
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Technology Innovation Institute, Abu Dhabi]
- Falcon-7/40/180B 모델을 공개
- RefinedWeb 데이터셋 중 600B 토큰을 공개 (전체는 5T 토큰이라고 언급)
- Falcon series에 대한 detailed research
1. Introduction
- 언어 모델의 폭발적인 성장 및 발전은 transformer 아키텍쳐의 scability에 근간을 두고 있습니다. 본 논문에서는 이를 세 가지 관점(axes)에서 살펴보고 있습니다.
- Performance Scability: 사전학습에 들어가는 비용을 늘리는 것이 일관되게 성능 향상으로 이어짐
- Data Scability: large model은 더 오래, 그리고 더 큰 corpora에 대해 학습되어야 함
- Hardware Scability: 학습 비용을 줄이고 추론시 latency를 최소화하는 것이 목표
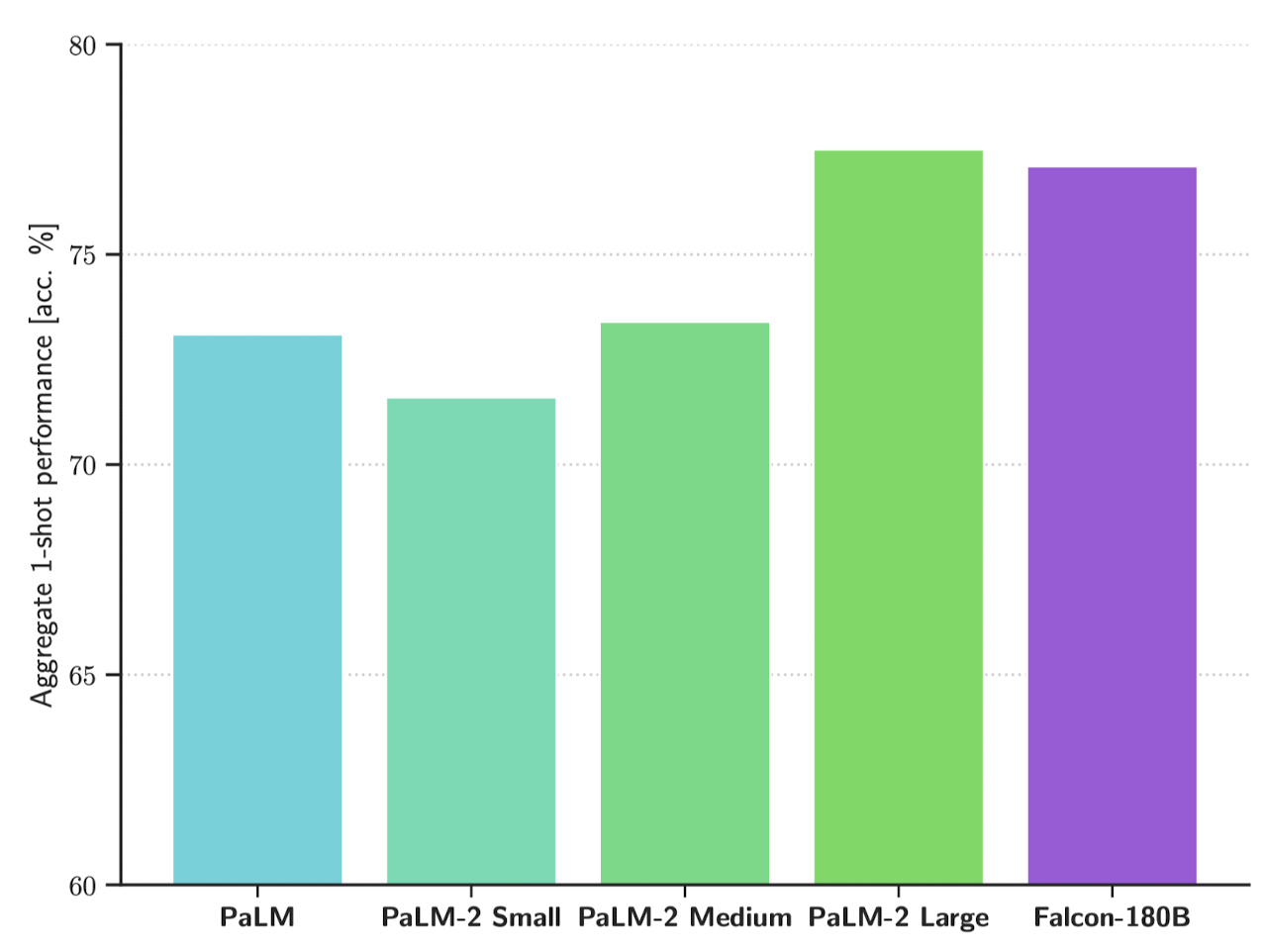
- LLM은 모델에 human preference를 반영, instruction tuning 등을 통해 빠르게 성장했습니다. Falcon series는 지금까지의 LLM 관련 기술들의 총 집약체로, 현재 선두를 달리는 GPT-4, PaLM-2와 견줄 정도의 최고 모델임을 자부하고 있습니다.
