
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[LK Lab]
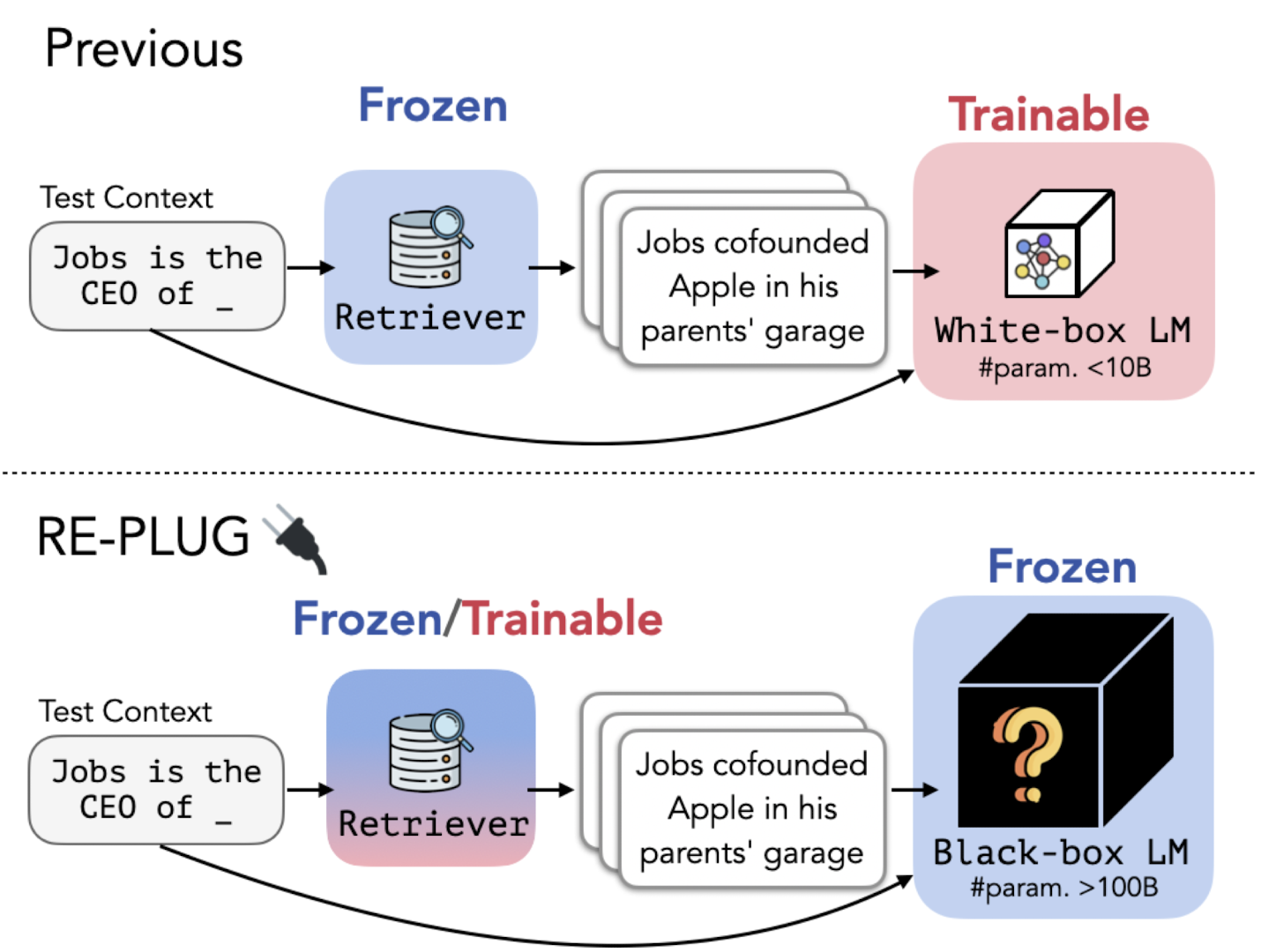
- Language Model은 블랙박스 취급하고 tuneable retrieval model로 증강 효과를 누리는 Retrieval-Augmented Language Modeling Framework, REPLUG
- frozen 블랙박스 LM에 retrieved documents를 prepend하는 방식
- LM은 retrieval model을 supervise하는 데 활용될 수 있음
- LLM은 뛰어난 능력을 가지고 있지만 hallucination을 보이거나 long tail에 해당하는 knowledge에 대해서는 약세를 보이는 문제점이 여전히 존재함
- Related Works
- Black-box Language Models: 오픈 소스 모델들도 아니고 상업적으로 이용도 불가능한 모델들
- Retrieval-Augmented Models: encoder-decoder, decoder-only models
- REPLUG(REtrieve and PLUG)
- 1) off-the-shelf retrieval model(Contriever)을 사용하여 외부 corpus로부터 관련 문서 k개를 탐색
- 2) 탐색된 문서는 input context에 prepend 되어 블랙박스 LM에 전달
- 3) 탐색된 문서에 대해 동일한 모델로 병렬 처리를 수행하고 그 결과를 앙상블하는 scheme
- retriever를 LM에 adapt하는 방식. 기존에는 그 반대였기에 더 많은 연산량을 요구했음.
