
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM을 학습시킬 때 Chain of Thought(CoT)가 모델의 performance를 엄청나게 향상시킨다는 것은 잘 알려져있다.
이때 chain의 중간 과정들은 사실상 버려지게 되는데, Multi-Chain Reasoning(MCR)에서는 이를 정답을 생성하는 근거로 재활용한다(여기서는 다른 LLM을 사용).
- 모델 컨셉
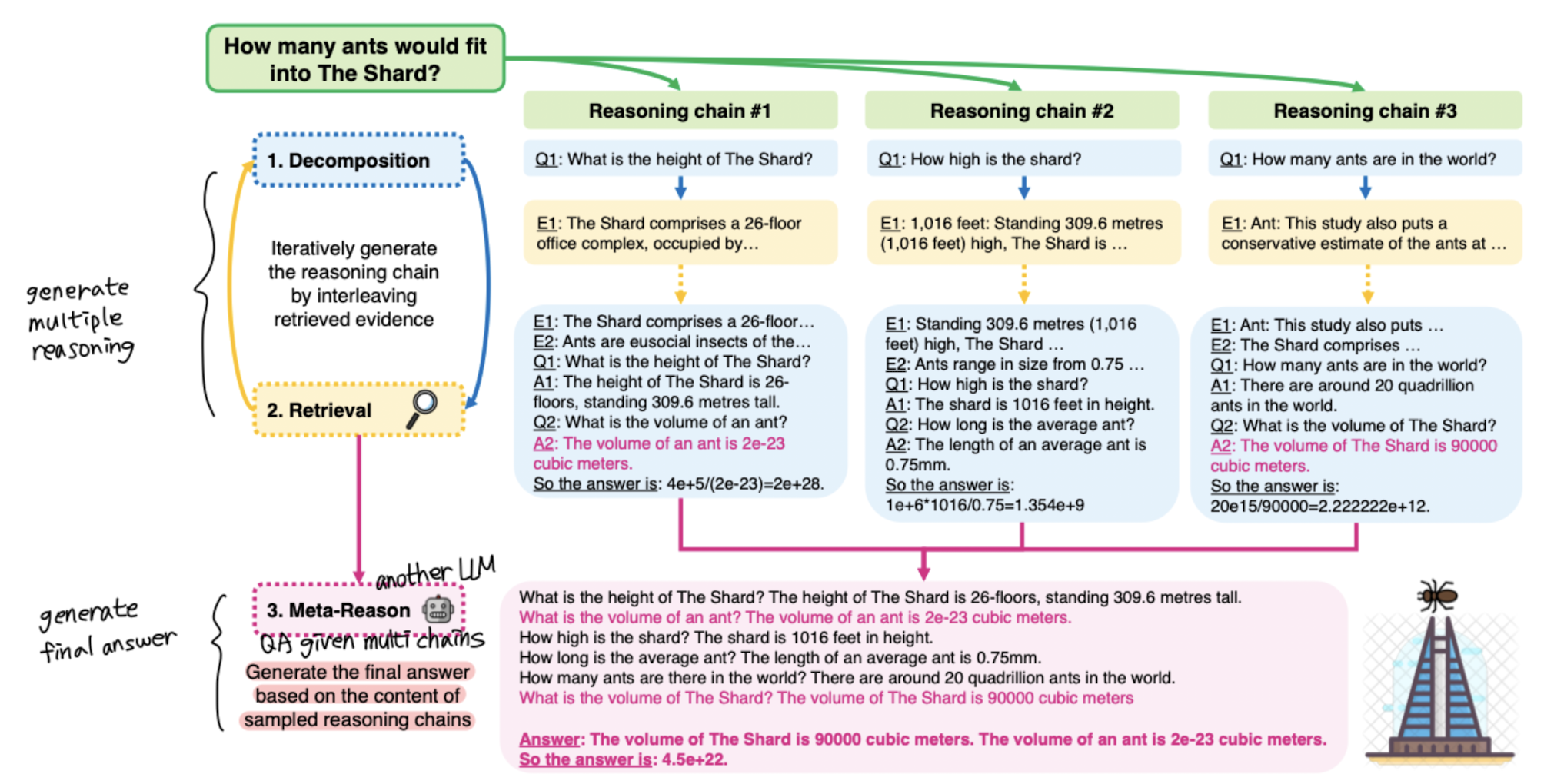
우선 주어진 질문을 쪼갠다(decomposition) → 질문을 기반으로 탐색(retrieval)하여 원하는 정보를 가져와 답변으로 만든다 → 이 과정을 반복하여 multi-chain을 만든다.
