목차
1. What is a Nerual Network?
Housing Price Prediction

- size라는 input x를 받아 계산한 결과가 price라는 output y가 되고, 이것을 그래프로 표현한 것이다.
- input을 output으로 만들어주는 계산 과정이 포함된 부분을 도식화하면 동그라미가 되고, nueron이라고 한다.
- 위 그래프는 y의 값이 음수가 절대로 될 수 없기 때문에 y값이 전부 0으로 표현되는 수평한부분이 존재한다.
이런 형태의 그래프는 Rectified Linear Unit, ReLU 의 형태다.
지금 당장은 자세히 몰라고 되지만 향후 중요하게 다룰 내용이다. - 지금은 single neuron만 존재하는 아주 간단한 형태의 neural network이고,
더 복잡한 NN을 만들기 위해서는 이를 여러 개 stack(쌓으면)하면 된다.

- 집의 크기뿐 아니라 침실의 개수, 주소, 주변 환경 등 네 개의 요소를 고려한다.
즉, 네 개의 input을 가지는 형태인 것이다. - 이로부터 추가로 고려할 사항인 family size, walkability, school quality 등을 추가한다.
이는 input으로부터 자연스레 도출되는 것이다. - 이것들을 모두 합쳐서 우리가 알고 싶은 price, y를 이끌어낼 수 있다.

- 위 내용을 깔끔하게 도식화한 결과다.
- 중간 노드들이 모인 층을 hidden layer라고 부른다.
이때 첫 노드인 family size는 단순히 input의 size, #bedrooms와만 연결된 것이라고 표현되지 않고 있다.
NN의 각 층은 input과 유기적으로 모두 연결되어 있는 것으로 이해해야 한다.
(= input layer는 모든 hidden layer와 연결되어 있다.) - data의 양이 많으면 많을수록 x로부터 적절한 y를 mapping 함에 있어서의 정확도가 올라간다.
2. Supervised Learning with Neural Networks
Supervised Learning

- 딥러닝을 다양한 분야에 활용할 수 있는 사례들을 정리한 표다.
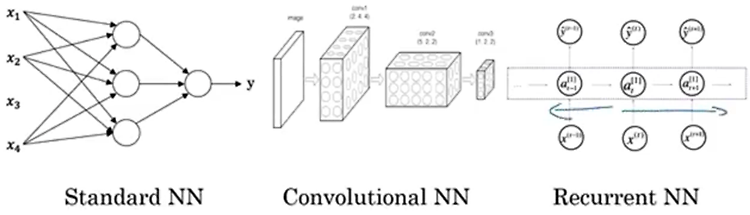
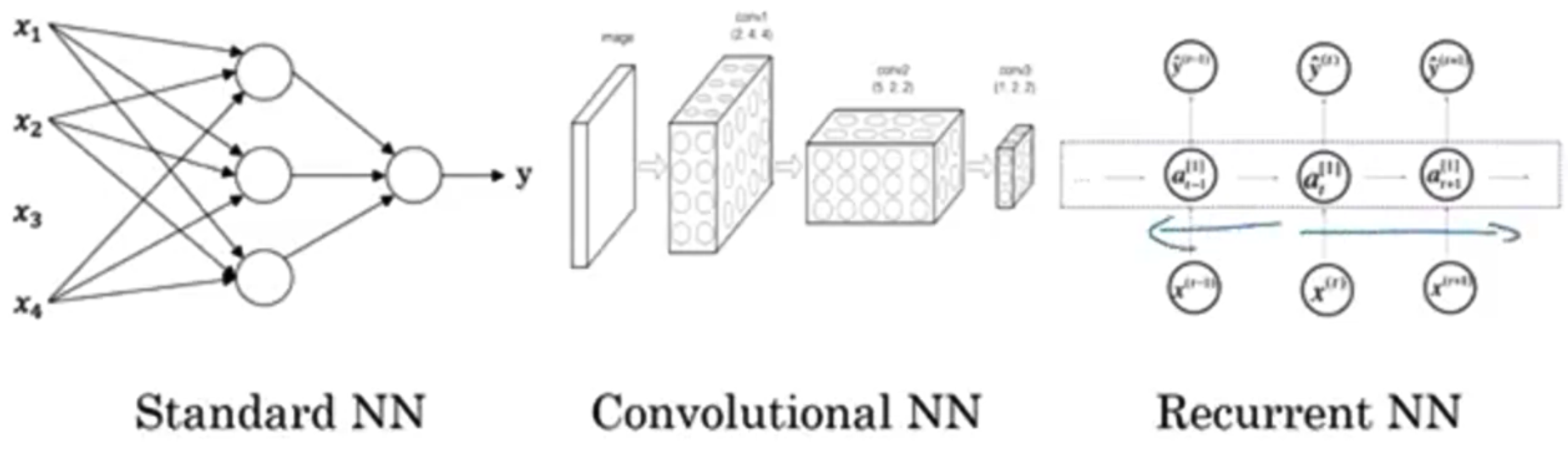
- Standard NN: Real Estate, Online Advertising
CNN: Photo tagging
RNN: Speech recognition, Machine translation
Custom / Hybrid: Autonomous driving

- 기존에는 structured data를 처리하는 것이 중요 관건이었다.
- 딥러닝의 발전으로 인해 컴퓨터가 unstructured data에 대해서도 학습을 훌륭하게 수행할 수 있게 되었다.
3. Why is Deep Learning taking off?
Scale drives deep learning progress

- 데이터의 양과 모델에 따른 performance를 그래프로 표현하면 위와 같다.
- 이때의 데이터는 labeld data를 의미하고 기호 m으로 표시할 수 있다.
이를 training data라고 해석할 수 있다. - 이 그래프에 따라 우리는 large NN(Nerual Network)와 large data set이 필요하다고 할 수 있다.

