
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[DI Lab, Korea University]
- 사전 학습 동안에 학습 예시들의 난이도를 조절함으롰 dillation의 효율성을 높인 Tutor-KD
- 샘플의 난이도는 teacher model에게는 쉽고 student model에게는 어려운 것으로 조절
- policy gradient method를 활용
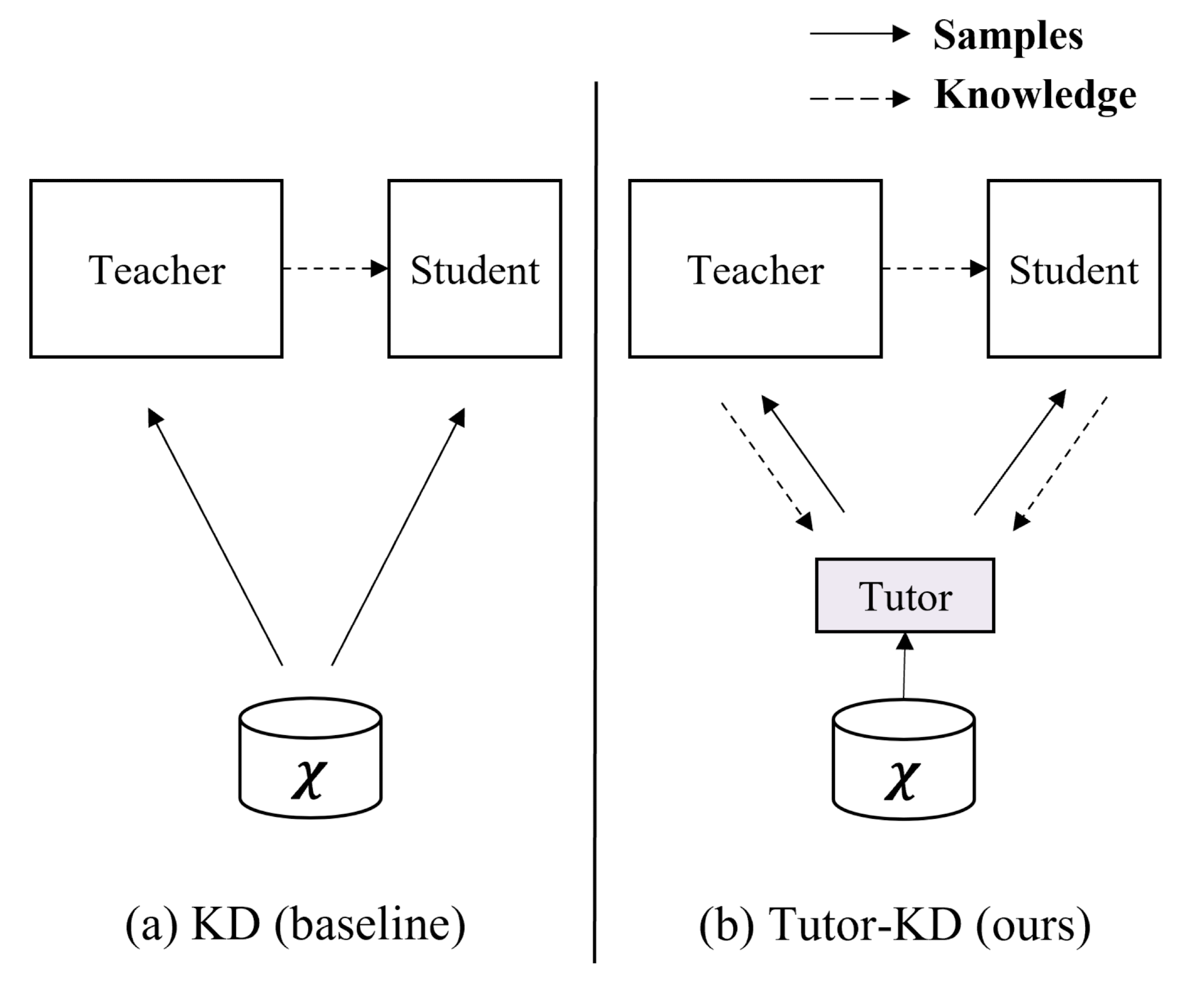
1. Introduction
- Pre-trained Language Models (PLMs)은 뛰어난 성능으로 NLP 분야에서 크게 주목 받았으나 많은 자원을 필요로 한다는 한계를 지님
- 이를 해결하기 위한 방법 중 하나로 Knowledge Distillation (KD)가 제시되었으나 역시 문제점 존재
2. Realted Work
- Pre-trained Language Model (PLM)
- 언어 모델을 unsupervised pre-training 한 것이 다양한 NLP 태스크에서 주목할 만한 성과를 보임
- MLM을 기반으로 하는 BERT, RoBERTa, ELECTRA 등의 모델의 등장
- Knowledge Distillation
- larget teacher model의 지식을 small student model에 transfer하는 방법론
- Data Augmentation for KD
- student model에게 더 어려운 예시를 샘플링하는 것이 모델 성능 향상으로 이어진다고 알려짐
- 그러나 이는 teacher model의 prediction이 옳지 않을 수도 있다는 점을 간과하고 있는 것
3. Contributions
- 학습 샘플의 난이도를 조절함으로써 distillation effectiveness를 향상시킨 PLM을 위한 KD 프레임워크 Tutor-KD를 제안
- policy gradient를 기반으로 teacehr에게는 쉽고 student에게는 어려운 training samples를 생성하는 tutor network를 제시
- 다양한 사이즈의 모델들로 KD의 효율성을 검증하는 실험을 수행
4. Methodology
4.1. Tutor Network
