
지난 주에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
제목 그대로 RMT 기법을 적용하여 트랜스포머가 1,000,000개의 토큰을 입력으로 받을 수 있도록 한다.
배경
transformer 기반의 모델들의 엄청난 성능이 입증된 이후 사실상 transformer로 모든 걸 해결하는 추세다.
하지만 attention 메커니즘은 구조적으로 quadratic complexity(복잡도가 이차식)를 요하기 때문에 input의 길이가 상당히 제한된다는 한계점을 지니고 있다.
이를 극복하기 위해 RMT(Recurrent Memory Transformer)라는 기법을 적용한다.
Recurrent Memory Transforemr(RMT)
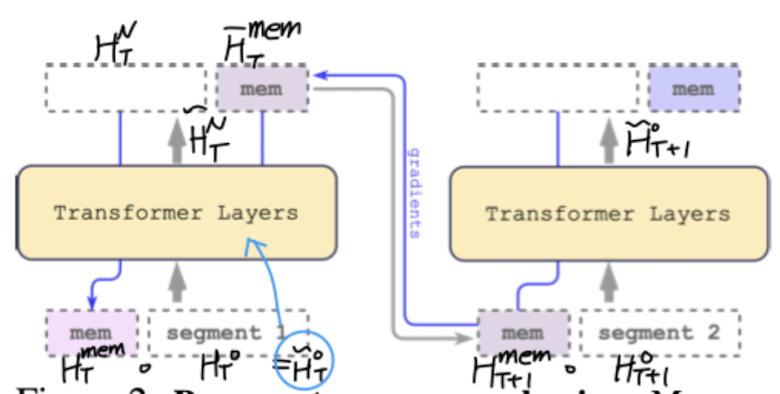
아주 간단히 설명하면 입력 문장(segment)에 memory를 붙여서 transformer layer에 통과시키고, 이를 통해 나온 결과물 중 memory에 관한 것을 다음 layer에 입력으로 넣는 Recurrent 구조라고 볼 수 있다.
여기서 입력 sequence를 segment로 쪼개어 attention 행렬을 한꺼번에 계산하여, 입력 길이가 증가하더라도 시간 복잡도가 선형적으로 증가할 수 있도록 했다.
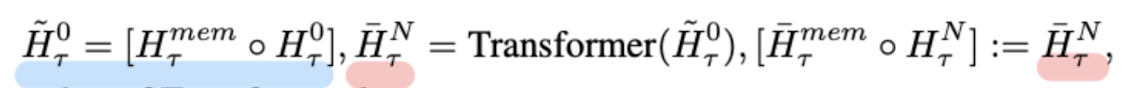
여러 태스크
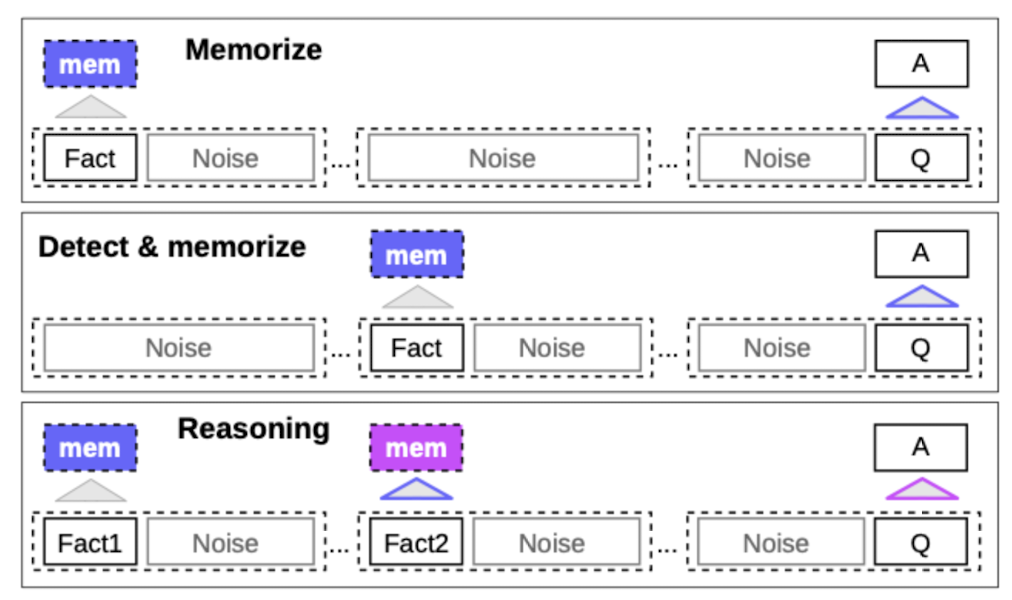
크게 세 가지 방식으로 모델의 성능을 검증했다.
- Fact Memorization : 맨 앞에 fact, 중간 sequence, 맨 끝에서 질문
- Fact Detection & Memorization : fact random 위치, 맨 끝에서 질문
- Reasoning with Memorized Facts : fact 2개, 맨 끝에서 질문
향후 방향성
본 논문에서는 OPT를 중심으로 실험을 했는데, 이를 제외한 다른 모델들(아무래도 범용적으로 더 많이 쓰이는 것들)에 대해서도 적용 가능한 기법이 될 수 있도록 추가 연구가 가능할 것이라 언급했다.
