
Sequence to sequence model
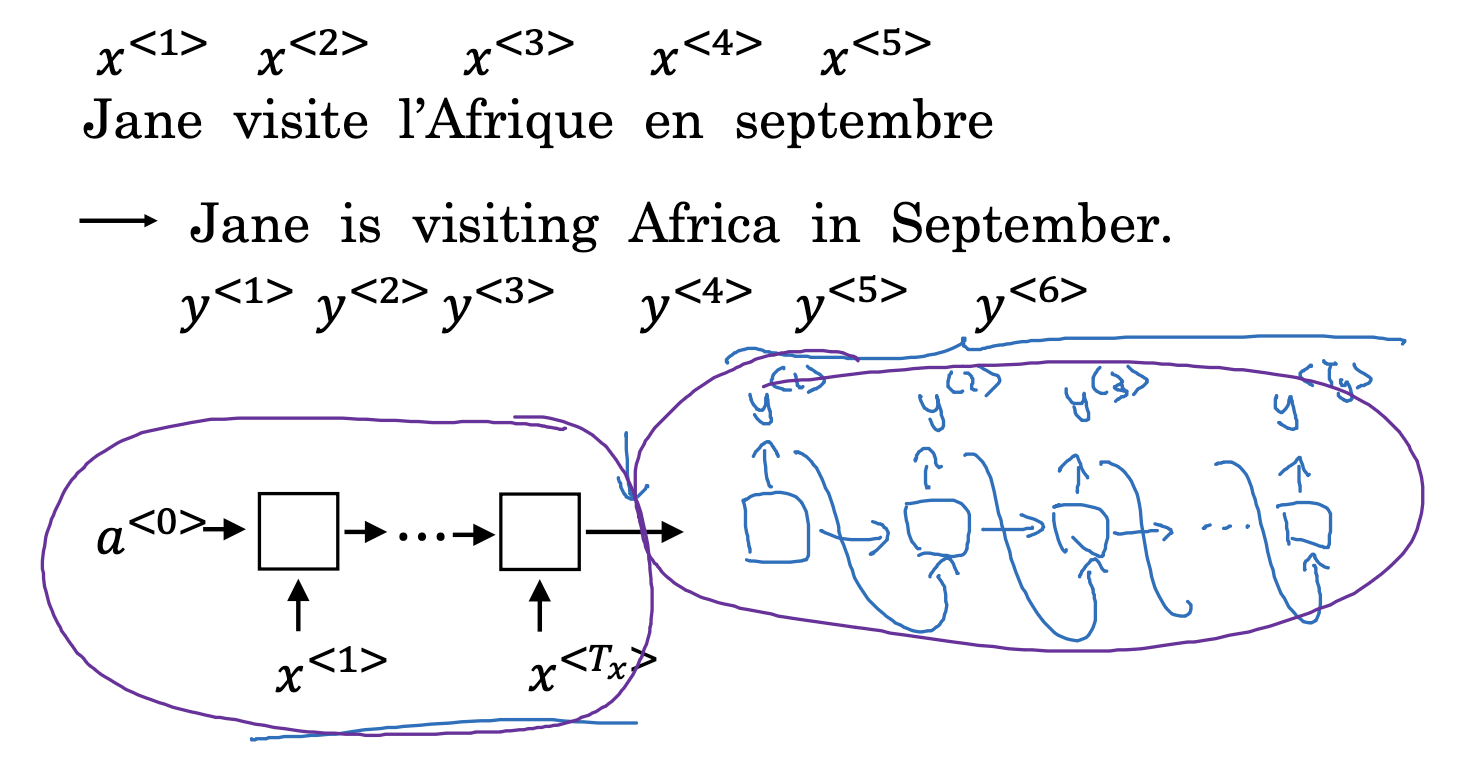
여러 개를 입력으로 받고 여러 개를 출력하는 형태의 sequence to sequence 모델의 대표적인 예는 machine translation입니다.
기계 번역을 위한 학습 방식에는 여러 가지가 존재하지만,
초기에는 위처럼 입력을 쭉 받고, 이후에 예측 결과를 생성하면서 이를 입력으로 다시 제공하는 방식을 취했습니다.
