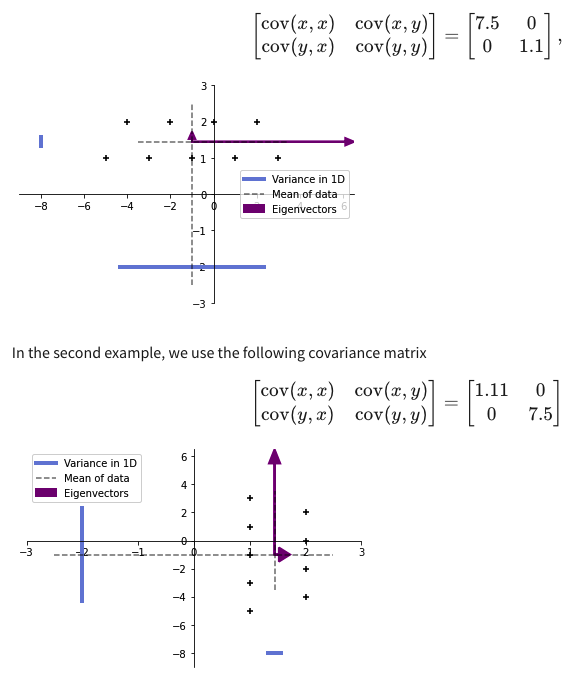
1. Variance of one-dimensional datasets D1 데이터셋에 포함되는 데이터들은 파란색 점으로, D2 데이터셋에 포함되는 데이터들은 빨간색 사각형으로 표현된다. 두 데이터셋은 같은 평균값을 가지지만 그 분포가 다르다는 것을 확인할 수 있다. 각 데이터셋의 평균값을 구하고 각 데이터들과의 편차를 구해본다. 계산해보면 D1에서 구한 것이 D2에서 구한 것보다 작다. 즉, D2의 분산이 더 큰 것이다. 분산은 데이터들이 얼마나 집중되어 있는지를 나타내는 지표로 쓰이게 된다. 구하는 식이 제곱의 합이므로 0이상의 값을 갖게 된다. 이 분산에 루트를 씌운 것을 standard variation(표준 편차)이라고 부른다. 2. Variance of 1D datasets 데이터셋의 평균,..