개인적 감상
👍🏻
이 논문에서 강조하고 싶은 것처럼, 엄청난 길이의 입력을 받지만 추가 소요 시간이 선형적으로 증가한다는 것은 엄청나게 획기적이라고 느껴진다.
말 그대로 transformer 아키텍쳐 기반의 모델들의 한계를 극복하는 방법을 제시했기 때문에, 이를 다양한 모델들에 적용만 가능하다면 정말 유용할 것으로 보인다.
특히 최근에 사람들의 관심이 가장 많이 쏠리는 분야인 챗봇, 그리고 챗봇의 과거 응답에 대한 기억력 등에 지대한 영향을 줄 수도 있을 것이라는 생각이 들었다.
개인적으로도 ChatGPT 등의 서비스를 이용하며 느낀 대표적인 아쉬운 점이 ‘입력 길이의 제한’과 ‘과거 정보에 대한 기억력’ 문제였기 때문이다.
👎🏻
논문 저자들이 스스로 한계를 밝히지 않은 것 자체도 아쉬운 점이라는 생각이 든다.
개인적으로는 이 논문에서 검증한 태스크는 난이도가 너무 낮다고 느껴졌다.
특히 fact와 question의 위치가 고정되어 있는 형태라서 더욱 그렇다.
중간 sequence가 아무리 길어져도 앞과 뒤만 기억하면 되는 방식이라면 이러한 태스크에만 적합할 수밖에 없다고 생각한다.
물론 fact의 위치를 섞는 태스크도 있지만, 이를 랜덤하게 배치하게 되면 transformer의 attention 메커니즘에 어떤 영향이 갈 지에 대해서는 고려하지 않은 것일까 싶은 생각도 들었다.
출처 : https://arxiv.org/pdf/2304.11062.pdf
'Paper Review' 카테고리의 다른 글
지난 주에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
제목 그대로 RMT 기법을 적용하여 트랜스포머가 1,000,000개의 토큰을 입력으로 받을 수 있도록 한다.
배경
transformer 기반의 모델들의 엄청난 성능이 입증된 이후 사실상 transformer로 모든 걸 해결하는 추세다.
하지만 attention 메커니즘은 구조적으로 quadratic complexity(복잡도가 이차식)를 요하기 때문에 input의 길이가 상당히 제한된다는 한계점을 지니고 있다.
이를 극복하기 위해 RMT(Recurrent Memory Transformer)라는 기법을 적용한다.
Recurrent Memory Transforemr(RMT)
아주 간단히 설명하면 입력 문장(segment)에 memory를 붙여서 transformer layer에 통과시키고, 이를 통해 나온 결과물 중 memory에 관한 것을 다음 layer에 입력으로 넣는 Recurrent 구조라고 볼 수 있다.
여기서 입력 sequence를 segment로 쪼개어 attention 행렬을 한꺼번에 계산하여, 입력 길이가 증가하더라도 시간 복잡도가 선형적으로 증가할 수 있도록 했다.
여러 태스크
크게 세 가지 방식으로 모델의 성능을 검증했다.
- Fact Memorization : 맨 앞에 fact, 중간 sequence, 맨 끝에서 질문
- Fact Detection & Memorization : fact random 위치, 맨 끝에서 질문
- Reasoning with Memorized Facts : fact 2개, 맨 끝에서 질문
향후 방향성
본 논문에서는 OPT를 중심으로 실험을 했는데, 이를 제외한 다른 모델들(아무래도 범용적으로 더 많이 쓰이는 것들)에 대해서도 적용 가능한 기법이 될 수 있도록 추가 연구가 가능할 것이라 언급했다.
개인적 감상
👍🏻
이 논문에서 강조하고 싶은 것처럼, 엄청난 길이의 입력을 받지만 추가 소요 시간이 선형적으로 증가한다는 것은 엄청나게 획기적이라고 느껴진다.
말 그대로 transformer 아키텍쳐 기반의 모델들의 한계를 극복하는 방법을 제시했기 때문에, 이를 다양한 모델들에 적용만 가능하다면 정말 유용할 것으로 보인다.
특히 최근에 사람들의 관심이 가장 많이 쏠리는 분야인 챗봇, 그리고 챗봇의 과거 응답에 대한 기억력 등에 지대한 영향을 줄 수도 있을 것이라는 생각이 들었다.
개인적으로도 ChatGPT 등의 서비스를 이용하며 느낀 대표적인 아쉬운 점이 ‘입력 길이의 제한’과 ‘과거 정보에 대한 기억력’ 문제였기 때문이다.
👎🏻
논문 저자들이 스스로 한계를 밝히지 않은 것 자체도 아쉬운 점이라는 생각이 든다.
개인적으로는 이 논문에서 검증한 태스크는 난이도가 너무 낮다고 느껴졌다.
특히 fact와 question의 위치가 고정되어 있는 형태라서 더욱 그렇다.
중간 sequence가 아무리 길어져도 앞과 뒤만 기억하면 되는 방식이라면 이러한 태스크에만 적합할 수밖에 없다고 생각한다.
물론 fact의 위치를 섞는 태스크도 있지만, 이를 랜덤하게 배치하게 되면 transformer의 attention 메커니즘에 어떤 영향이 갈 지에 대해서는 고려하지 않은 것일까 싶은 생각도 들었다.
출처 : https://arxiv.org/pdf/2304.11062.pdf