
Machine translation as building a conditional language model
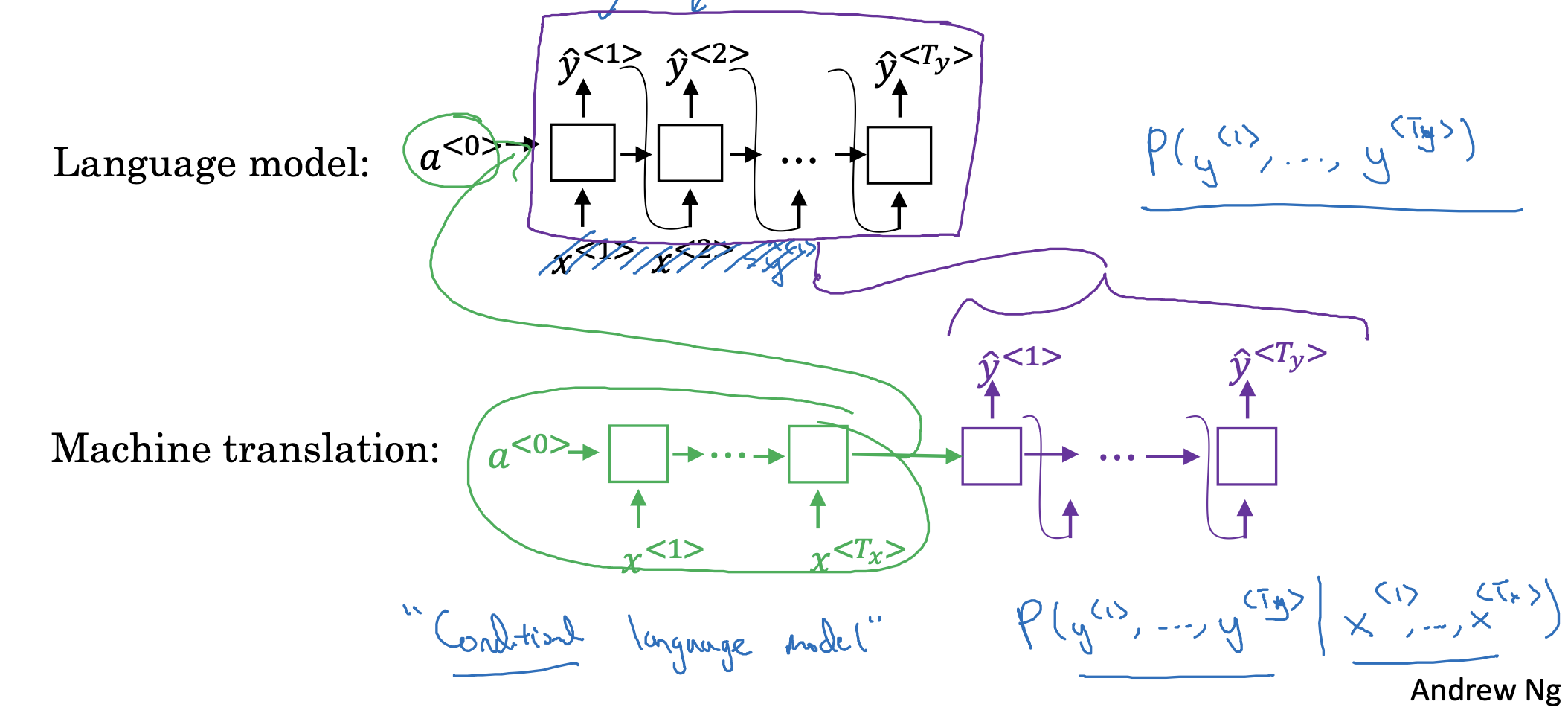
지난 시간에 공부한 machine translation이 이전에 배운 language model의 구조와 유사한 부분이 있다는 것을 시각적으로 확인할 수 있습니다.
machine translation에서는 input x가 예측값 y hat과 동시에 입력으로 들어가지 않는 다는 점을 제외하면 구조가 유사합니다.
그리고 이러한 구조를 'contional language model'이라고 부릅니다.
input x라는 조건이 주어졌을 때, 예측값 y hat을 확률에 기반하여 예측하기 때문이죠.
Finding the most likely translation

하지만 결국 확률의 문제이기 때문에, 주어진 조건 하나로 여러 개의 정답 후보가 있을 수 있습니다.
우리는 그중에서 정답이 될 확률이 가장 높은 것 하나를 골라야 합니다.
Why not a greedy search?
