의 순서를 변경하는 것만으로도 큰 성능 하락폭을 보였는데, LLaDA는 이에 대해 아주 강건한 모습을 보이고 있습니다.
기존에는 다음 토큰을 예측하는 방식
하지만 '중국어' 데이터셋이라는 점에서 굳이 신뢰가 가지는 않습니다.
일반적인 LLM들은 중국어로 학습된 비중이 훨씬 적기 때문에..
굳이 이 성능을 확인하고자 했다면 영어로 된 데이터셋으로 평가해봐야 하지 않았나 싶습니다.
4. Conclusion and Discussion
확실히 기존에 있던 것들이더라도 뛰어난 수준으로 발전시켜 실험적으로 입증할 수 있다면 그 자체로 논문거리가 되고 화제도 불러일으킬 수 있는 것 같습니다.
LLaDA는 분명 높은 scalability, in-context learning, instruction-following을 보여줬다고 평가할 수 있어 보입니다.
아직은 아쉬운 면들이 꽤 보이지만 잘 다듬으면 어쩌면 새로운 모델 패러다임을 정말로 제시할 수도 있을까 싶은 생각도 드네요.
저자들은 한계점으로 자원 부족, 그리고 attention과 position embedding의 관점에서 특화된 것을 제공하지 않은 점 등을 단점으로 꼽고 있습니다만..
저는 이게 앞으로 연구해볼 수 있는 주제들을 나열한 것으로밖에 보이지는 않습니다.
여튼, 꽤나 크게 화제가 되고 있는 논문을 오랜만에 조금 디테일하게 살펴봤는데 꽤 흥미롭네요.
예상했던 것보다 복잡한 메커니즘은 아니긴 한데 코드 구현상으로는 꽤 어려울수도 있겠다는 생각이 들었습니다.
이것도 한 번 파볼 필요가 있을 것 같고요..
다만, 성능적으로는 특히나 reversal reasoning에 대한 평가가 너무 편향되어 있는 것 같다는 생각이 들었고..
또 항상 이러한 방법론들이 히트라고 소개된 이후 수십 billion 사이즈의 모델까지 등장하며 경쟁 구도를 갖춘 사례가 없어 기대 & 걱정 되기도 합니다.
유의미한 방법론의 등장임이 입증되는 것은 최소 30B 이상 사이즈의 모델이 히트를 치는 순간이 아닐까 싶은데 이미 관련 연구가 진행되고는 있겠죠?