
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST AI]
- multi-hop 태스크에서 기존의 bi-encoder 방식이 지닌 한계를 입증
- retrieval target이 되는 text sequence 전체를 생성함으로써 multi-hop retrieval 태스크를 수행
- GPU memory & Storage footprint 효율성이 높음
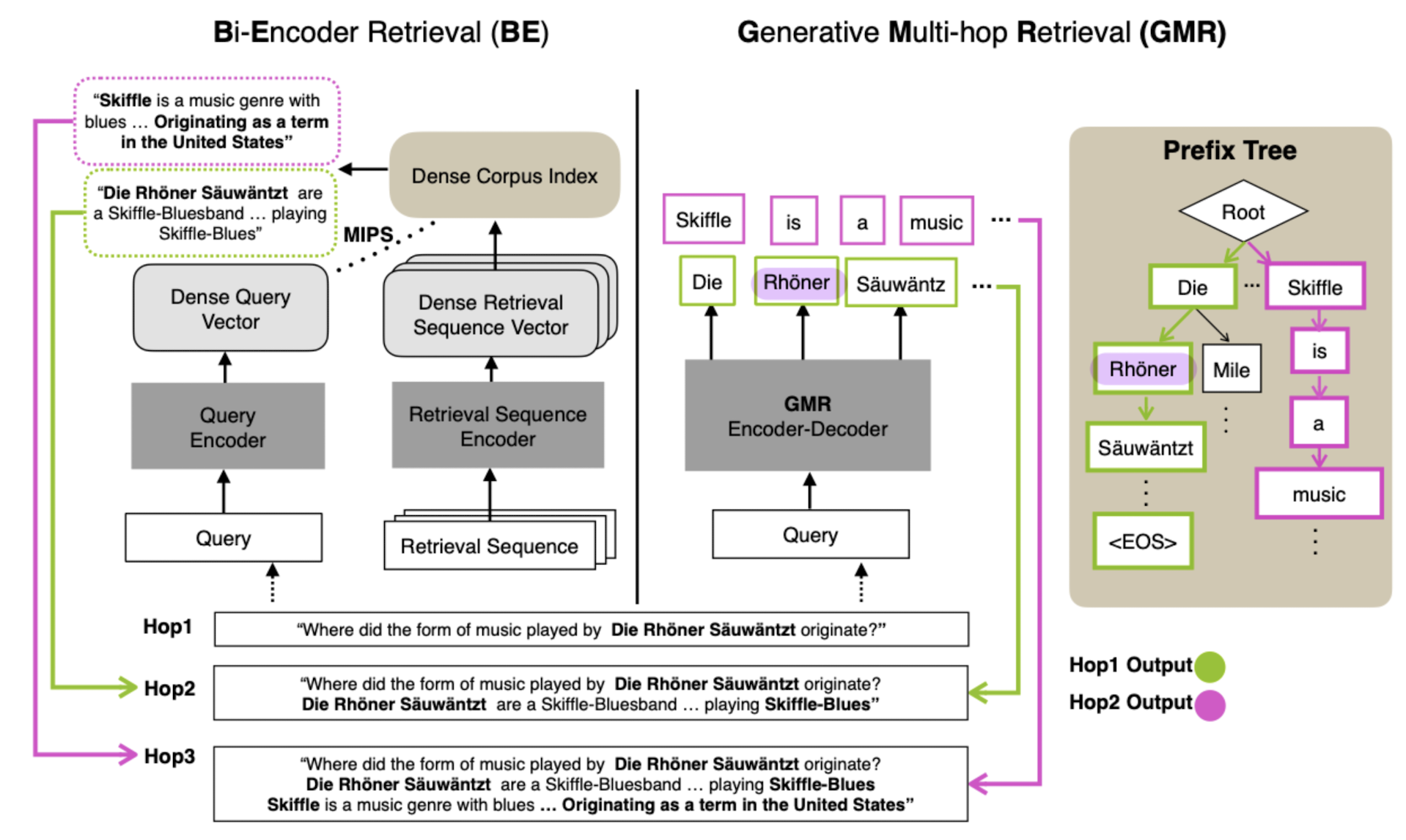
- 배경
- text retrieval 문제는 지금까지 주로 query와 관련성이 높은 paragraph 또는 document 하나를 찾는 것에 집중해왔음
- 이를 위해서 query와 retrieval sequence 둘 다 공통의 vector space로 encoding하고 이를 저장해야 했음
- 그에 따라 heavy computation 문제가 발생할 뿐만 아니라, input의 길이가 길어지는 multi-hop 문제를 제대로 처리할 수 없게 됨
- Related Works
- Multi-hop Retrieval: 여러 개의 문서를 통합함으로써 query에 답하는 방식. bi-encoder는 bottleneck problem을 겪음
- Generative Retrieval: DSI, SEAL (Search Engine with Autoregressive LMs)
- Contributions
- multi-hop retrieval task에서 bi-encoder retrieval이 지니는 한계를 입증: hop의 수가 증가할수록 성능이 하락하고 error propagation에 취약해짐
- Generative Multi-hop Retrieval (GMR)이 multi-hop retrieval 문제를 푸는데 강건하면서도 뛰어난 성능을 보인다는 것을 확인
- GMR의 성능을 향상시키고 target corpus를 잘 기억하도록 만들기 위한 multi-hop memorization을 도입
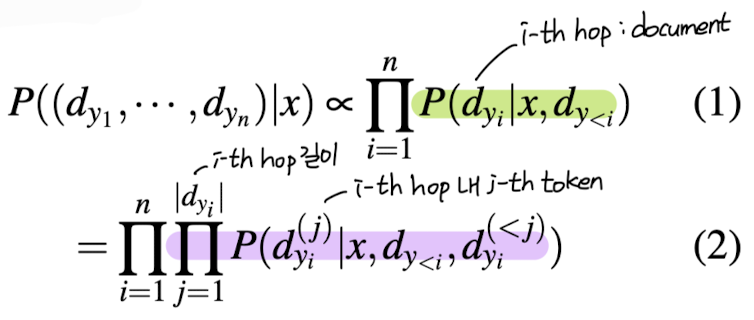
- Generative Multi-hop Retrieval (GMR)
- augmented query를 형성하기 위해 이전에 retrieved된 sequence가 query에 appended
- bi-encoder를 사용하는 경우 hop이 증가함에 따라 append 해야 하는 sequence가 길어지며 bottleneck 문제를 겪게 됨
- 생성된 sequence가 corpus 내에 존재함을 보장할 수 있도록 prefix tree를 build하고 constrained decoding을 적용
- training set이 target corpus를 포함하지 않을 경우 발생하는 문제점을 완화하기 위해 두 가지 memorization 기법을 제안
- 1) LM Memorization
- 모델 스스로 생성하는 sequence의 끝이 어디인지 aware하도록 학습
- 처음 m개의 토큰이 encoder의 input으로 주어질 때 문서 d가 등장할 확률을 maximize
- 2) Multi-hop Memorization
- pseudo multi-hop query와 pseudo target sequence로부터 D'이 등장할 확률을 maximize
- 기존 target corpus D에서 추출한 pseudo target sequence D_y'을 query generator Q에 입력으로 제공하여 pseudo query x'을 획득
- Benchmarks
- HotpotQA, Entailment TreeBank (EntailBank), StrategyQA, Explagraphs-Open (EG-Open), RuleTaker-Open (RT-Open)
- Model and Baselines
- bi-encoder retrieval model (BE): MDR, ST5
- Metrics
- fixed multi-hop: MDR evaluation metric, recall rate (R@k)
- dynamic multi-hop: F1 score (F1@k), graph construction success rate
- Analysis
- 1) Limitation of Bi-Encoder Retrieval Models: bottleneck problem, error propagation
