
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용해 정리했습니다.
(요약을 제외한 모든 내용은 ChatGPT가 요약한 내용입니다 😁)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Carnegie Mellon University, Princeton University]
- selective SSMs을 simplified end-to-end neural network architecture로 통합함
- attention 또는 심지어 MLP block을 포함하지 않음
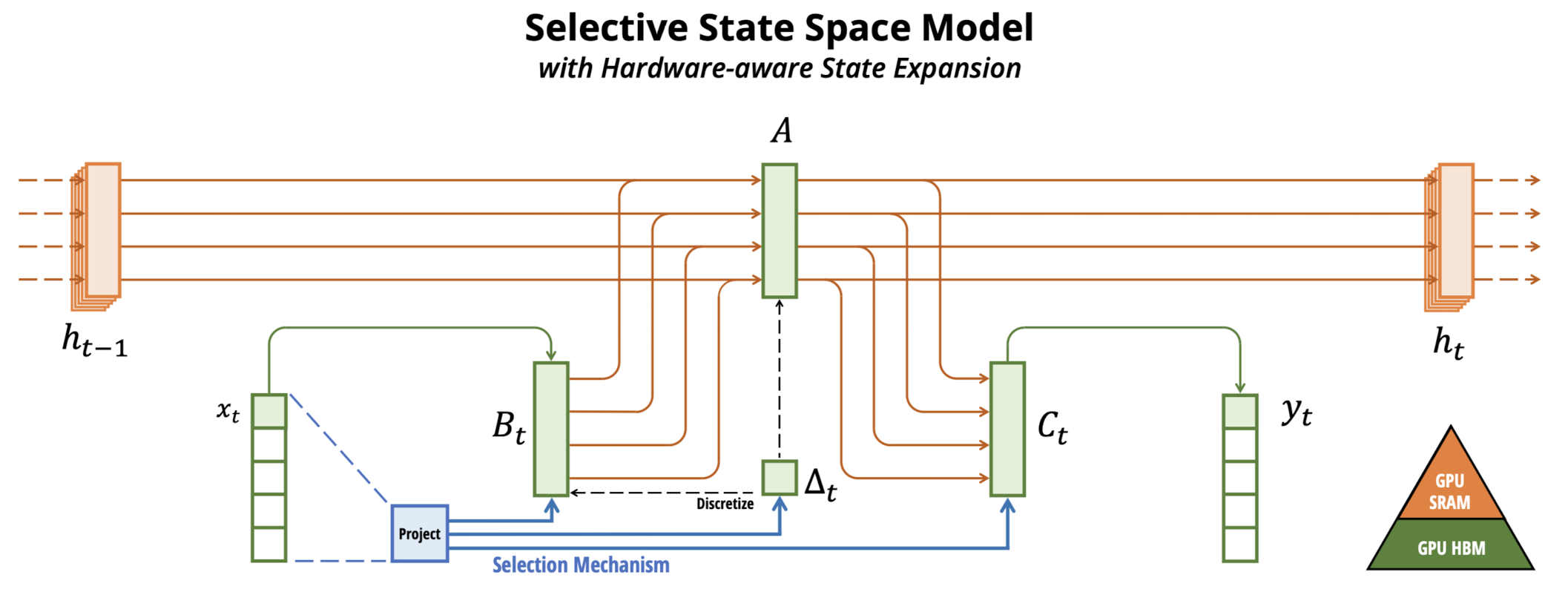
1. Introduction
- 기초 모델(FMs)의 개요
- FMs는 대규모 데이터로 사전 학습된 후 하위 작업에 적용되는 대형 모델로, 현대 머신러닝에서 효과적인 패러다임으로 부상.
- 주로 다양한 도메인(언어, 이미지, 음성, 오디오, 시계열, 유전체학 등)에서 입력의 임의의 시퀀스를 처리하는 순차 모델을 기반으로 함.
- Transformer와 그 한계
- 현대 FMs는 주로 Transformer 아키텍처와 그 핵심인 주의(attention) 레이어에 기반.
- Transformer의 자기주의(self-attention)는 정보를 밀도 있게 라우팅하여 복잡한 데이터 모델링 가능.