- 학습 안정성을 유지하기 위해 MLM 기반 모델을 generator로 사용
- original sample X를 받아 pseudo training sample X'을 생성하고 이를 teacher's knowledge signal로 전달
- network G는 masked input X^{M}과 pseudo training example X'를 매핑
- X의 토큰 중 k 개의 포지션에 대해 랜덤하게 mask를 씌워 X^{M}을 획득
- 해당 마스크에 대해 모델이 예측한 바로 대체하면 X'가 획득됨
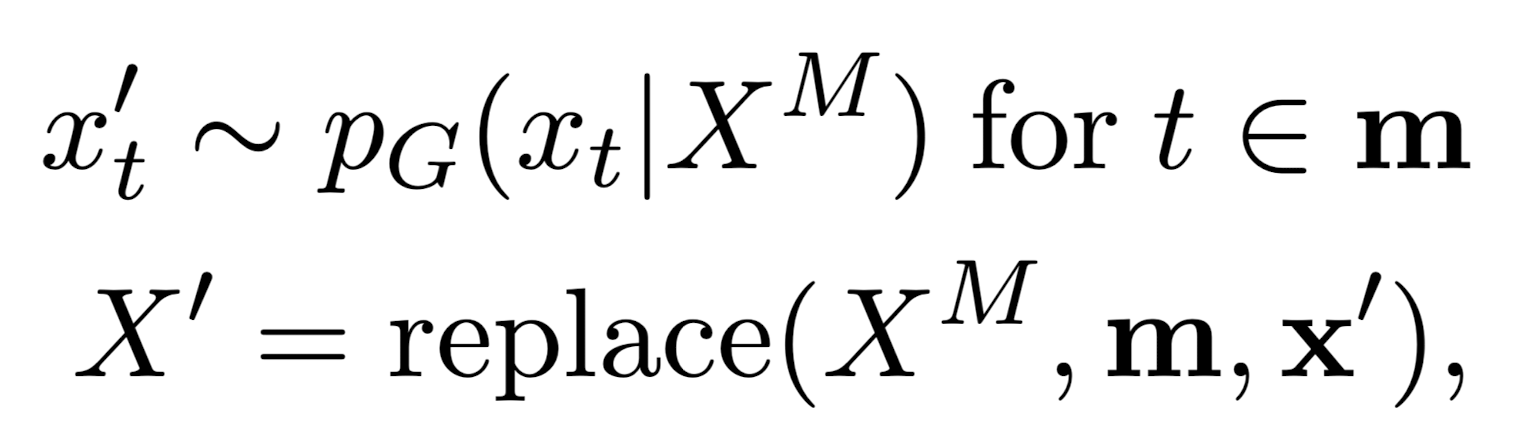
- Tutor는 teacher와 student로부터의 reward인 R_{T}, R_{S}를 최대화하는 방향으로 학습함
- pseudo sample X'을 teacher와 student에게 둘 다 feeding
4.2. Maximization Step
- Teacher's Reward
- teacher의 reward는 original & replaced token의 확률 차로 정의
- teacher 모델이 부정확한 예측을 하는 경우에 대해 negative reward value를 사용
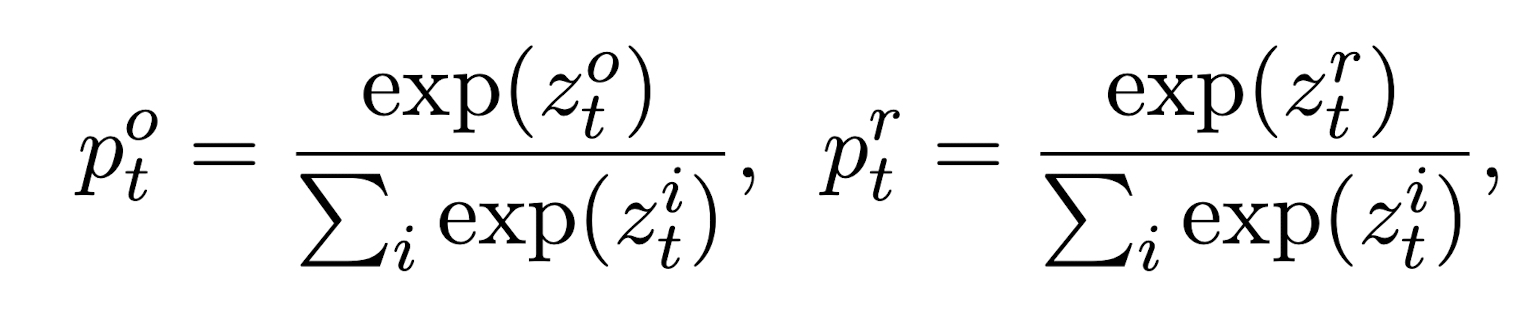
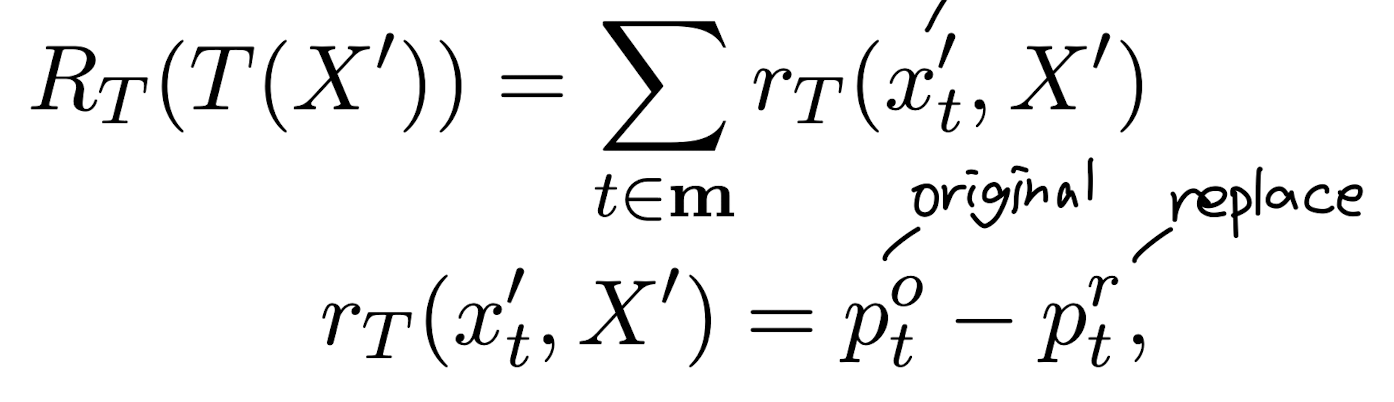
- Student's Reward
- sutdent 모델에게 어렵다는 것을 정의하기 위해, masked token의 position에 대한 teacher & sutdent 모델의 distillation loss를 구함
- 이때 (a_{t})^{T}, (a_{t})^{S} 는 position t에 대한 teacher와 student의 modified logit values를 뜻함 (modified에 대해서는 후술 참고)
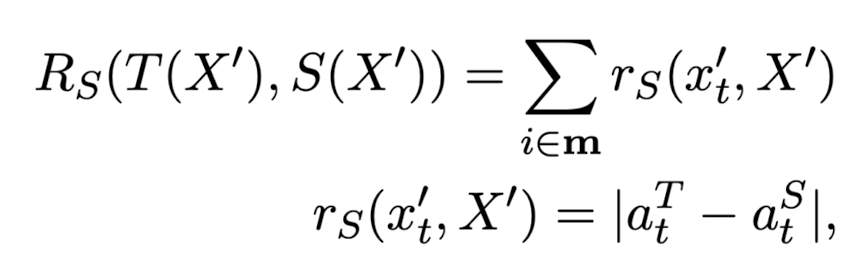
- Training Objective
- policy gradient reinforcement learning을 채택
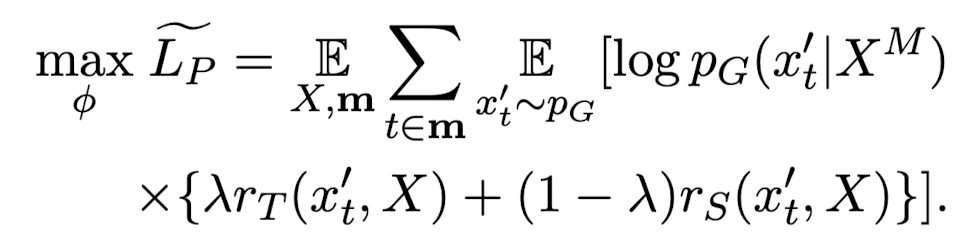
4.3. Minimization step
- teacher와 student의 prediction 차를 최소화하는 방향으로 학습