- 2) Effect on Unseen Rate of GMR: bi-encoder 대비 엄청난 성능 향상
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST AI]
- multi-hop 태스크에서 기존의 bi-encoder 방식이 지닌 한계를 입증
- retrieval target이 되는 text sequence 전체를 생성함으로써 multi-hop retrieval 태스크를 수행
- GPU memory & Storage footprint 효율성이 높음
- 배경
- text retrieval 문제는 지금까지 주로 query와 관련성이 높은 paragraph 또는 document 하나를 찾는 것에 집중해왔음
- 이를 위해서 query와 retrieval sequence 둘 다 공통의 vector space로 encoding하고 이를 저장해야 했음
- 그에 따라 heavy computation 문제가 발생할 뿐만 아니라, input의 길이가 길어지는 multi-hop 문제를 제대로 처리할 수 없게 됨
- Related Works
- Multi-hop Retrieval: 여러 개의 문서를 통합함으로써 query에 답하는 방식. bi-encoder는 bottleneck problem을 겪음
- Generative Retrieval: DSI, SEAL (Search Engine with Autoregressive LMs)
- Contributions
- multi-hop retrieval task에서 bi-encoder retrieval이 지니는 한계를 입증: hop의 수가 증가할수록 성능이 하락하고 error propagation에 취약해짐
- Generative Multi-hop Retrieval (GMR)이 multi-hop retrieval 문제를 푸는데 강건하면서도 뛰어난 성능을 보인다는 것을 확인
- GMR의 성능을 향상시키고 target corpus를 잘 기억하도록 만들기 위한 multi-hop memorization을 도입
- Generative Multi-hop Retrieval (GMR)
- augmented query를 형성하기 위해 이전에 retrieved된 sequence가 query에 appended
- bi-encoder를 사용하는 경우 hop이 증가함에 따라 append 해야 하는 sequence가 길어지며 bottleneck 문제를 겪게 됨
- 생성된 sequence가 corpus 내에 존재함을 보장할 수 있도록 prefix tree를 build하고 constrained decoding을 적용
- training set이 target corpus를 포함하지 않을 경우 발생하는 문제점을 완화하기 위해 두 가지 memorization 기법을 제안
- 1) LM Memorization
- 모델 스스로 생성하는 sequence의 끝이 어디인지 aware하도록 학습
- 처음 m개의 토큰이 encoder의 input으로 주어질 때 문서 d가 등장할 확률을 maximize
- 2) Multi-hop Memorization
- pseudo multi-hop query와 pseudo target sequence로부터 D'이 등장할 확률을 maximize
- 기존 target corpus D에서 추출한 pseudo target sequence D_y'을 query generator Q에 입력으로 제공하여 pseudo query x'을 획득
- Benchmarks
- HotpotQA, Entailment TreeBank (EntailBank), StrategyQA, Explagraphs-Open (EG-Open), RuleTaker-Open (RT-Open)
- Model and Baselines
- bi-encoder retrieval model (BE): MDR, ST5
- Metrics
- fixed multi-hop: MDR evaluation metric, recall rate (R@k)
- dynamic multi-hop: F1 score (F1@k), graph construction success rate
- Analysis
- 1) Limitation of Bi-Encoder Retrieval Models: bottleneck problem, error propagation
- 2) Effect on Unseen Rate of GMR: bi-encoder 대비 엄청난 성능 향상