2. Related Work
- Language Modeling: 대량의 unstructured text corpora로부터 unsupervised learning을 수행하는 것이 흔해짐
- Transformer Models: attention 기반의 transformer architecture 모델. emergent few-shot generalization ability
- Large Language Models: 모델과 데이터셋 사이즈를 키워 학습하는 것이 모델 성능 향상에 아주 긍정적인 영향
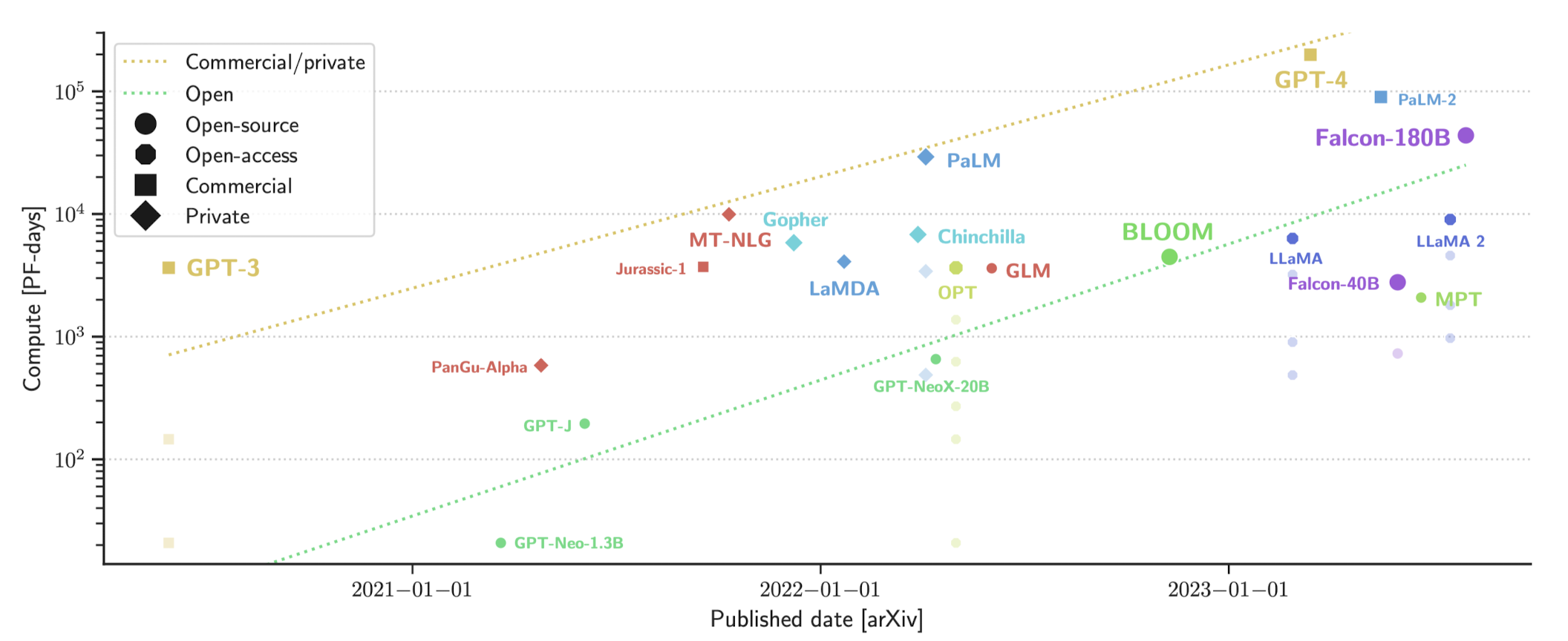
- Frontier Models: GPT-4, PaLM-2
3. Contributions
- Public documentation of the pretraining of a large-scale model
- 최근 SoTA 모델들은 자신들의 학습 방식이나 데이터 등에 대한 정보를 전혀 공개하지 않고 있습니다. Falcon series는 이 분야의 further research와 progress를 위해 공개된 연구 결과물입니다.
- Open data and models
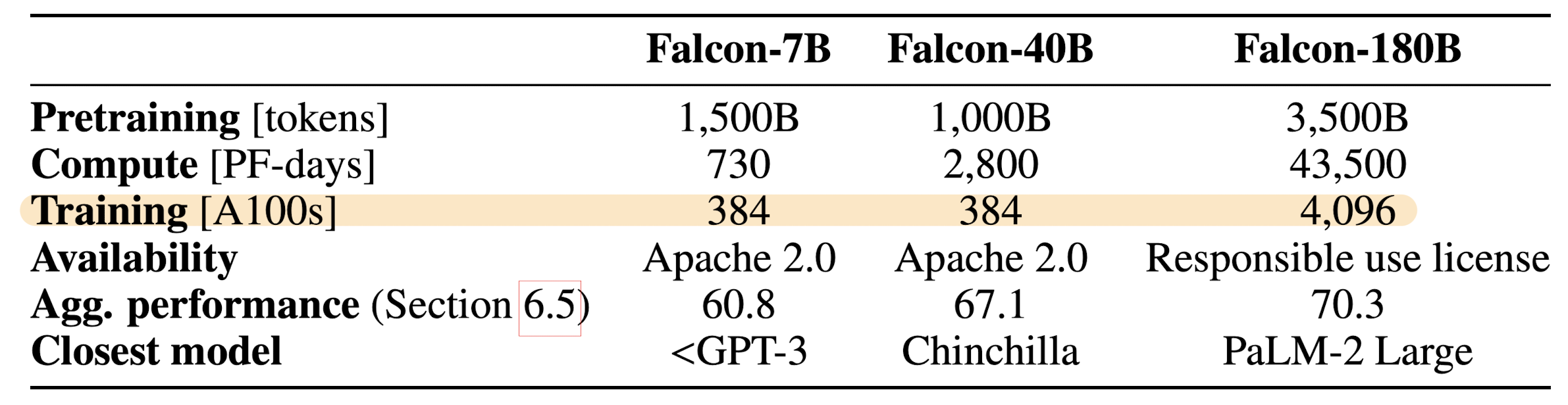
- Falcon-7/40/180B 모델과 RefinedWeb 데이터셋 중 600B 토큰을 공개했습니다.
