
Learning the similarity function
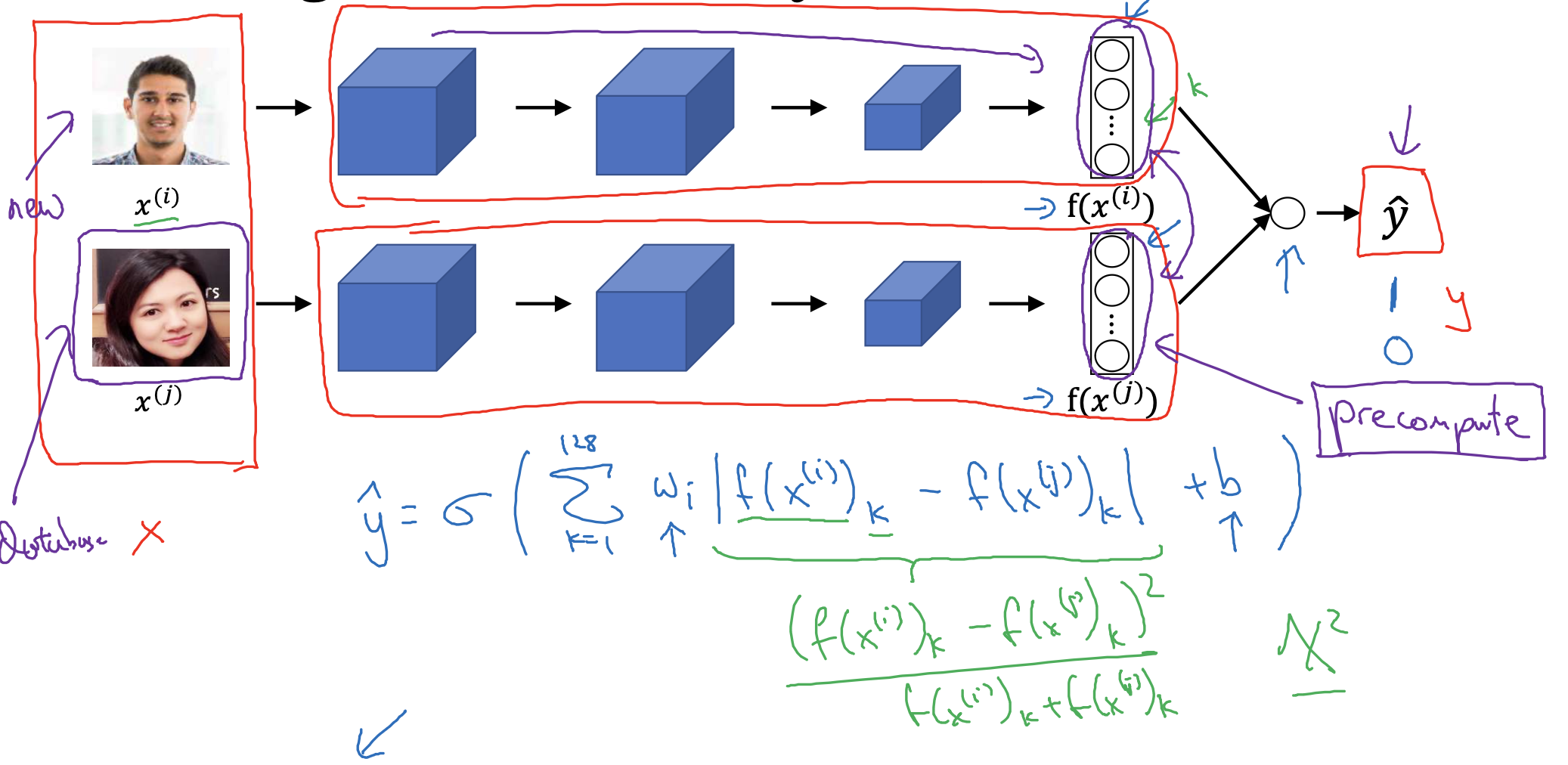
- 이전까지 배운 내용을 적용하면 위의 식으로 y hat, 즉 예측값을 구할 수 있습니다.
두 input으로 구한 output의 차, 그리고 이것을 제곱한 것이 loss function이 되었습니다. - 우리는 그래서 이 loss function의 값에 따라서 일정 기준(threshold)가 넘냐 넘지 않느냐를 보고 0 또는 1로 예측합니다.
- 여기서 0과 1은 각각 동일 인물이 아님, 동일 인물임을 의미합니다.
- 두 output의 차 대신 카이제곱 분포를 사용할 수도 있다고 합니다.
- 결국 output의 차에 weight를 곱하고 bias를 더한 것을 sigmoid 함수의 input으로 사용하게 되면 0 또는 1의 y hat을 얻을 수 있게 됩니다.
- 만약 기존의 database 외의 새로운 인물이 등장해서 추가 학습을 진행해야 하는 경우엔,
기존에 계산된 output을 불러와서 비교하면 보다 효율적으로 계산할 수도 있습니다.
Face verification supervised learning

출처: Coursera, Convolutional Neural Networks, DeepLearning.AI
'Convolutional Neural Networks > 4주차' 카테고리의 다른 글
| Neural Style Transfer(3),(4) : Cost Function, Content Cost Function (0) | 2023.04.05 |
|---|---|
| Neural Style Transfer(1),(2) : What is Neural Style Transfer?, What are deep ConvNets learning? (0) | 2023.04.05 |
| Face Recognition(4) : Triplet Loss (0) | 2023.04.03 |
| Face Recognition(3) : Siamese Network (0) | 2023.04.03 |
| Face Recognition(1),(2) : What is Face Recognition, One Shot Learning (0) | 2023.04.03 |