- Document Retriever
- 각 문서(d)와 쿼리(x)의 임베딩 벡터 간 코사인 유사도를 구함
- 그 값이 가장 높은 k개의 문서(documents)를 추출
- 각 문서(d)에 대한 임베딩 벡터를 미리 구하여 FAISS INDEX를 구축함으로써 추론 시간을 단축
- Input Reformulation
- k개의 retrieved 문서(d)와 쿼리(x)를 concatenate 했을 때, 정답 y가 등장할 확률을 계산
- k개의 결과에 대해 ensemble 수행
- REPLUG LSR: Training the Dense Retriever
- 1) 문서를 retrieve한 뒤 retrieval likelihood를 계산한다
- 2) LM으로 retrieved 문서에 대한 score를 구한다
- 3) 'retrieval likelihood'와 'LM's score distribution' 간의 KL-divergence를 최소화하는 방향으로 retrieval model의 파라미터를 업데이트한다
- 4) datastore index를 비동기 업데이트한다
- Experiments
- Language Modeling: 'GPT-3, GPT-2 family' on Pile Dataset
- MMLU: 'Codex', PaLM, Flan-PaLM on MMLU
- Open Domain QA: Chinchilla, PaLM, 'Codex' on Natural Questions(NQ) and TriviaQA
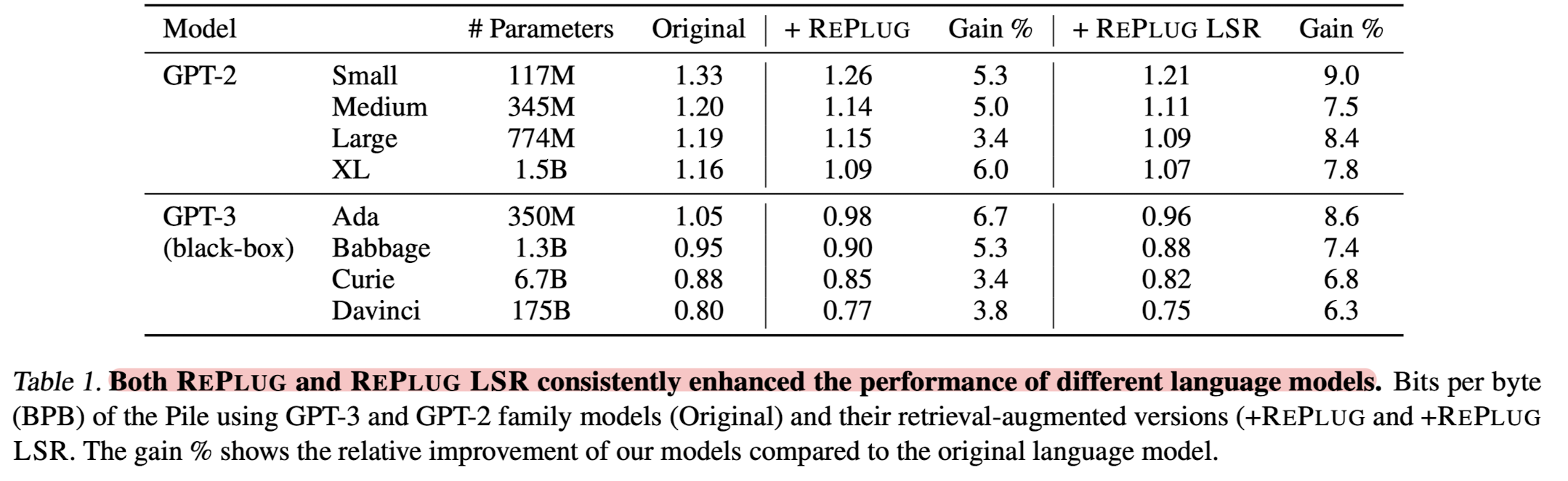
출처 : https://arxiv.org/abs/2301.12652
REPLUG: Retrieval-Augmented Black-Box Language Models
We introduce REPLUG, a retrieval-augmented language modeling framework that treats the language model (LM) as a black box and augments it with a tuneable retrieval model. Unlike prior retrieval-augmented LMs that train language models with special cross at
arxiv.org