관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST AI, Kakao]
- 현존하는 generative retrieval model에 모두 적용 가능한 Nonparametric Decoding (Np Decoding)을 제안
- Np Decoding은 nonparametric contextualized vocab embedding (external memory)를 사용
- 배경
- Text Retrieval에서 bi-encoder를 사용하는 방식은 embedding space bottleneck과 large storage space 문제가 존재
- 최근 인기를 끌고 있는 generative retrieval 방식은 encoding한 모든 정보를 parameter에 담게 되면서 한계가 명확
- Contributions
- 현존하는 모든 generative retrieval 모델에 적용 가능한 nonparametric decoding 기법을 제안;
이때, parametric & nonparametric space를 둘 다 활용 - 다양한 CE Encoder (Contextualized Embedding Encoder)를 제시하고, contrastive learning으로 학습된 CE Encoder가 성능을 크게 향상시킬 수 있음을 확인
- Np Decoding을 사용하는 generative retrieval models 방식은 data- & parameter- efficient 하다는 것을 입증
- 현존하는 모든 generative retrieval 모델에 적용 가능한 nonparametric decoding 기법을 제안;
- Related Works
- Generative Retreival: 전체 sequence 또는 식별자(identifier)의 일부를 생성하여 관련성이 높은 아이템을 retrieve
- Memory Augmented Models
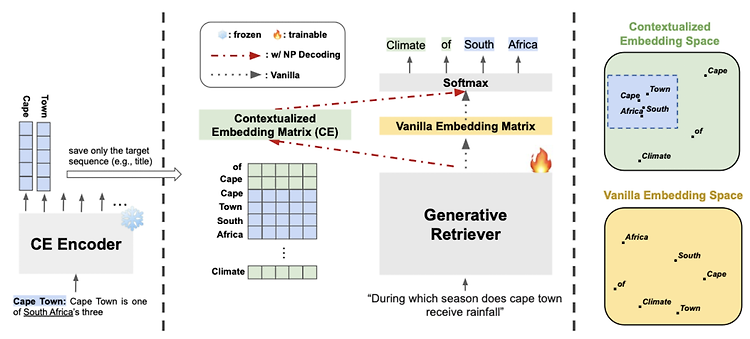
- Nonparametric Decoding (Np Decoding)
- Benefits
- parametric space에 encoded된 정보 뿐만 아니라 nonparmaetric space에 encoded된 contextualized vocab embedding까지 활용
- vanilla decoding에 비해 more expressive & fine-grained decoder voab embedding space를 가짐
- Base Nonparametric Decoding
- pre-traeind T5 encoder를 그대로 사용
- Async Nonparametric Decoding (ASYNC)
- generative retrieval이 학습하는 동안에는, CE Encoder는 frozen 상태이므로 대체 가능하며 generative retriever만 학습 가능
- CE Encoder를 주기적으로 replace 함으로써 CE Encoder와 generative retriever 간의 conherency를 유지
- Contrastive Nonparametric Decoding
- token-level contrastive learning으로 학습된 CE Encoder를 사용
- generative retrieval task에 대해 T5를 학습하기 전 중간 단계로 이해할 수 있음
- 1) Token-level Contrastive Learning -> 2) Generative Retrieval
- Clustering
- clustering을 통해 embedding의 숫자를 줄여 representative embeddings의 숫자를 줄일 수 있음 -> 대신 업데이트가 어려워진다는 묹
- k centroid embedding을 토큰의 decoder vocab embeddings으로 사용
- Benefits
- Baselines
- BM25, DPR, Sentence-T5, MDR
- Datasets & Metrics
- FEVER, AY2, TREX, zsRE, NQ, TQA, WOW, NQ-320K, HotpotQA
- R-precision, Hits@N
- 🧐
- clustering을 통해 저장된 embedding을 최소화하는 방식을 취하고 있다. 그렇기 때문에 기존의 pre-constructed CE에 새로운 contextualized token embedding를 더하기 어렵다. 즉, 모든 embedding에 대해 처음부터 clustering을 수행하는 것은 비효율적이므로 업데이트가 어렵다는 뜻.