4. Experiments and motivations for data, architecture, and hyperparameters
실험의 가장 핵심은 어떤 practice가 유효한 것인지 아닌지 판단하기 위해 1B-3B 파라미터 사이즈의 모델을 사용했다는 것입니다.
또한 어떤 기법들을 적용할지 그렇지 않을지를 결정할 때는 모델의 zero-shot 성능을 기준으로 삼고 있습니다.
4.1. Setup for small-scale experiments
- 1/3B for 30/60B 사이즈 모델. 즉 작은 사이즈의 모델에서 유효했던 학습 방식이 큰 사이즈의 모델에서 역시 유효한 것인지 확인하는 방식
- 물론 큰 모델에서 확인된 emergent ability를 생각해보면, 큰 언어 모델에서 기대하는 패턴을 작은 모델에서 발견하지 못할 수도 있음. 또한 작은 모델에서 나타나는 특징이 반드시 큰 언어 모델에서도 확인될 것이라고 장담하기 어렵다는 것도 전제로 삼고 실험을 진행
4.2. Data: web vs curated, code and multilinguality impact on English performance
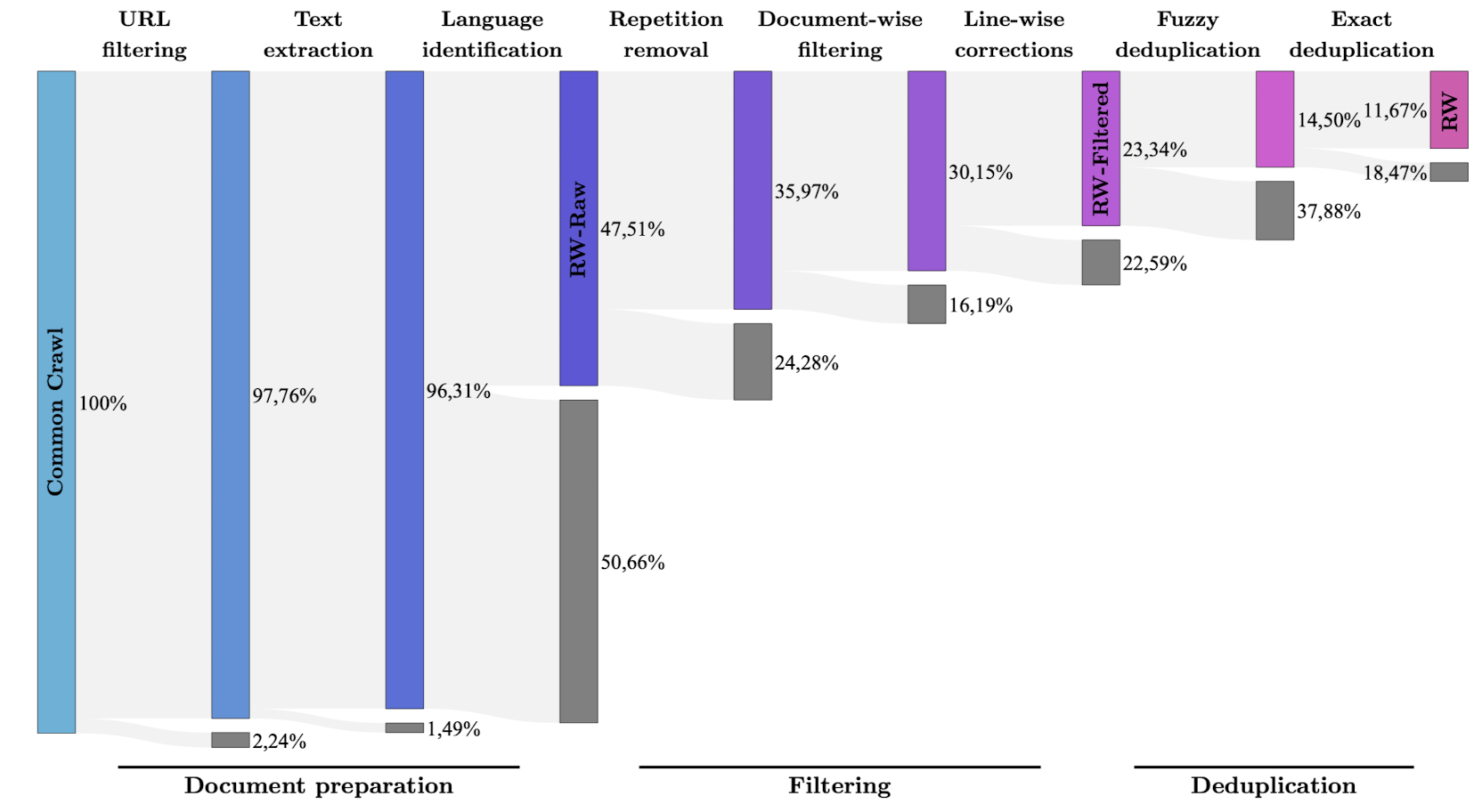
- 실험을 통해 'filtered & deduplicated' web data로 학습된 모델의 성능이 curated data에 대해 학습된 모델의 성능과 동등한 수준임을 확인
- filtering과 deduplication 중에서는 특히 후자를 크게 강조하고 있다는 느낌을 받았음. (중복을 피하기 위해 upscaling을 수행하지 않음 등을 보면서 그런 생각이 듦)
- 따라서 Falcon 모델을 학습할 때는 타모델 대비 Web 데이터의 비중이 Curated보다 훨씬 높은 것을 알 수 있음
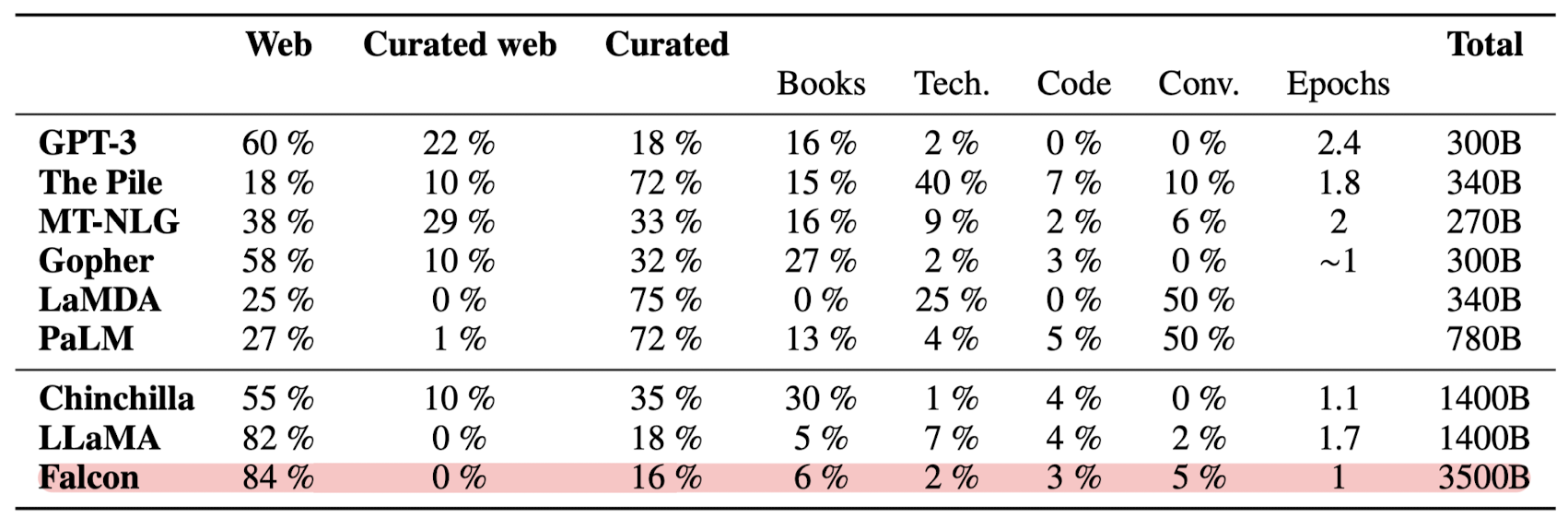
- 코드와 다른 언어(영어 외) 데이터 구성 비중이 미치는 영향을 확인한 결과입니다.
- 코드 데이터와 타언어 데이터를 조금(5/10%) 사용하더라도 zero-shot performance가 떨어지지 않음을 확인했습니다.