- 하지만, 유한한 창(window) 외부의 것을 모델링할 수 없고, 창 길이에 대해 2차원적으로 확장되는 문제 존재.
- 더 효율적인 주의 변형에 대한 연구가 많이 있었으나, Transformer의 핵심적 특성을 손상시키는 경우가 많음.
- 구조화된 상태 공간 순차 모델(SSMs)
- SSMs는 RNNs와 CNNs의 조합으로, 고전 상태 공간 모델에서 영감을 받음.
- 선형 또는 거의 선형 시퀀스 길이로 효율적으로 계산 가능하며, 장기 의존성 모델링에 대한 원칙적인 메커니즘을 가짐.
- 오디오, 비전과 같은 연속 신호 데이터 도메인에서 성공적이었으나, 텍스트와 같은 이산적이고 정보 밀도가 높은 데이터 모델링에서는 덜 효과적임.
- Mamba의 제안
- 새로운 클래스의 선택적 상태 공간 모델을 제안하여, Transformer의 모델링 파워를 달성하면서도 시퀀스 길이에 대해 선형적으로 확장.
- 선택 메커니즘: 입력에 따라 SSM 매개변수를 매개화하여, 불필요한 정보를 필터링하고 관련 정보를 무기한 기억.
- 하드웨어 인식 알고리즘: 모델을 효율적으로 계산하기 위해 컨볼루션 대신 스캔을 사용하여 순환적으로 계산하는 하드웨어 인식 알고리즘 도입.
- 아키텍처: 이전의 깊은 순차 모델 아키텍처를 단순화하여 선택적 상태 공간을 통합한 Mamba 아키텍처 개발.
- Mamba의 실증적 검증
- 합성, 오디오, 유전체학, 언어 모델링 등 다양한 모달리티와 설정에서 Mamba의 일반 순차 FM 백본으로서의 잠재력을 실증적으로 검증.
- Mamba는 Transformer의 품질을 달성하면서도 선형 시간에 가까운 시퀀스 모델링을 실현함으로써, 동일 크기의 Transformer보다 5배 높은 처리량을 달성하고, 그 크기의 두 배에 해당하는 Transformer의 성능과 일치함.
2. Realted Work
- SSM 변형 및 파생 모델
- S4 및 S5 모델: S4는 첫 번째 구조화된 SSM을 도입. S5는 대각 SSM 근사를 독립적으로 발견하고 병렬 스캔을 사용하여 순환적으로 계산함.
- DSS 및 S4D: DSS는 대각 구조화된 SSM의 실제 효과를 발견. S4D는 이를 이론적으로 확장함.
- Mega 및 Liquid S4: Mega는 S4를 실수 값으로 단순화하여 EMA로 해석. Liquid S4는 입력 의존적 상태 전환으로 S4를 증강함.
- 다양한 합성 모델: SGConv, Hyena, LongConv 등은 S4의 컨볼루셔널 표현에 집중하며 글로벌 또는 장기 컨볼루션 커널을 다양하게 매개화함.
- SSM 아키텍처
- GSS 및 H3 모델: GSS는 첫 번째 게이트 뉴럴 네트워크 아키텍처로 SSM을 통합함. H3는 S4와 선형 주의의 결합을 목표로 함.
- RetNet 및 RWKV: RetNet은 Linear Attention에 기반하며, RWKV는 AFT에 기반한 새로운 RNN 디자인.
- RNN과의 관계
- 고전적인 RNN과 SSM은 잠재 상태에 대한 반복 개념에서 연관성이 있음.
- 구조화된 SSM과는 다르게, 일부 RNN은 선택적 SSM의 형태로 간주될 수 있으나, 상태 확장이나 선택적 B, C 매개변수를 사용하지 않음.
- 선형 주의
- 선형 주의(LA)는 커널 주의를 대중화하고 순환 자기회귀 모델과의 관계를 보여줌.
- 다양한 커널과 수정사항이 제안된 많은 LA 변형이 있음.
- 장기 컨텍스트 모델
- 장기 컨텍스트는 인기 있는 주제가 되었으며, 여러 모델이 더 긴 시퀀스로 확장될 수 있음을 주장함.
