
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST, LG AI Research, Knokuk University, Seoul National University, University of Illinois Chicago]
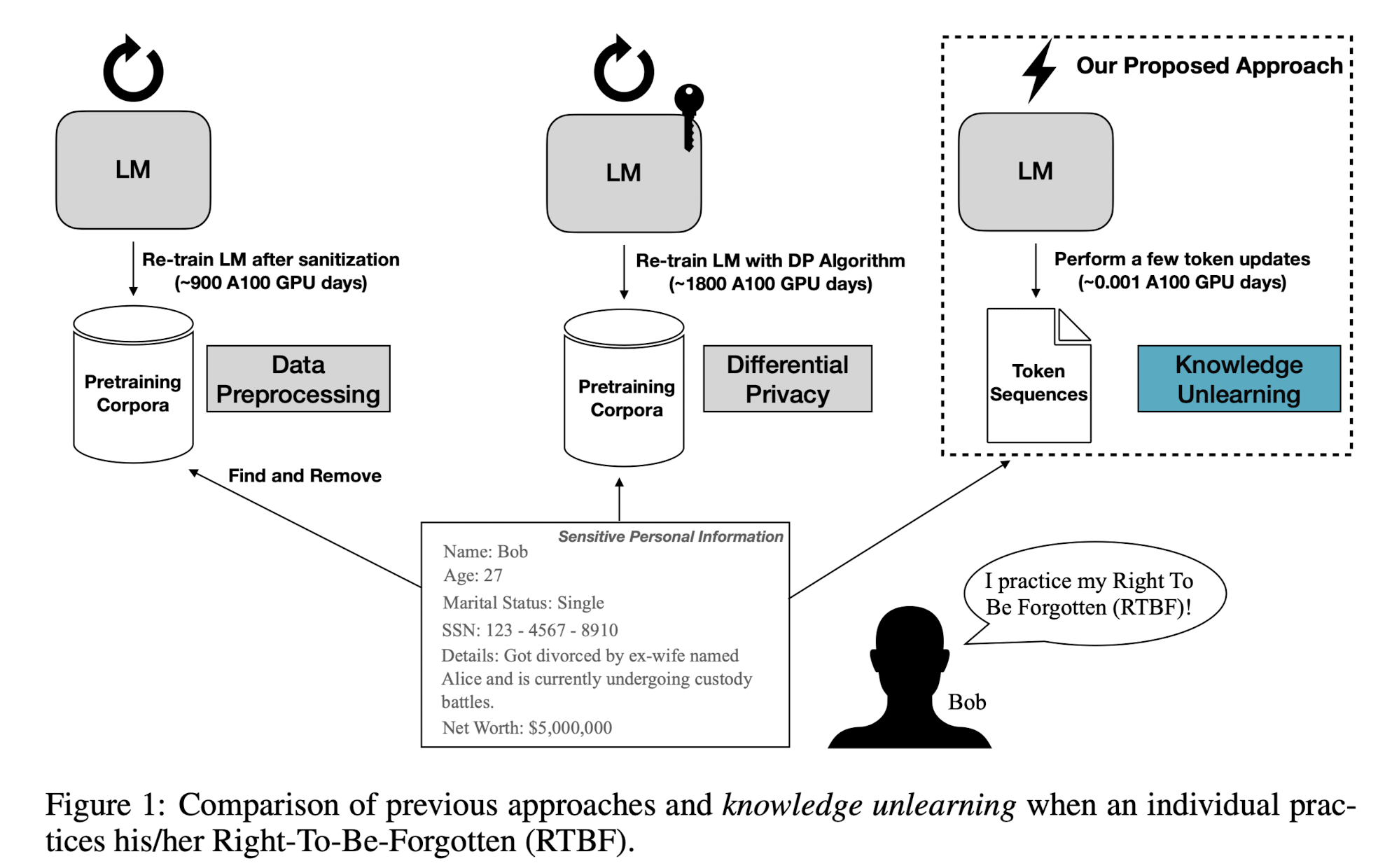
- LM이 지난 privacy risk를 줄여주기 위한 대안으로 knowledge unlearning을 제안
- target sequence에 대해 gradient ascent를 적용하는 것만으로도 모델의 성능 하락 없이 forgetting을 쉽게 달성할 수 있음
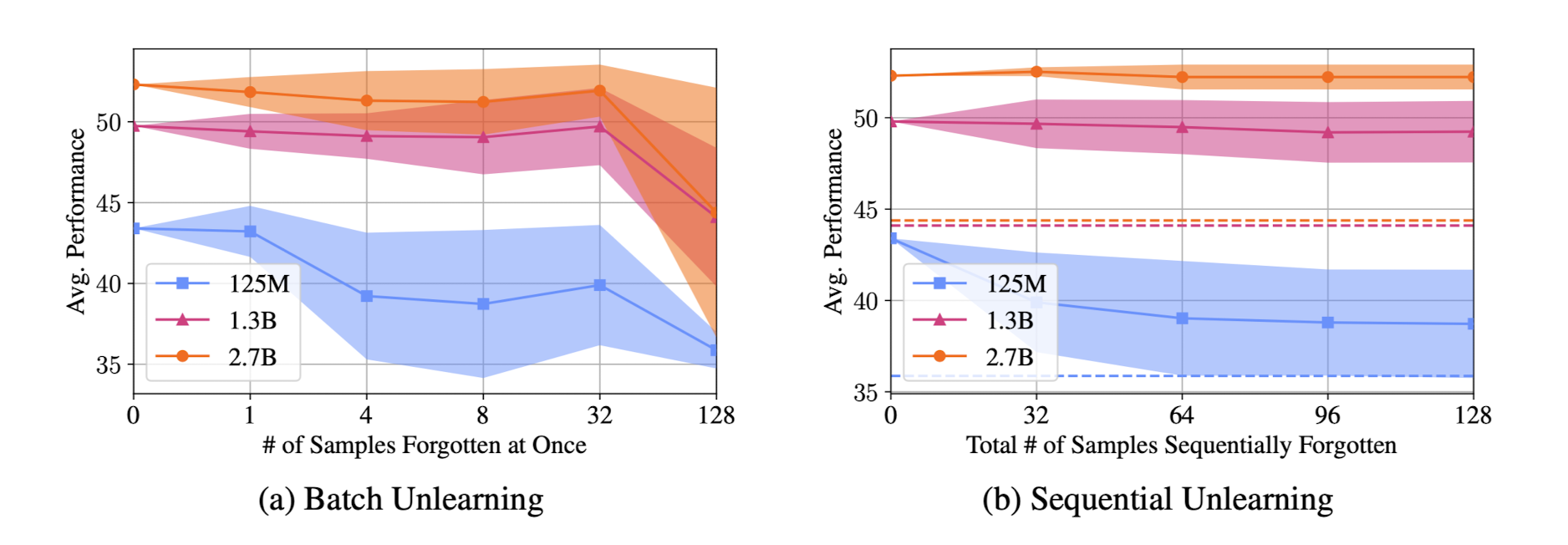
- sequential unlearning이 모든 데이터를 한꺼번에 처리하는 것보다 더 바람직한 결과로 이어짐
- 배경
- 사전 학습된 언어 모델이 이름, 전화 번호 등의 Personally Identifiable Information (PII)를 보유하고 있다는 문제가 제기됨
- 이와 같은 문제를 해결하기 위해 Large LM에 대한 privacy 보장 문제가 화두로 떠오르게 되었음
- 기존 방식은 크게 pre-/post-processing & Differential Privacy (DP)로 나뉨
- Contributions
- 기존 preprocessing/DP Decoding 방식에 비해 뛰어난 knowledge unlearning을 제시 (성능 하락 없이 forgetting 성공)
- 한꺼번에 많은 샘플을 forget하려고 하면 모델 성능이 심각하게 저해됨 & forget에 있어서 target data의 domain이 중요한 역할을 함 (도메인에 따라 forget이 쉬운 경우, 그렇지 않은 경우가 있음 - 구조화된 데이터는 쉽게 forget되지 않음)