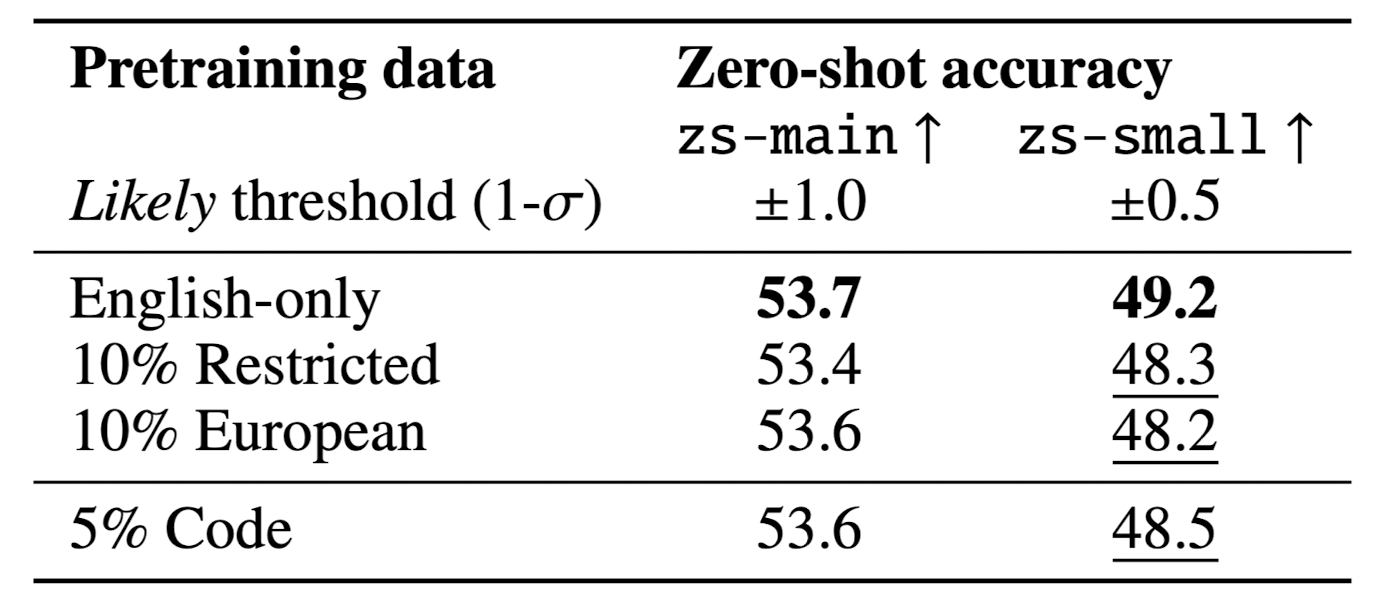
4.3. Architecture and pretraining
- multiquery 대신 multigroup을 사용하여 학습과 추론을 병렬처리함으로써 처리 속도를 향상시켰습니다.
- 이때도 마찬가지로 zero-shot performance의 degradation이 허용 가능한 수준으로 일어납니다.
- Rotary positional embeddings (RoPE)가 ALiBi 대비 조금 더 우수한 성능을 보입니다.
- 활성화 함수로 GLU를 사용하며 메모리를 추가 할당하는 것은 그다지 메리트가 없습니다.
- SwiGLU를 사용하여 실험 진행했습니다.
- parallel layer를 사용하고 bias는 사용하지 않습니다.
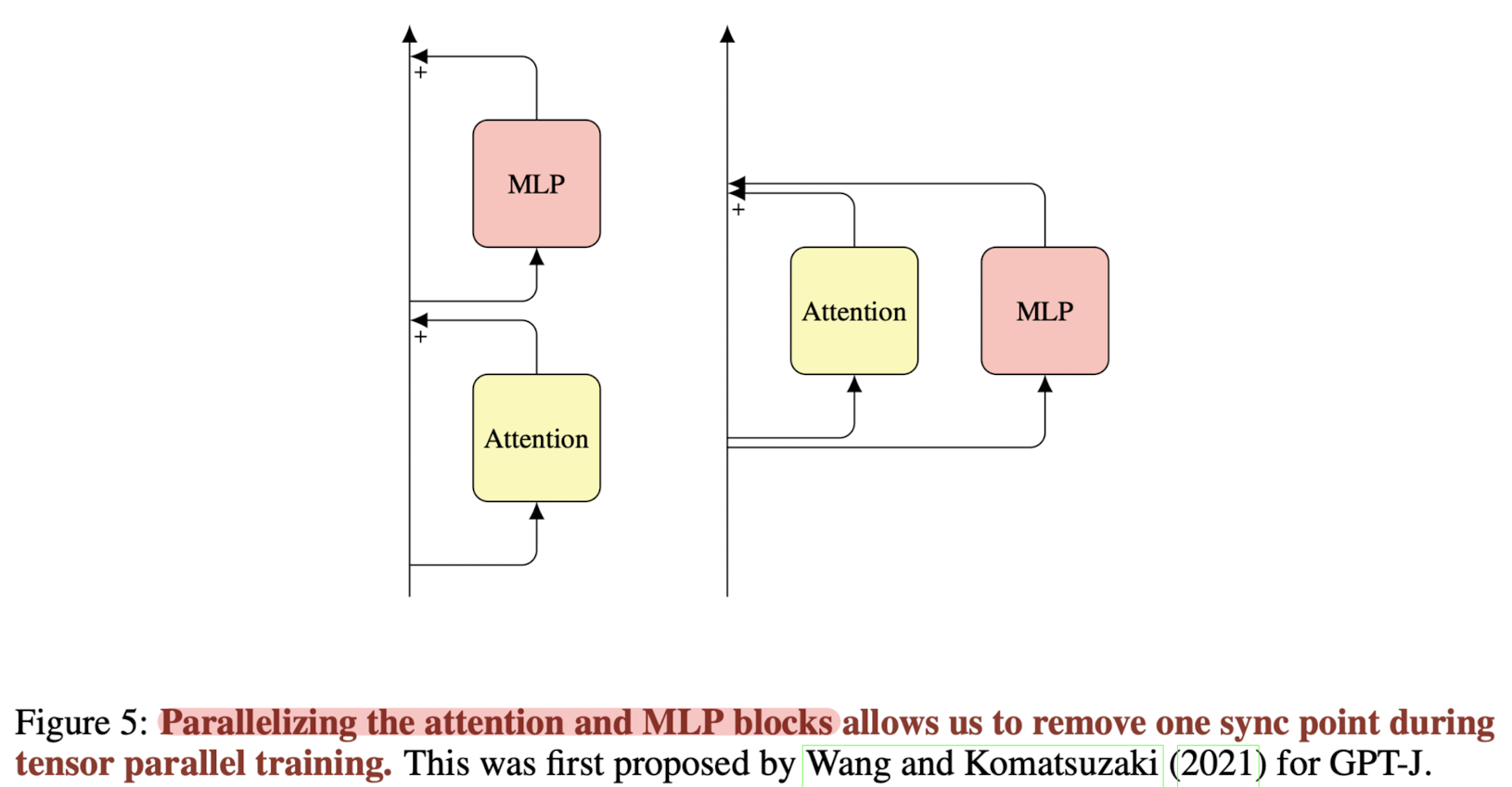
4.4. The Microdata curated corpora and conversational masking
- Conversational data
- 궁극적으로 LLM을 'chatty'하게 만들고 싶기 때문에 대화형 데이터가 필요. 따라서 이를 사전학습 데이터에 포함합니다.
