![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [OpenAI] - strong pretrained model을 weak supervisor를 통해 fine-tuning 하더라도 supervisor보다 뛰어난 성능을 보인다 - 이를 weak-to-strong generalization 현상이라고 부른다 - 미래에는 superhuman model을 학습하기 위해 RLHF와 같은 테크닉들을 적용할 수 없을 것이다 1. Introduction 오늘날 많은 언어 모델들은 Reinforcement Learning from Human Feedback(RLHF)와 같은 테크닉들을 통해 학습되고 있습니다. ..
![]()
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research] reverse KLD를 이용하여 사이즈가 큰 생성 모델로부터 distill을 적용한 MINILLM. 우수한 성능과 함께, 더 큰 사이즈의 모델에도 적용할 수 있다는 특징, 즉 scability가 특징이다. 배경 LLM이 크게 주목을 받으면서 이를 운용하기 위해 필요한 자원상의 한계가 항상 지적되었습니다. 덕분에 적은 자원을 사용하면서도 준수한 성능을 유지할 수 있도록 하는 기법들이 많이 연구되었습니다. 그중에서도 Knowledge Distillation(KD) 방식도 아주 활발히 사용되는데, 큰 ..
![]()
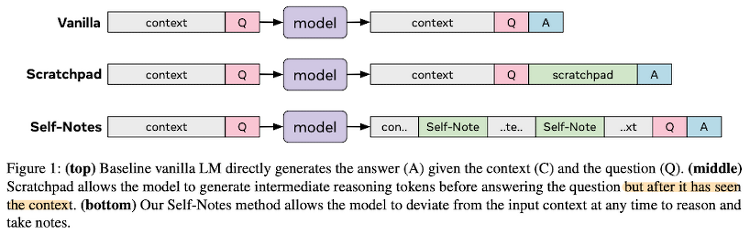
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 모델이 추론하는 과정에서 스스로 생성한 QA(note)를 참고해 보다 정확한 추론을 가능하도록 만든 모델 배경 지금까지의 인공지능 모델들은 multi-step reasoning에 대해 취약한 모습을 보이고 있다. 왜냐하면 여러 단계를 한 번에 압축하여 추론하므로 모델의 입장에서 여러 요소를 충분히 고려할 수 없게 되기 때문이다. 즉 여러 state가 주어졌을 때, state-traking 혹은 highly nonlinear 문제들을 풀어낼 수가 없는 것이다. 따라서 본 논문에서는 multi-step reasoning을 진행하는 과정에서, 주어진 문장에 대해 모델 스스로 질문 & 답변하고, 이..