- 새로운 metric과 guideline을 통해 LM이 지닌 privacy risk를 정량화
- Related Works
- (Data) Pre/Post-Processing: 모델 학습 이전에 privacy를 침해하는 어떤 종류의 데이터든지 제거하는 것을 목표로 함 / 한계를 극복하기 위해 censorship이 도입됨
- Differential Privacy: 특정 함수의 결과에 대해 개별 입력이 미치는 영향이 구속되는 것을 보장하기 위한 방식
- Machine Unlearning: 머신 러닝 분야에서 data privacy issue를 해결하기 위한 대안으로 제시됨
- Memorization in Language Models: 언어 모델이 파라미터에 individual privacy를 담고 있다는 점에 대해 부정/긍적적인 시각이 대립
- Knowledge Unlearning for Language Models
- training objective: maximizing loss function (log likelihood)
- Metric 1: Extraction Likelihood (EL), Metric 2: Memorization Accuracy (MA)
- Empirical Definition of Forgetting: EL과 MA 값이 각각 평균 EL/MA 값보다 작은 경우 앞으로 forgotten 되어야 할 대상임. 즉, 추출 가능성 or 기억 정확도가 테스트셋 평균보다 높기 때문에 아직 forgotten 되지 않은 것으로 판단한다는 뜻
- Baselines
- GPT-NEO, OPT LMs
- Benchmarks
- 9 classification tasks & 4 dialogue tasks, perplexity
- 🧐
- 특정 패턴이 있는 이메일이나 코드와 같은 '구조화된' 데이터를 갖는 도메인에 대해서는 unlearning이 잘 수행되지 않았다고 함.