- Reddit으로부터 데이터를 수집했습니다.
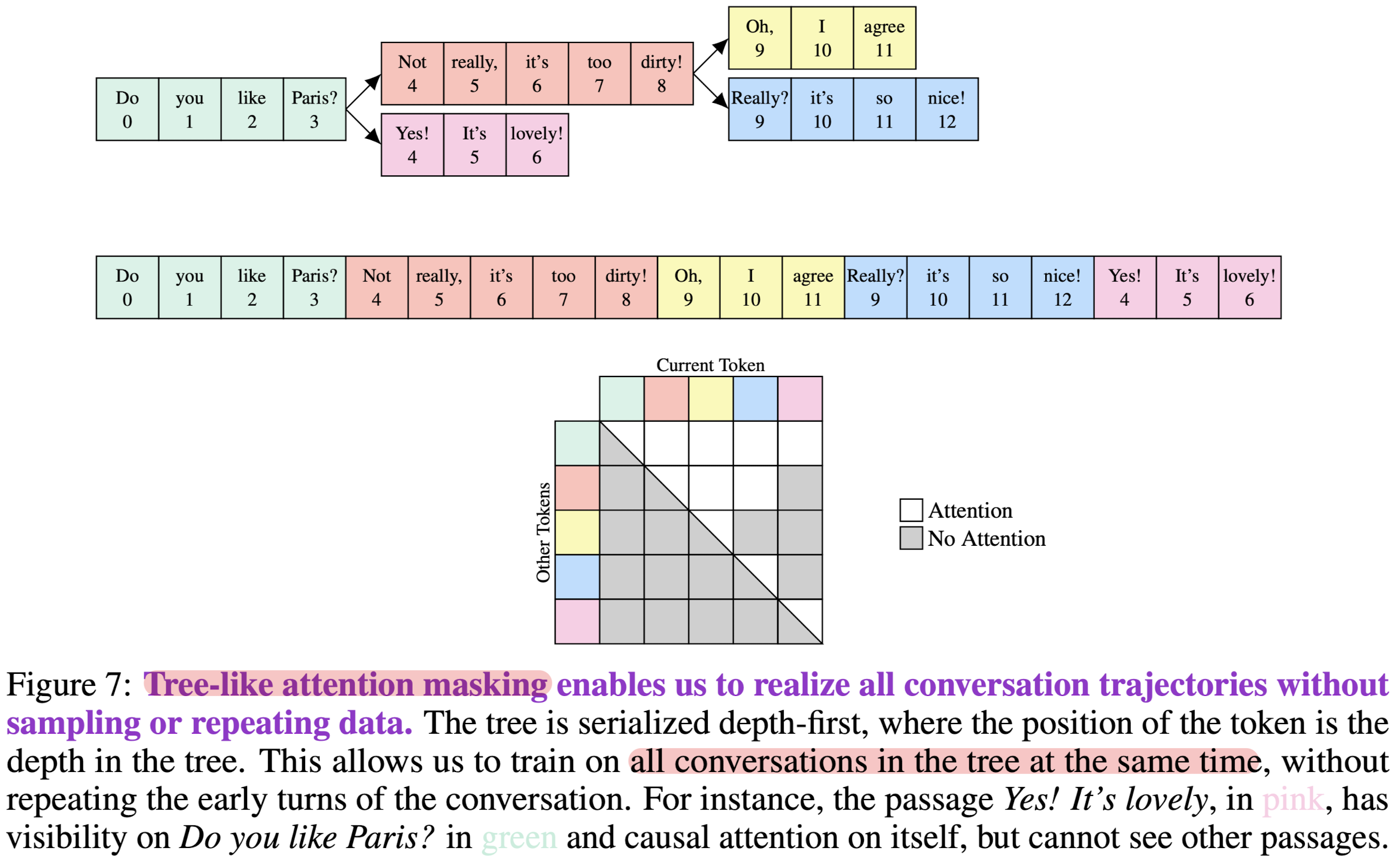
- Conversation tree and attention masking (Tree-like attention masking)
- Reddit과 같은 플랫폼에서 수집되는 데이터는 하나의 대화에 여러 화자의 발화가 뒤섞여 있는 경우가 많습니다.
- 따라서 관계가 있는 대화를 root와 node로 연결하고 서로에 대해서만 attention 가능하도록 masking합니다.