- 이러한 모델들은 계산적 관점에서 주장되었으나, 실제 작업에서의 유효성은 광범위하게 검증되지 않음.
3. Method
3.1 선택 메커니즘의 동기: 압축 수단으로서의 선택
- 문제 정의: 시퀀스 모델링의 핵심 문제는 맥락을 더 작은 상태로 압축하는 것임.
- 효율성 vs. 효과성: 효율적인 모델은 작은 상태를 가지며, 효과적인 모델은 맥락에서 필요한 모든 정보를 포함한 상태를 가짐.
- 선택 메커니즘의 제안: 시퀀스 상태로의 입력 집중 또는 필터링을 가능하게 하는 맥락 인식 능력을 강조.
3.2 선택을 통한 SSM 개선
- 선택 메커니즘의 구현: 시퀀스 내 상호작용을 조절하는 매개변수(예: RNN의 재발 동력학 또는 CNN의 컨볼루션 커널)를 입력 의존적으로 설정.
- 기술적 도전: 시간 변화하는 SSM은 컨볼루션을 사용할 수 없으므로, 이를 효율적으로 계산하는 방법이 필요.
3.3 선택적 SSM의 효율적 구현
- 하드웨어 인식 알고리즘: 현대 하드웨어(GPU)의 메모리 계층을 활용하는 하드웨어 친화적 알고리즘 도입.
- 계산 문제 해결: 커널 융합, 병렬 스캔, 재계산을 통해 시간적인 자연스러움과 대규모 메모리 사용 문제 해결.
3.4 간소화된 SSM 아키텍처
- 아키텍처 설계: 선형 주의와 MLP 블록을 하나의 블록으로 결합하여 반복적으로 구성.
- 모델 차원 확장: 모델 차원을 제어 가능한 확장 인자로 확장하여 더 많은 매개변수를 포함.
3.5 선택 메커니즘의 특성
- 게이팅 메커니즘과의 연결: 전통적인 RNN의 게이팅 메커니즘은 SSM의 선택 메커니즘의 한 예시임.
- 변수 간격 및 맥락 필터링: 불필요한 정보를 걸러내어 시퀀스 모델의 맥락을 효과적으로 압축.
- 경계 재설정: 독립적인 시퀀스 간 정보의 유출을 방지하고 맥락을 초기화할 수 있는 능력.
3.6 추가 모델 세부사항
- 실수 대 복소수: 대부분의 SSM은 복소수를 사용하지만, 일부 작업에서는 실수 값 SSM이 더 효과적일 수 있음.
- 초기화 및 매개변수화: 특정 초기화 방법과 선택적 조정을 위한 매개변수화 방법 제시.
4. Experiments
4.1 합성 작업
- 선택적 복사: 선택 메커니즘을 사용하여 기존 S4 모델을 S6 모델로 개선, 이를 통해 선택적 복사 작업을 쉽게 해결함.
- 유도 헤드: Mamba는 유도 헤드 작업에서 완벽한 해결능력을 보여주며, 특히 훈련 중 보지 못한 백만 길이의 시퀀스에서도 완벽한 일반화를 보임.
4.2 언어 모델링
- 모델 규모: Mamba는 기존의 Transformer 아키텍처와 비교하여 크기 및 성능 면에서 우수함을 보임.
- 하류 평가: 다양한 하류 작업에서 Mamba는 동급 또는 더 큰 크기의 모델들과 비교하여 우수한 성능을 보임.
4.3 DNA 모델링
- 스케일링: 모델 크기와 시퀀스 길이 측면에서 Mamba는 기존 모델들보다 더 나은 성능을 보임.
- 합성 종 분류: Mamba는 DNA 시퀀스를 사용한 종 분류 작업에서 높은 성능을 보임.
4.4 오디오 모델링 및 생성
- 자기회귀 사전훈련: Mamba는 기존의 SaShiMi 모델보다 더 긴 시퀀스에 대해 더 나은 성능을 보임.
- 자기회귀 음성 생성: Mamba는 SC09 벤치마크에서 다양한 기준으로 기존 모델들을 능가함.