생성된 multi-chain의 일부를 sampling하고 이를 기반으로 meta-reasoning을 수행한다. 이때는 multi-chain을 생성했던 것과 다른 모델이 사용된다.
- 결과
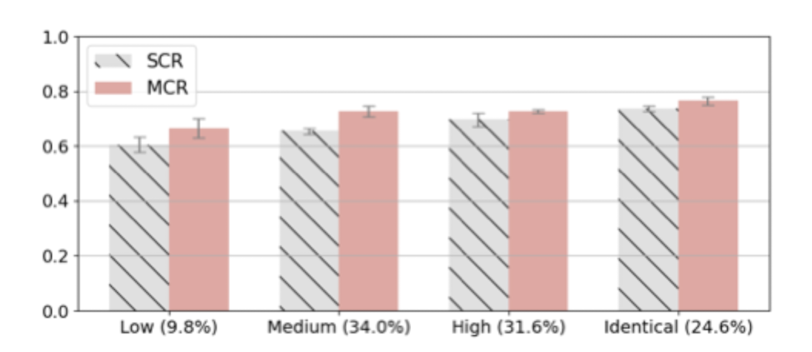
모든 논문들은 항상 자신들의 모델이 좋다고 광고하는 것이라 사실 큰 의미는 없다.
다만 비교 대상 중에 single-chain reasoning(SCR)이 있었는데, 이에 비해서는 확실히 우월한 성능을 나타냈다는 것이 주목할만한 점이다.
당연히 100%라는 것은 없지만 CoT 방식에 있어서 최소한으로 필요한 step이 존재한다고 이해할 수 있을 것 같다.
- 개인적 감상
👍🏻
사실 CoT 방식(Step by step)이 모델의 performance를 끌어올리는데 엄청 도움이 된다는 것은 잘 알려져 있다.
그래서 개인적으로 나중에 LLM과 관련한 실험을 해보더라도 이런 것들을 직접 잘 만들어서 tuning을 해보고 싶은 마음이 있었는데, 이 방식(MCR)을 활용해보면 좋을 것이라는 생각이 들었다.
최근 LLM을 경량화했을 때도 LLM과 동일한 성능이 발현된다는 것은 사실 LLM의 capacity가 엄청나게 크고 커버할 수 있는 범위가 크다는 뜻이다.
그렇기 때문에 기존에 버려지던(고려되지 않던) CoT의 중간 step들을 학습 대상으로 추가하여 보다 높은 정확도와 모델 성능 향상으로 이어지게 된 것이 아닐까 싶다.
👎🏻
한편 생각보다는 open domain QA라고 보기에 약~간 아쉬운 느낌이 들었던 것 같다.
결국 최신 wiki 탐색 정보를 기반으로 답을 뽑아 온다는 것인데, 사실 retrieval 접근 방식이 적용되면, 지금 우리가 생각하고 있는 생성 방식의 QA 수준에 근접하지 못할 가능성이 높아 보인다.
물론 학습이 되어 있거나 검색이 가능한 범위라면 우월한 성능을 보이겠지만, 범위를 벗어나는 순간 완전히 바보가 되어버리는..?
그래서 이게 open domain QA를 제대로 검증한게 맞나 싶었다.
(내가 잘 파악하지 못한 것일 수도 있지만..!)
출처 : https://arxiv.org/abs/2304.13007
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanis
arxiv.org