- tutor가 implausible token을 생성하는 것을 방지하기 위해 teacher의 MLM 지식을 tutor network에 전달
- modified logit loss와 internal representation disillation loss
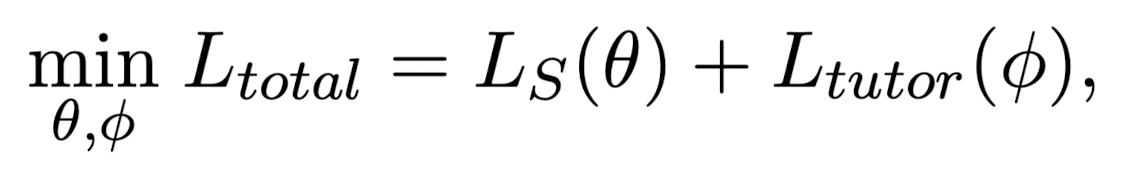
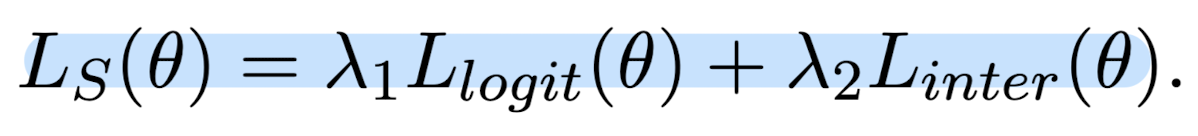
- Logit Modification
- MLM logit distillation이 downstream task에서 좋은 성능을 발휘하지 못한다는 연구 결과가 있었음
- 이를 해결하기 위한 modified logit을 도입
- replaced token's probability를 original token probability에 대한 비율로 대체. 이때 1을 초과하는 비율값이 없도록 식을 조정
- teacher, student의 확률을 아래와 같은 식으로 구한 뒤 final distillation loss를 획득
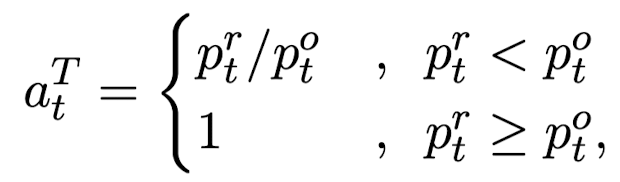
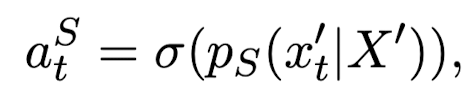
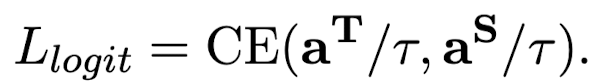
- Internal Representations
- intermediate layer로부터의 knowledge 또한 distill 하도록 함
- intermdeidate hidden representation을 기반으로 하는 L_{hidden}과 attention information을 바탕으로 하는 L_{att}
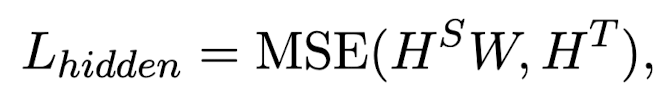
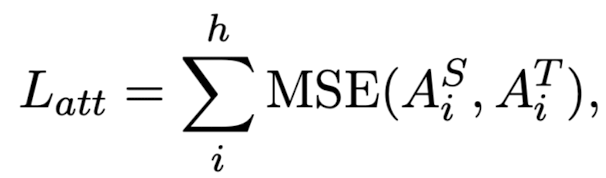
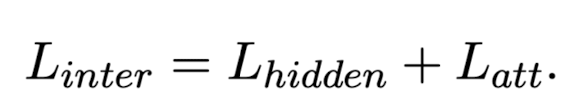
5. Experiments
- Model & Baseline
- BERT-base, WordPiece, Adam, DistilBERT, TinyBERT, MiniLM 등
- Datsets
- English Wikipedia, BookCorpus as KD corpora
- Benchmarks