4.5 속도 및 메모리 벤치마크
- 효율성: Mamba는 유사한 크기의 Transformer 모델보다 4-5배 더 높은 추론 처리량을 달성함.
- 메모리 소비: Mamba는 효율적인 메모리 사용을 보임.
4.6 모델 세부 사항 분석
- 아키텍처: Mamba는 H3 아키텍처와 유사한 성능을 보이면서 더 단순함.
- 선택적 SSM: 선택적 SSM 요소가 성능 향상에 중요한 역할을 함.
- 초기화 및 매개변수화: 단순한 실수 값 초기화와 선택적 매개변수화가 언어 모델링에서 효과적임.
5. Conclusion & Limit
5.1 관련 연구
- 선택 메커니즘: 부록 A에서는 선택 메커니즘과 유사한 개념과의 관계를 논의함.
- SSM 관련 연구: 부록 B에서는 SSM 및 기타 관련 모델에 대한 확장된 연구를 제공함.
5.2 무료 점심 없음: 연속-이산 스펙트럼
- SSM의 이산화: SSM은 원래 연속 시스템의 이산화로 정의되어 주로 연속 시간 데이터 모달리티(오디오, 비디오 등)에 강한 편향을 가짐.
- 선택 메커니즘의 장점과 단점: 텍스트와 DNA와 같은 이산 모달리티에서 선택 메커니즘은 SSM의 약점을 극복하나, LTI SSM이 우수한 데이터에서는 성능을 저해할 수 있음.
5.3 하류 작업의 기회
- Transformer 기반 모델의 생태계: Transformer 모델은 미세 조정, 적응, 프롬프팅, 인컨텍스트 학습, 명령어 튜닝 등과 같은 다양한 상호 작용 모드를 가짐.
- SSM의 속성 및 기능: SSM이 Transformer 대안으로서 유사한 속성과 기능을 가질 수 있는지에 대한 관심이 있음.
5.4 스케일링
- 모델 크기의 제한: Mamba의 평가는 대부분의 강력한 오픈 소스 LLM보다 작은 모델 크기에 국한됨.
- 더 큰 규모의 평가 필요: Mamba가 더 큰 규모(예: 7B 매개변수 이상)에서 여전히 유리한지 평가할 필요가 있음.
- SSM 확장의 도전: SSM을 확장하는 데는 추가적인 공학적 도전과 모델 조정이 필요할 수 있음.
5.5 결론
- 선택 메커니즘의 도입: 구조화된 상태 공간 모델에 선택 메커니즘을 도입하여 시퀀스 길이에 선형적으로 확장되는 맥락 의존적 추론 수행 가능.
- Mamba의 성과: 간단한 주의(attention)-없는 아키텍처인 Mamba는 다양한 도메인에서 최첨단 성능을 달성함.
- Mamba의 일반 시퀀스 모델 백본 후보로서의 가능성: Mamba는 유전체학, 오디오, 비디오와 같이 긴 맥락이 필요한 새로운 모달리티에 대한 기초 모델을 구축하는데 강력한 후보임.
출처 : https://arxiv.org/abs/2312.00752v1
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용해 정리했습니다.
(요약을 제외한 모든 내용은 ChatGPT가 요약한 내용입니다 😁)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Carnegie Mellon University, Princeton University]
- selective SSMs을 simplified end-to-end neural network architecture로 통합함
- attention 또는 심지어 MLP block을 포함하지 않음
1. Introduction
- 기초 모델(FMs)의 개요
- FMs는 대규모 데이터로 사전 학습된 후 하위 작업에 적용되는 대형 모델로, 현대 머신러닝에서 효과적인 패러다임으로 부상.
- 주로 다양한 도메인(언어, 이미지, 음성, 오디오, 시계열, 유전체학 등)에서 입력의 임의의 시퀀스를 처리하는 순차 모델을 기반으로 함.
- Transformer와 그 한계
- 현대 FMs는 주로 Transformer 아키텍처와 그 핵심인 주의(attention) 레이어에 기반.
- Transformer의 자기주의(self-attention)는 정보를 밀도 있게 라우팅하여 복잡한 데이터 모델링 가능.