- 아래 예시에서 'Yes! It's lovely!'는 'Do you like Paris?'와 유일하게 관계를 갖고 있으므로 이것만 attention 대상이며 나머지는 making한 것을 알 수 있습니다.
5. Insights
많은 사람들이 대부분의 LLM은 그냥 데이터빨 아닐까, 데이터에 투자할 돈이 많으니까 고품질 데이터셋을 확보해서 학습을 했겠지, 어차피 자원 빨이다, 라는 이야기를 했습니다.
저는 그런 상황들에 대해서 물론 자세히 밝혀진 바는 없으나 그러한 자원을 활용하는 것도 엄청난 역량을 요하는 것이고, 큰 규모의 자원을 충분히 활용하여 원하는 퍼포먼스를 일궈내는 것 자체가 대단하다고 생각하기 때문에 리스펙해야 한다는 입장이었습니다.
그러나 이 논문을 보고 나서 느낀 것은, "현존하는 LLM들은 인공지능 기술의 집약체"라는 점이었습니다.
다른 논문들에서 접할 수 있던 부분적이고 파편과 같은 개념들이 엄청난 노고와 고도화된 기술을 통해 하나로 합쳐져 있다는 생각을 떨칠 수 없었습니다.
예를 들면 embedding에 대해서 어떤 것을 취할지(RoPE vs. ALiBi), 데이터는 웹의 데이터와 curated 된 것 중 어떤 것을 사용할지 등에 대한 내용들이 너무 방대하고 깊다는 생각이 들었습니다.
가장 인상깊었던 것은 어떤 기술이나 방법론이 유의미한지, 그리고 확장 가능한지 확인할 때 생각보다 작은 사이즈의 모델로 학습을 진행한다는 점이었습니다.
이전에 한정된 자원으로 LLM에 대해 어떻게 학습을 진행하는지에 대해 궁금해서 알아본 적이 있었는데, 사이즈가 수백 billion에 달하는 모델을 학습할 때 저정도의 사이즈가 무슨 의미가 있냐, 라는 생각밖에 들지 않았었습니다.
최근 참여한 세미나에서 이에 대해 반전되는 이야기를 듣고 대체 어떤 방식으로 작은 모델에서 LLM의 능력과 방법론의 타당성을 검증할 수 있을지에 대한 사고 방식을 고쳐먹게 되었는데, 관련된 내용이 강조되어서 굉장히 놀라웠습니다.
개인적으로는 지금까지 내가 알고 있던 LLM은 LLM의 근처에 이르지도 못한 것이구나, 라는 자기 반성도 하게 되었습니다..
출처 : https://arxiv.org/abs/2311.16867
The Falcon Series of Open Language Models
We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--t
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Technology Innovation Institute, Abu Dhabi]
- Falcon-7/40/180B 모델을 공개
- RefinedWeb 데이터셋 중 600B 토큰을 공개 (전체는 5T 토큰이라고 언급)
- Falcon series에 대한 detailed research
1. Introduction
- 언어 모델의 폭발적인 성장 및 발전은 transformer 아키텍쳐의 scability에 근간을 두고 있습니다. 본 논문에서는 이를 세 가지 관점(axes)에서 살펴보고 있습니다.
- Performance Scability: 사전학습에 들어가는 비용을 늘리는 것이 일관되게 성능 향상으로 이어짐
- Data Scability: large model은 더 오래, 그리고 더 큰 corpora에 대해 학습되어야 함
- Hardware Scability: 학습 비용을 줄이고 추론시 latency를 최소화하는 것이 목표
- LLM은 모델에 human preference를 반영, instruction tuning 등을 통해 빠르게 성장했습니다. Falcon series는 지금까지의 LLM 관련 기술들의 총 집약체로, 현재 선두를 달리는 GPT-4, PaLM-2와 견줄 정도의 최고 모델임을 자부하고 있습니다.
2. Related Work
- Language Modeling: 대량의 unstructured text corpora로부터 unsupervised learning을 수행하는 것이 흔해짐
- Transformer Models: attention 기반의 transformer architecture 모델. emergent few-shot generalization ability
- Large Language Models: 모델과 데이터셋 사이즈를 키워 학습하는 것이 모델 성능 향상에 아주 긍정적인 영향
- Frontier Models: GPT-4, PaLM-2
3. Contributions
- Public documentation of the pretraining of a large-scale model
- 최근 SoTA 모델들은 자신들의 학습 방식이나 데이터 등에 대한 정보를 전혀 공개하지 않고 있습니다. Falcon series는 이 분야의 further research와 progress를 위해 공개된 연구 결과물입니다.
- Open data and models
- Falcon-7/40/180B 모델과 RefinedWeb 데이터셋 중 600B 토큰을 공개했습니다.
4. Experiments and motivations for data, architecture, and hyperparameters
실험의 가장 핵심은 어떤 practice가 유효한 것인지 아닌지 판단하기 위해 1B-3B 파라미터 사이즈의 모델을 사용했다는 것입니다.
또한 어떤 기법들을 적용할지 그렇지 않을지를 결정할 때는 모델의 zero-shot 성능을 기준으로 삼고 있습니다.