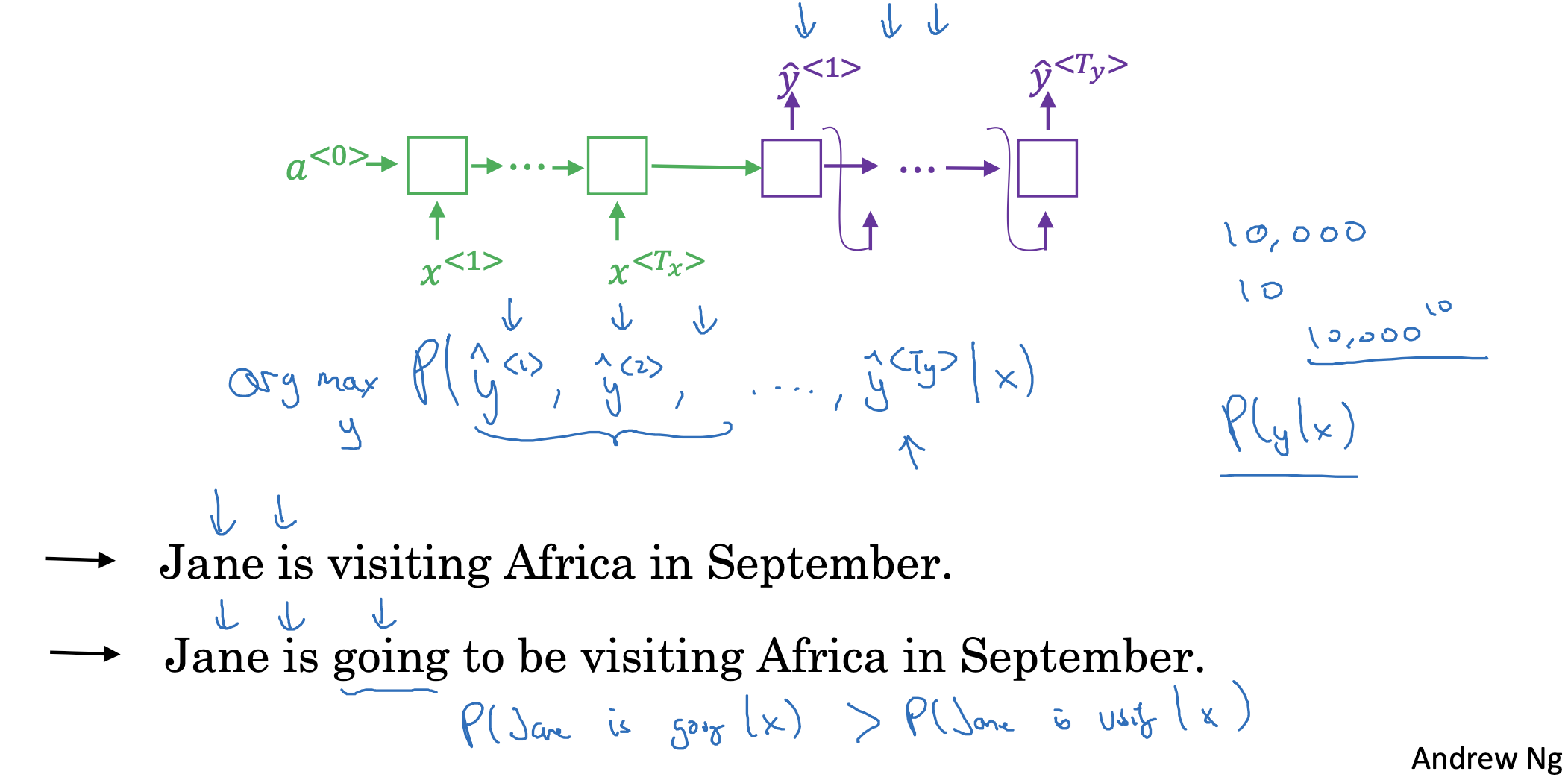
그렇다면 매 시점에서 다음으로 등장할 확률이 가장 높은 것을 고르는 greedy search를 적용하면 안 되는 이유는 무엇일까요?
번역 예시 두 문장을 살펴보면 위의 문장이 더 정확히 잘 번역된 문장입니다.
하지만 영어 문장의 특성상, 'Jane is'라는 표현이 주어지면(condition), 'going'이 등장할 확률이 'visiting'이 등장할 확률보다 높을 것입니다.
따라서 다음에 등장할 확률이 가장 높은 것만 고르게 된다면 결국 맥락과 무관하거나 상대적으로 부정확한 번역이 될 가능성이 높은 것입니다.
이러한 문제점을 해결하기 위해 등장한 탐색 방식 중 하나가 Beam Search 입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 3주차' 카테고리의 다른 글
Machine translation as building a conditional language model
지난 시간에 공부한 machine translation이 이전에 배운 language model의 구조와 유사한 부분이 있다는 것을 시각적으로 확인할 수 있습니다.
machine translation에서는 input x가 예측값 y hat과 동시에 입력으로 들어가지 않는 다는 점을 제외하면 구조가 유사합니다.
그리고 이러한 구조를 'contional language model'이라고 부릅니다.
input x라는 조건이 주어졌을 때, 예측값 y hat을 확률에 기반하여 예측하기 때문이죠.
Finding the most likely translation
하지만 결국 확률의 문제이기 때문에, 주어진 조건 하나로 여러 개의 정답 후보가 있을 수 있습니다.
우리는 그중에서 정답이 될 확률이 가장 높은 것 하나를 골라야 합니다.
Why not a greedy search?
그렇다면 매 시점에서 다음으로 등장할 확률이 가장 높은 것을 고르는 greedy search를 적용하면 안 되는 이유는 무엇일까요?
번역 예시 두 문장을 살펴보면 위의 문장이 더 정확히 잘 번역된 문장입니다.
하지만 영어 문장의 특성상, 'Jane is'라는 표현이 주어지면(condition), 'going'이 등장할 확률이 'visiting'이 등장할 확률보다 높을 것입니다.
따라서 다음에 등장할 확률이 가장 높은 것만 고르게 된다면 결국 맥락과 무관하거나 상대적으로 부정확한 번역이 될 가능성이 높은 것입니다.
이러한 문제점을 해결하기 위해 등장한 탐색 방식 중 하나가 Beam Search 입니다.
출처: Coursera, Sequence Models, DeepLearning.AI