![]()
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft] - 학습 동안에 residual path를 추가하고, 추론 시에는 extra path를 제거하는 merging을 적용한 ResLoRA - LoRA와 residual path를 결합한 최초의 방법론� 출처 : https://arxiv.org/abs/2402.18039 ResLoRA: Identity Residual Mapping in Low-Rank Adaption As one of the most popular parameter-efficient fine-tuning (PEFT) methods, low-rank adapta..
![]()
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ Abstract [NLP Group, Fudan University] usechatgpt init success 목적: 대규모 언어 모델(Large Language Models, LLMs)의 인간 지시 사항과의 정렬 및 다운스트림 작업에서의 성능 향상을 위한 중요한 단계로서, 감독된 미세 조정(Supervised Fine-Tuning, SFT)의 중요성을 강조. 문제점: 더 넓은 범위의 다운스트림 작업에 모델을 정렬하거나 특정 작업의 성능을 크게 향상시키려는 경우, 미세 조정 데이터의 대규모 증가가 필요해지는데, 이는 LLM에서 저장된 세계 지식을 잊어버리는 문제(wor..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success - 많은 LoRA adapters를 scalable하게 serving할 수 있도록 designed된 system, S-LoRA - Unified Paging, custom CUDA kernels를 도입� 1. Introduction "pretrain-then-finetune" 패러다임이 성행함에 따라 수많은 variants가 생성됨 Low-Rank Adaptation (LoRA)와 같은 parameter-efficient fine-tuning (PEFT) method가 발전됨 원조 LoRA는 adapter의 파라미터를 기존 모델의 파라미터와 me..
![]()
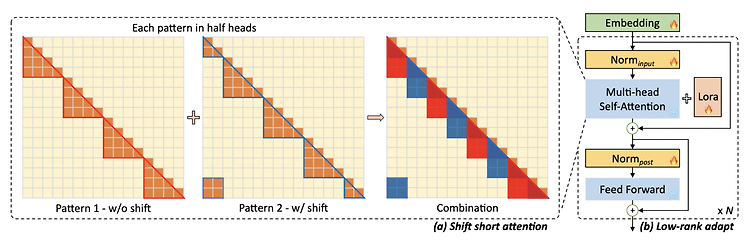
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT] 사전학습된 LLM의 context size를 확장하는 efficient fine-tuning 기법, LongLoRA. sparse local attention 방식 중 하나로 shift shoft attention(S^2-Attn)를 제안하고, trainable embedding & normalization을 통해 computational cost를 대폭 줄이면서도 기존 모델에 준하는 성능을 보임. Fine-tugning을 위한 3K 이상의 long context question-answer pair dataset, Lon..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 여러 개의 LoRA 모듈을 구성하여 task 간 일반화 성능이 뛰어난 LoRA 허브를 제시. few-shot 상황에서 in-context learning 능력이 준수함을 BBH(Big-Bench Hard) 벤치마크로 검증 배경 모델의 학습 가능한 파라미터수가 날이 갈수록 늘어나자 이를 최소화하며 동일한 성능을 유지하고자 하는 연구들이 이어지고 있습니다. 그중에서도 행렬 분해를 통해 학습 가능한 파라미터의 수를 획기적으로 줄이면서 기존의 성능에 버금가는 모델이 될 수 있도록 하는 학습 방식으로, LoRA가 가장 크게 주목을 받았죠. 하지만 이는 LLM이 가진 일반화 능력을 포기..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ FLAN-MINI 데이터셋을 대상으로 LLaMA 모델을 Fine-tuning with LoRA 하여 다양한 태스크 수행 능력과 코드 해석 능력을 준수하게 끌어올린 모델, Flacuna 배경 ChatGPT를 필두로 LLM들이 다양한 분야와 태스크에서 우수한 성능을 보이고 있습니다. 그럼에도 불구하고 strong reasoning & problem solving 능력이 요구되는 태스크들에 대해서는 여전히 T-5 based 모델들이 더 좋은 퍼포먼스를 보입니다. 본 논문에서는 그 주요 원인을 (1) Pre-training data, (2) Backbone architecture, ..