- GLUE
- Results
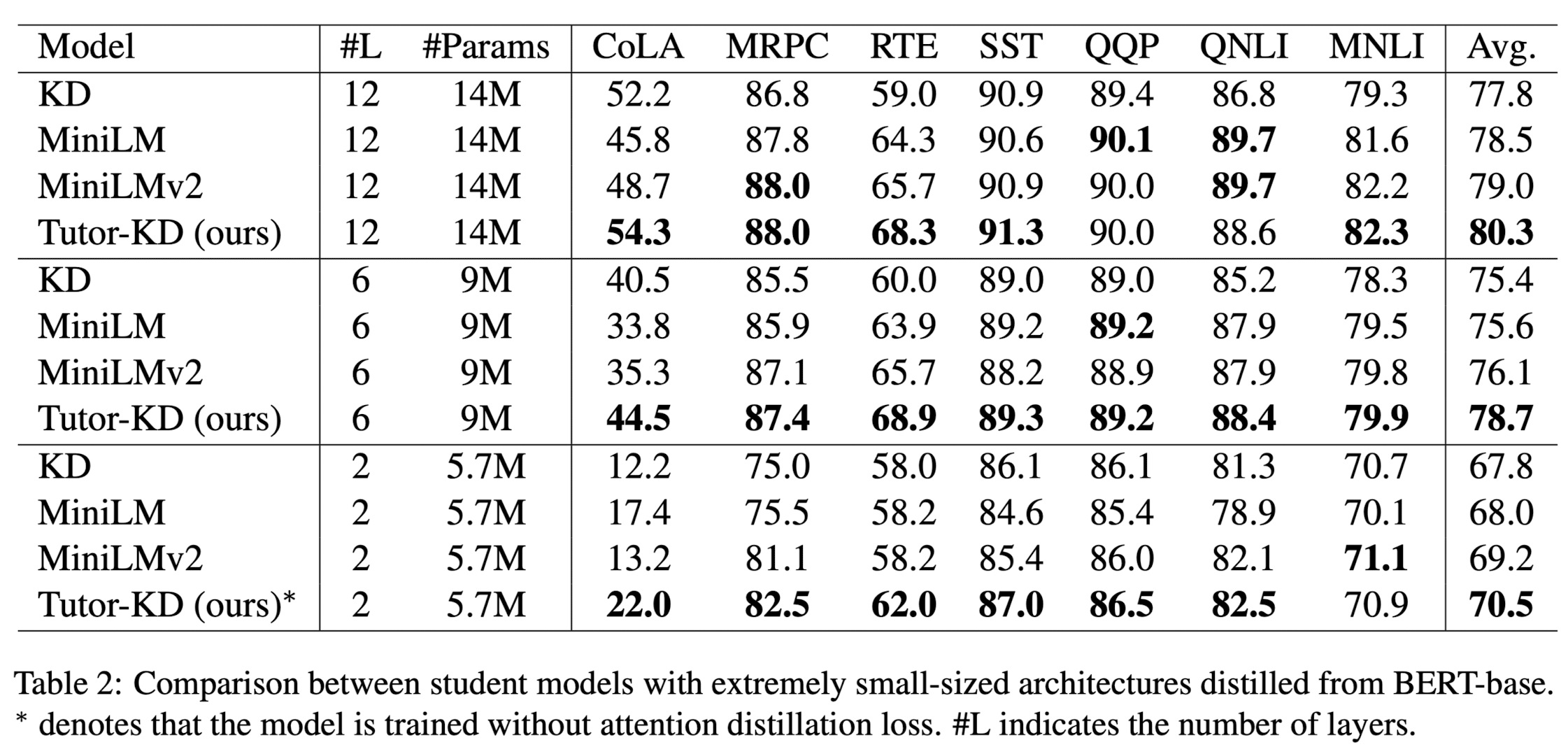
- 여러 실험을 통해 Rewards, Logit Modification, Tutor Network, Sampleing Strategy가 유의미한 영향을 주었음을 확인
- 모델 사이즈가 꽤 작은 편에 속하는 경우에도 유의미한 성능 향상이 있었음을 확인한 것이 중요한 포인트라고 생각함
6. Insights
논문에서도 한계점을 스스로 밝히긴 했으나 실제 더 큰 사이즈의 모델들에 대한 실험 결과도 궁금하기는 하다.
이 논문이 제출된 시점은 1년 전이라서 판도가 완전 다르긴 하지만 지금에 이르러서는 decoder only 모델들에 대한 실험이 주를 이루기 때문이다.
최근에는 기본적으로 사용되는 모델의 사이즈도 굉장히 큰 편이고..
엄청난 novelty가 있는게 아니고서야 BERT 기반의 모델들로 실험을 하거나 사이즈를 확장하지 못한 작은 모델끼리 비교하는 것이 큰 의미를 갖지 못할 수도 있다.
물론 on-device라는 키워드가 함께 주목을 받고 있긴 하니까 그런 점에서는 빛을 발할 수도 있겠다..
출처 : https://aclanthology.org/2022.emnlp-main.498/
Tutoring Helps Students Learn Better: Improving Knowledge Distillation for BERT with Tutor Network
Junho Kim, Jun-Hyung Park, Mingyu Lee, Wing-Lam Mok, Joon-Young Choi, SangKeun Lee. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022.
aclanthology.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[DI Lab, Korea University]
- 사전 학습 동안에 학습 예시들의 난이도를 조절함으롰 dillation의 효율성을 높인 Tutor-KD
- 샘플의 난이도는 teacher model에게는 쉽고 student model에게는 어려운 것으로 조절
- policy gradient method를 활용
1. Introduction