- 딥러닝의 발전에는 data, computation, algorithms 이 세 개의 요소가 중요하다.
- algorithm의 발전은 곧 computatoin의 성능에 영향을 준다.
예를 들어 기존의 활성화 함수였던 Sigmoid를 ReLU로 대체함으로 인해 Gradient Descent의 성능이 탁월하게 좋아졌다.
관련 예는 수도 없이 많다. - computation의 성능이 좋아진다는 것은 여러 테스트 결과를 빠르게 확인하고 수정할 수 있게 된다는 것을 의미한다.
어떤 idea를 code로 구현하고 그 결과를 확인하는데 걸리는 시간이 각각 10분, 하루, 한 달이라고 한다면 어떤 것이 더 바람직한 것일지는 깊게 생각해보지 않아도 알 수 있다고 생각한다.
4. Quiz: Introduction to Deep Learning
- 생각보다 디테일한 질문들이 많았다.
- AI가 영향을 미친 산업군
- Deep Learning 알고리즘이 좋은 성과를 내기 위한 조건들
- 데이터의 양과 Neural Network 사이즈 관계 그래프에 대한 해석
- structrued / unstructured data의 특징
- RNN의 특징
- 강의에 포함된 모든 내용들에 대해 자세한 내용들을 '중복' 선택하도록 출제된 문제가 많아서 다 맞히기 어려웠다.
출처: Coursera, Neural Networks and Deep Learning, DeepLearning.AI
1. What is a Nerual Network?
Housing Price Prediction
- size라는 input x를 받아 계산한 결과가 price라는 output y가 되고, 이것을 그래프로 표현한 것이다.
- input을 output으로 만들어주는 계산 과정이 포함된 부분을 도식화하면 동그라미가 되고, nueron이라고 한다.
- 위 그래프는 y의 값이 음수가 절대로 될 수 없기 때문에 y값이 전부 0으로 표현되는 수평한부분이 존재한다.
이런 형태의 그래프는 Rectified Linear Unit, ReLU 의 형태다.
지금 당장은 자세히 몰라고 되지만 향후 중요하게 다룰 내용이다. - 지금은 single neuron만 존재하는 아주 간단한 형태의 neural network이고,
더 복잡한 NN을 만들기 위해서는 이를 여러 개 stack(쌓으면)하면 된다.
- 집의 크기뿐 아니라 침실의 개수, 주소, 주변 환경 등 네 개의 요소를 고려한다.
즉, 네 개의 input을 가지는 형태인 것이다. - 이로부터 추가로 고려할 사항인 family size, walkability, school quality 등을 추가한다.
이는 input으로부터 자연스레 도출되는 것이다. - 이것들을 모두 합쳐서 우리가 알고 싶은 price, y를 이끌어낼 수 있다.
- 위 내용을 깔끔하게 도식화한 결과다.
- 중간 노드들이 모인 층을 hidden layer라고 부른다.
이때 첫 노드인 family size는 단순히 input의 size, #bedrooms와만 연결된 것이라고 표현되지 않고 있다.
NN의 각 층은 input과 유기적으로 모두 연결되어 있는 것으로 이해해야 한다.
(= input layer는 모든 hidden layer와 연결되어 있다.) - data의 양이 많으면 많을수록 x로부터 적절한 y를 mapping 함에 있어서의 정확도가 올라간다.
2. Supervised Learning with Neural Networks
Supervised Learning
- 딥러닝을 다양한 분야에 활용할 수 있는 사례들을 정리한 표다.
- Standard NN: Real Estate, Online Advertising
CNN: Photo tagging
RNN: Speech recognition, Machine translation
Custom / Hybrid: Autonomous driving
- 기존에는 structured data를 처리하는 것이 중요 관건이었다.
- 딥러닝의 발전으로 인해 컴퓨터가 unstructured data에 대해서도 학습을 훌륭하게 수행할 수 있게 되었다.
3. Why is Deep Learning taking off?
Scale drives deep learning progress
- 데이터의 양과 모델에 따른 performance를 그래프로 표현하면 위와 같다.
- 이때의 데이터는 labeld data를 의미하고 기호 m으로 표시할 수 있다.
이를 training data라고 해석할 수 있다. - 이 그래프에 따라 우리는 large NN(Nerual Network)와 large data set이 필요하다고 할 수 있다.
- 딥러닝의 발전에는 data, computation, algorithms 이 세 개의 요소가 중요하다.
- algorithm의 발전은 곧 computatoin의 성능에 영향을 준다.
예를 들어 기존의 활성화 함수였던 Sigmoid를 ReLU로 대체함으로 인해 Gradient Descent의 성능이 탁월하게 좋아졌다.
관련 예는 수도 없이 많다. - computation의 성능이 좋아진다는 것은 여러 테스트 결과를 빠르게 확인하고 수정할 수 있게 된다는 것을 의미한다.
어떤 idea를 code로 구현하고 그 결과를 확인하는데 걸리는 시간이 각각 10분, 하루, 한 달이라고 한다면 어떤 것이 더 바람직한 것일지는 깊게 생각해보지 않아도 알 수 있다고 생각한다.
4. Quiz: Introduction to Deep Learning
- 생각보다 디테일한 질문들이 많았다.
- AI가 영향을 미친 산업군
- Deep Learning 알고리즘이 좋은 성과를 내기 위한 조건들
- 데이터의 양과 Neural Network 사이즈 관계 그래프에 대한 해석
- structrued / unstructured data의 특징
- RNN의 특징
- 강의에 포함된 모든 내용들에 대해 자세한 내용들을 '중복' 선택하도록 출제된 문제가 많아서 다 맞히기 어려웠다.
출처: Coursera, Neural Networks and Deep Learning, DeepLearning.AI