- 이를 해결하기 위해 pre-constructed CE에 clustering된 결과를 기준으로 새로운 embedding을 특정 cluster로 분류하는 방법은 어떨까 싶음.
다만 어떤 기준으로(평균이 제일 만만하긴 하지만) 분류 작업을 수행할지는 고민해봐야 할 일
출처 : https://arxiv.org/abs/2210.02068
Nonparametric Decoding for Generative Retrieval
The generative retrieval model depends solely on the information encoded in its model parameters without external memory, its information capacity is limited and fixed. To overcome the limitation, we propose Nonparametric Decoding (Np Decoding) which can b
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST AI, Kakao]
- 현존하는 generative retrieval model에 모두 적용 가능한 Nonparametric Decoding (Np Decoding)을 제안
- Np Decoding은 nonparametric contextualized vocab embedding (external memory)를 사용
- 배경
- Text Retrieval에서 bi-encoder를 사용하는 방식은 embedding space bottleneck과 large storage space 문제가 존재
- 최근 인기를 끌고 있는 generative retrieval 방식은 encoding한 모든 정보를 parameter에 담게 되면서 한계가 명확
- Contributions
- 현존하는 모든 generative retrieval 모델에 적용 가능한 nonparametric decoding 기법을 제안;
이때, parametric & nonparametric space를 둘 다 활용 - 다양한 CE Encoder (Contextualized Embedding Encoder)를 제시하고, contrastive learning으로 학습된 CE Encoder가 성능을 크게 향상시킬 수 있음을 확인
- Np Decoding을 사용하는 generative retrieval models 방식은 data- & parameter- efficient 하다는 것을 입증
- 현존하는 모든 generative retrieval 모델에 적용 가능한 nonparametric decoding 기법을 제안;
- Related Works
- Generative Retreival: 전체 sequence 또는 식별자(identifier)의 일부를 생성하여 관련성이 높은 아이템을 retrieve
- Memory Augmented Models
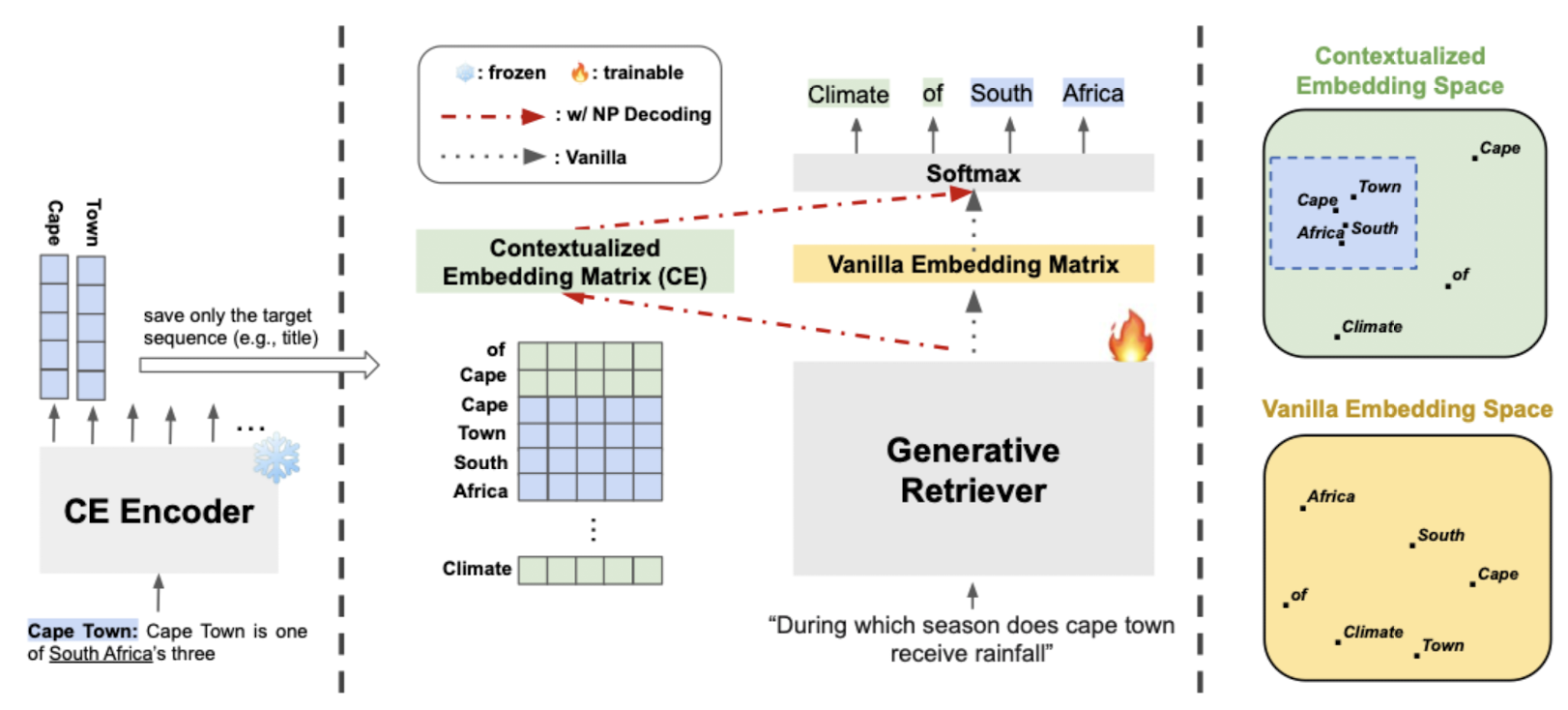
- Nonparametric Decoding (Np Decoding)
- Benefits
- parametric space에 encoded된 정보 뿐만 아니라 nonparmaetric space에 encoded된 contextualized vocab embedding까지 활용