- Pre-trained Language Models (PLMs)은 뛰어난 성능으로 NLP 분야에서 크게 주목 받았으나 많은 자원을 필요로 한다는 한계를 지님
- 이를 해결하기 위한 방법 중 하나로 Knowledge Distillation (KD)가 제시되었으나 역시 문제점 존재
2. Realted Work
- Pre-trained Language Model (PLM)
- 언어 모델을 unsupervised pre-training 한 것이 다양한 NLP 태스크에서 주목할 만한 성과를 보임
- MLM을 기반으로 하는 BERT, RoBERTa, ELECTRA 등의 모델의 등장
- Knowledge Distillation
- larget teacher model의 지식을 small student model에 transfer하는 방법론
- Data Augmentation for KD
- student model에게 더 어려운 예시를 샘플링하는 것이 모델 성능 향상으로 이어진다고 알려짐
- 그러나 이는 teacher model의 prediction이 옳지 않을 수도 있다는 점을 간과하고 있는 것
3. Contributions
- 학습 샘플의 난이도를 조절함으로써 distillation effectiveness를 향상시킨 PLM을 위한 KD 프레임워크 Tutor-KD를 제안
- policy gradient를 기반으로 teacehr에게는 쉽고 student에게는 어려운 training samples를 생성하는 tutor network를 제시
- 다양한 사이즈의 모델들로 KD의 효율성을 검증하는 실험을 수행
4. Methodology
4.1. Tutor Network
- 학습 안정성을 유지하기 위해 MLM 기반 모델을 generator로 사용
- original sample X를 받아 pseudo training sample X'을 생성하고 이를 teacher's knowledge signal로 전달
- network G는 masked input X^{M}과 pseudo training example X'를 매핑
- X의 토큰 중 k 개의 포지션에 대해 랜덤하게 mask를 씌워 X^{M}을 획득
- 해당 마스크에 대해 모델이 예측한 바로 대체하면 X'가 획득됨