4.1. Setup for small-scale experiments
- 1/3B for 30/60B 사이즈 모델. 즉 작은 사이즈의 모델에서 유효했던 학습 방식이 큰 사이즈의 모델에서 역시 유효한 것인지 확인하는 방식
- 물론 큰 모델에서 확인된 emergent ability를 생각해보면, 큰 언어 모델에서 기대하는 패턴을 작은 모델에서 발견하지 못할 수도 있음. 또한 작은 모델에서 나타나는 특징이 반드시 큰 언어 모델에서도 확인될 것이라고 장담하기 어렵다는 것도 전제로 삼고 실험을 진행
4.2. Data: web vs curated, code and multilinguality impact on English performance
- 실험을 통해 'filtered & deduplicated' web data로 학습된 모델의 성능이 curated data에 대해 학습된 모델의 성능과 동등한 수준임을 확인
- filtering과 deduplication 중에서는 특히 후자를 크게 강조하고 있다는 느낌을 받았음. (중복을 피하기 위해 upscaling을 수행하지 않음 등을 보면서 그런 생각이 듦)
- 따라서 Falcon 모델을 학습할 때는 타모델 대비 Web 데이터의 비중이 Curated보다 훨씬 높은 것을 알 수 있음
- 코드와 다른 언어(영어 외) 데이터 구성 비중이 미치는 영향을 확인한 결과입니다.
- 코드 데이터와 타언어 데이터를 조금(5/10%) 사용하더라도 zero-shot performance가 떨어지지 않음을 확인했습니다.
4.3. Architecture and pretraining
- multiquery 대신 multigroup을 사용하여 학습과 추론을 병렬처리함으로써 처리 속도를 향상시켰습니다.
- 이때도 마찬가지로 zero-shot performance의 degradation이 허용 가능한 수준으로 일어납니다.
- Rotary positional embeddings (RoPE)가 ALiBi 대비 조금 더 우수한 성능을 보입니다.
- 활성화 함수로 GLU를 사용하며 메모리를 추가 할당하는 것은 그다지 메리트가 없습니다.
- SwiGLU를 사용하여 실험 진행했습니다.
- parallel layer를 사용하고 bias는 사용하지 않습니다.
4.4. The Microdata curated corpora and conversational masking
- Conversational data
- 궁극적으로 LLM을 'chatty'하게 만들고 싶기 때문에 대화형 데이터가 필요. 따라서 이를 사전학습 데이터에 포함합니다.
- Reddit으로부터 데이터를 수집했습니다.
- Conversation tree and attention masking (Tree-like attention masking)
- Reddit과 같은 플랫폼에서 수집되는 데이터는 하나의 대화에 여러 화자의 발화가 뒤섞여 있는 경우가 많습니다.
- 따라서 관계가 있는 대화를 root와 node로 연결하고 서로에 대해서만 attention 가능하도록 masking합니다.
- 아래 예시에서 'Yes! It's lovely!'는 'Do you like Paris?'와 유일하게 관계를 갖고 있으므로 이것만 attention 대상이며 나머지는 making한 것을 알 수 있습니다.
5. Insights
많은 사람들이 대부분의 LLM은 그냥 데이터빨 아닐까, 데이터에 투자할 돈이 많으니까 고품질 데이터셋을 확보해서 학습을 했겠지, 어차피 자원 빨이다, 라는 이야기를 했습니다.
저는 그런 상황들에 대해서 물론 자세히 밝혀진 바는 없으나 그러한 자원을 활용하는 것도 엄청난 역량을 요하는 것이고, 큰 규모의 자원을 충분히 활용하여 원하는 퍼포먼스를 일궈내는 것 자체가 대단하다고 생각하기 때문에 리스펙해야 한다는 입장이었습니다.
그러나 이 논문을 보고 나서 느낀 것은, "현존하는 LLM들은 인공지능 기술의 집약체"라는 점이었습니다.
다른 논문들에서 접할 수 있던 부분적이고 파편과 같은 개념들이 엄청난 노고와 고도화된 기술을 통해 하나로 합쳐져 있다는 생각을 떨칠 수 없었습니다.
예를 들면 embedding에 대해서 어떤 것을 취할지(RoPE vs. ALiBi), 데이터는 웹의 데이터와 curated 된 것 중 어떤 것을 사용할지 등에 대한 내용들이 너무 방대하고 깊다는 생각이 들었습니다.
가장 인상깊었던 것은 어떤 기술이나 방법론이 유의미한지, 그리고 확장 가능한지 확인할 때 생각보다 작은 사이즈의 모델로 학습을 진행한다는 점이었습니다.
이전에 한정된 자원으로 LLM에 대해 어떻게 학습을 진행하는지에 대해 궁금해서 알아본 적이 있었는데, 사이즈가 수백 billion에 달하는 모델을 학습할 때 저정도의 사이즈가 무슨 의미가 있냐, 라는 생각밖에 들지 않았었습니다.
최근 참여한 세미나에서 이에 대해 반전되는 이야기를 듣고 대체 어떤 방식으로 작은 모델에서 LLM의 능력과 방법론의 타당성을 검증할 수 있을지에 대한 사고 방식을 고쳐먹게 되었는데, 관련된 내용이 강조되어서 굉장히 놀라웠습니다.
개인적으로는 지금까지 내가 알고 있던 LLM은 LLM의 근처에 이르지도 못한 것이구나, 라는 자기 반성도 하게 되었습니다..
출처 : https://arxiv.org/abs/2311.16867
The Falcon Series of Open Language Models
We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--t
arxiv.org