- vanilla decoding에 비해 more expressive & fine-grained decoder voab embedding space를 가짐
- Base Nonparametric Decoding
- pre-traeind T5 encoder를 그대로 사용
- Async Nonparametric Decoding (ASYNC)
- generative retrieval이 학습하는 동안에는, CE Encoder는 frozen 상태이므로 대체 가능하며 generative retriever만 학습 가능
- CE Encoder를 주기적으로 replace 함으로써 CE Encoder와 generative retriever 간의 conherency를 유지
- Contrastive Nonparametric Decoding
- token-level contrastive learning으로 학습된 CE Encoder를 사용
- generative retrieval task에 대해 T5를 학습하기 전 중간 단계로 이해할 수 있음
- 1) Token-level Contrastive Learning -> 2) Generative Retrieval
- Clustering
- clustering을 통해 embedding의 숫자를 줄여 representative embeddings의 숫자를 줄일 수 있음 -> 대신 업데이트가 어려워진다는 묹
- k centroid embedding을 토큰의 decoder vocab embeddings으로 사용
- Benefits
- Baselines
- BM25, DPR, Sentence-T5, MDR
- Datasets & Metrics
- FEVER, AY2, TREX, zsRE, NQ, TQA, WOW, NQ-320K, HotpotQA
- R-precision, Hits@N
- 🧐
- clustering을 통해 저장된 embedding을 최소화하는 방식을 취하고 있다. 그렇기 때문에 기존의 pre-constructed CE에 새로운 contextualized token embedding를 더하기 어렵다. 즉, 모든 embedding에 대해 처음부터 clustering을 수행하는 것은 비효율적이므로 업데이트가 어렵다는 뜻.
- 이를 해결하기 위해 pre-constructed CE에 clustering된 결과를 기준으로 새로운 embedding을 특정 cluster로 분류하는 방법은 어떨까 싶음.
다만 어떤 기준으로(평균이 제일 만만하긴 하지만) 분류 작업을 수행할지는 고민해봐야 할 일
출처 : https://arxiv.org/abs/2210.02068
Nonparametric Decoding for Generative Retrieval
The generative retrieval model depends solely on the information encoded in its model parameters without external memory, its information capacity is limited and fixed. To overcome the limitation, we propose Nonparametric Decoding (Np Decoding) which can b
arxiv.org