- Tutor는 teacher와 student로부터의 reward인 R_{T}, R_{S}를 최대화하는 방향으로 학습함
- pseudo sample X'을 teacher와 student에게 둘 다 feeding
4.2. Maximization Step
- Teacher's Reward
- teacher의 reward는 original & replaced token의 확률 차로 정의
- teacher 모델이 부정확한 예측을 하는 경우에 대해 negative reward value를 사용
- Student's Reward
- sutdent 모델에게 어렵다는 것을 정의하기 위해, masked token의 position에 대한 teacher & sutdent 모델의 distillation loss를 구함
- 이때 (a_{t})^{T}, (a_{t})^{S} 는 position t에 대한 teacher와 student의 modified logit values를 뜻함 (modified에 대해서는 후술 참고)
- Training Objective
- policy gradient reinforcement learning을 채택
4.3. Minimization step
- teacher와 student의 prediction 차를 최소화하는 방향으로 학습
- tutor가 implausible token을 생성하는 것을 방지하기 위해 teacher의 MLM 지식을 tutor network에 전달
- modified logit loss와 internal representation disillation loss
- Logit Modification
- MLM logit distillation이 downstream task에서 좋은 성능을 발휘하지 못한다는 연구 결과가 있었음
- 이를 해결하기 위한 modified logit을 도입
- replaced token's probability를 original token probability에 대한 비율로 대체. 이때 1을 초과하는 비율값이 없도록 식을 조정
- teacher, student의 확률을 아래와 같은 식으로 구한 뒤 final distillation loss를 획득
- Internal Representations
- intermediate layer로부터의 knowledge 또한 distill 하도록 함