- 그 이유가 뭘까? 그리고 잊기 어렵다는 것은 그만큼 학습이 쉽다는 것을 의미하는 것 같기도 하다. 그렇다면 이런 도메인에 대해서는 학습 속도가 빠른 편일까?
- 또 이것은 학습이 잘 되어있다는 뜻인데, 이런 데이터셋에 대해서는 기존의 예측 정확도도 상대적으로 높아야 하는 것 아닐까?
출처 : https://arxiv.org/abs/2210.01504
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly foc
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST, LG AI Research, Knokuk University, Seoul National University, University of Illinois Chicago]
- LM이 지난 privacy risk를 줄여주기 위한 대안으로 knowledge unlearning을 제안
- target sequence에 대해 gradient ascent를 적용하는 것만으로도 모델의 성능 하락 없이 forgetting을 쉽게 달성할 수 있음
- sequential unlearning이 모든 데이터를 한꺼번에 처리하는 것보다 더 바람직한 결과로 이어짐
- 배경
- 사전 학습된 언어 모델이 이름, 전화 번호 등의 Personally Identifiable Information (PII)를 보유하고 있다는 문제가 제기됨
- 이와 같은 문제를 해결하기 위해 Large LM에 대한 privacy 보장 문제가 화두로 떠오르게 되었음
- 기존 방식은 크게 pre-/post-processing & Differential Privacy (DP)로 나뉨
- Contributions
- 기존 preprocessing/DP Decoding 방식에 비해 뛰어난 knowledge unlearning을 제시 (성능 하락 없이 forgetting 성공)
- 한꺼번에 많은 샘플을 forget하려고 하면 모델 성능이 심각하게 저해됨 & forget에 있어서 target data의 domain이 중요한 역할을 함 (도메인에 따라 forget이 쉬운 경우, 그렇지 않은 경우가 있음 - 구조화된 데이터는 쉽게 forget되지 않음)
- 새로운 metric과 guideline을 통해 LM이 지닌 privacy risk를 정량화
- Related Works
- (Data) Pre/Post-Processing: 모델 학습 이전에 privacy를 침해하는 어떤 종류의 데이터든지 제거하는 것을 목표로 함 / 한계를 극복하기 위해 censorship이 도입됨
- Differential Privacy: 특정 함수의 결과에 대해 개별 입력이 미치는 영향이 구속되는 것을 보장하기 위한 방식
- Machine Unlearning: 머신 러닝 분야에서 data privacy issue를 해결하기 위한 대안으로 제시됨
- Memorization in Language Models: 언어 모델이 파라미터에 individual privacy를 담고 있다는 점에 대해 부정/긍적적인 시각이 대립
- Knowledge Unlearning for Language Models
- training objective: maximizing loss function (log likelihood)
- Metric 1: Extraction Likelihood (EL), Metric 2: Memorization Accuracy (MA)
- Empirical Definition of Forgetting: EL과 MA 값이 각각 평균 EL/MA 값보다 작은 경우 앞으로 forgotten 되어야 할 대상임. 즉, 추출 가능성 or 기억 정확도가 테스트셋 평균보다 높기 때문에 아직 forgotten 되지 않은 것으로 판단한다는 뜻
- Baselines
- GPT-NEO, OPT LMs
- Benchmarks
- 9 classification tasks & 4 dialogue tasks, perplexity
- 🧐
- 특정 패턴이 있는 이메일이나 코드와 같은 '구조화된' 데이터를 갖는 도메인에 대해서는 unlearning이 잘 수행되지 않았다고 함.
- 그 이유가 뭘까? 그리고 잊기 어렵다는 것은 그만큼 학습이 쉽다는 것을 의미하는 것 같기도 하다. 그렇다면 이런 도메인에 대해서는 학습 속도가 빠른 편일까?
- 또 이것은 학습이 잘 되어있다는 뜻인데, 이런 데이터셋에 대해서는 기존의 예측 정확도도 상대적으로 높아야 하는 것 아닐까?
출처 : https://arxiv.org/abs/2210.01504
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly foc
arxiv.org