Image captioning
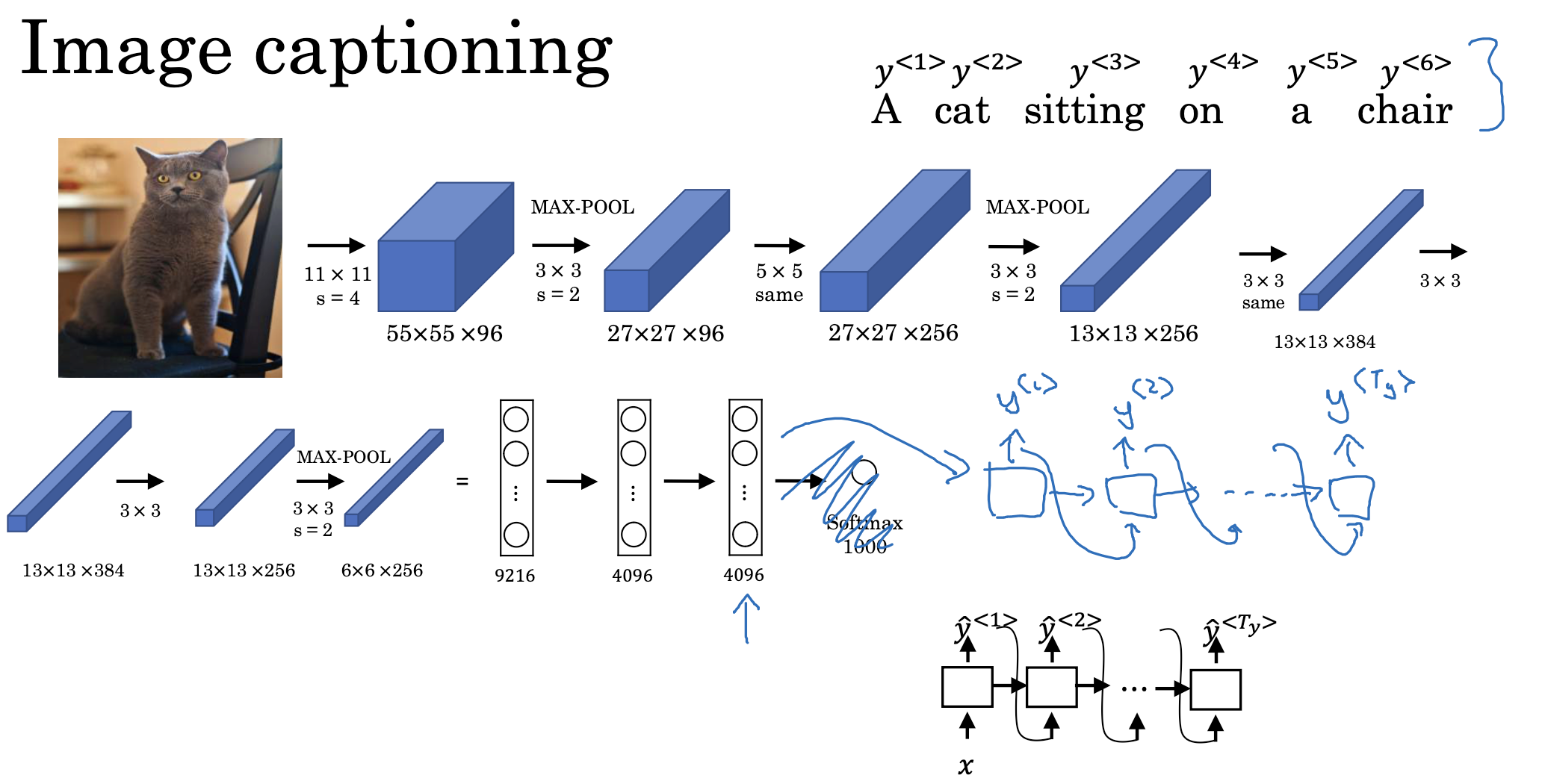
sequence to sequence를 image captioning에 응용한 예시입니다.
이미지에 대한 feature를 최종적으로 4096차원의 벡터로 표현하는 CNN 모델입니다.
원래는 이 벡터에 softmax를 적용하여 확률을 추출해내지만,
우리가 하고 싶은 것은 이미지에 적합한 문장을 생성하는 것이므로 예측 결과를 생성, 그리고 이를 다시 입력으로 제공하는 방식을 그대로 적용하면 됩니다.
출처: Coursera, Sequence Models, DeepLearning.AI