- intermdeidate hidden representation을 기반으로 하는 L_{hidden}과 attention information을 바탕으로 하는 L_{att}
5. Experiments
- Model & Baseline
- BERT-base, WordPiece, Adam, DistilBERT, TinyBERT, MiniLM 등
- Datsets
- English Wikipedia, BookCorpus as KD corpora
- Benchmarks
- GLUE
- Results
- 여러 실험을 통해 Rewards, Logit Modification, Tutor Network, Sampleing Strategy가 유의미한 영향을 주었음을 확인
- 모델 사이즈가 꽤 작은 편에 속하는 경우에도 유의미한 성능 향상이 있었음을 확인한 것이 중요한 포인트라고 생각함
6. Insights
논문에서도 한계점을 스스로 밝히긴 했으나 실제 더 큰 사이즈의 모델들에 대한 실험 결과도 궁금하기는 하다.
이 논문이 제출된 시점은 1년 전이라서 판도가 완전 다르긴 하지만 지금에 이르러서는 decoder only 모델들에 대한 실험이 주를 이루기 때문이다.
최근에는 기본적으로 사용되는 모델의 사이즈도 굉장히 큰 편이고..
엄청난 novelty가 있는게 아니고서야 BERT 기반의 모델들로 실험을 하거나 사이즈를 확장하지 못한 작은 모델끼리 비교하는 것이 큰 의미를 갖지 못할 수도 있다.
물론 on-device라는 키워드가 함께 주목을 받고 있긴 하니까 그런 점에서는 빛을 발할 수도 있겠다..
출처 : https://aclanthology.org/2022.emnlp-main.498/
Tutoring Helps Students Learn Better: Improving Knowledge Distillation for BERT with Tutor Network
Junho Kim, Jun-Hyung Park, Mingyu Lee, Wing-Lam Mok, Joon-Young Choi, SangKeun Lee. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022.
aclanthology.org