- 하지만, 유한한 창(window) 외부의 것을 모델링할 수 없고, 창 길이에 대해 2차원적으로 확장되는 문제 존재.
- 더 효율적인 주의 변형에 대한 연구가 많이 있었으나, Transformer의 핵심적 특성을 손상시키는 경우가 많음.
- 구조화된 상태 공간 순차 모델(SSMs)
- SSMs는 RNNs와 CNNs의 조합으로, 고전 상태 공간 모델에서 영감을 받음.
- 선형 또는 거의 선형 시퀀스 길이로 효율적으로 계산 가능하며, 장기 의존성 모델링에 대한 원칙적인 메커니즘을 가짐.
- 오디오, 비전과 같은 연속 신호 데이터 도메인에서 성공적이었으나, 텍스트와 같은 이산적이고 정보 밀도가 높은 데이터 모델링에서는 덜 효과적임.
- Mamba의 제안
- 새로운 클래스의 선택적 상태 공간 모델을 제안하여, Transformer의 모델링 파워를 달성하면서도 시퀀스 길이에 대해 선형적으로 확장.
- 선택 메커니즘: 입력에 따라 SSM 매개변수를 매개화하여, 불필요한 정보를 필터링하고 관련 정보를 무기한 기억.
- 하드웨어 인식 알고리즘: 모델을 효율적으로 계산하기 위해 컨볼루션 대신 스캔을 사용하여 순환적으로 계산하는 하드웨어 인식 알고리즘 도입.
- 아키텍처: 이전의 깊은 순차 모델 아키텍처를 단순화하여 선택적 상태 공간을 통합한 Mamba 아키텍처 개발.
- Mamba의 실증적 검증
- 합성, 오디오, 유전체학, 언어 모델링 등 다양한 모달리티와 설정에서 Mamba의 일반 순차 FM 백본으로서의 잠재력을 실증적으로 검증.
- Mamba는 Transformer의 품질을 달성하면서도 선형 시간에 가까운 시퀀스 모델링을 실현함으로써, 동일 크기의 Transformer보다 5배 높은 처리량을 달성하고, 그 크기의 두 배에 해당하는 Transformer의 성능과 일치함.
2. Realted Work
- SSM 변형 및 파생 모델
- S4 및 S5 모델: S4는 첫 번째 구조화된 SSM을 도입. S5는 대각 SSM 근사를 독립적으로 발견하고 병렬 스캔을 사용하여 순환적으로 계산함.
- DSS 및 S4D: DSS는 대각 구조화된 SSM의 실제 효과를 발견. S4D는 이를 이론적으로 확장함.
- Mega 및 Liquid S4: Mega는 S4를 실수 값으로 단순화하여 EMA로 해석. Liquid S4는 입력 의존적 상태 전환으로 S4를 증강함.
- 다양한 합성 모델: SGConv, Hyena, LongConv 등은 S4의 컨볼루셔널 표현에 집중하며 글로벌 또는 장기 컨볼루션 커널을 다양하게 매개화함.
- SSM 아키텍처
- GSS 및 H3 모델: GSS는 첫 번째 게이트 뉴럴 네트워크 아키텍처로 SSM을 통합함. H3는 S4와 선형 주의의 결합을 목표로 함.
- RetNet 및 RWKV: RetNet은 Linear Attention에 기반하며, RWKV는 AFT에 기반한 새로운 RNN 디자인.
- RNN과의 관계
- 고전적인 RNN과 SSM은 잠재 상태에 대한 반복 개념에서 연관성이 있음.
- 구조화된 SSM과는 다르게, 일부 RNN은 선택적 SSM의 형태로 간주될 수 있으나, 상태 확장이나 선택적 B, C 매개변수를 사용하지 않음.
- 선형 주의
- 선형 주의(LA)는 커널 주의를 대중화하고 순환 자기회귀 모델과의 관계를 보여줌.
- 다양한 커널과 수정사항이 제안된 많은 LA 변형이 있음.
- 장기 컨텍스트 모델
- 장기 컨텍스트는 인기 있는 주제가 되었으며, 여러 모델이 더 긴 시퀀스로 확장될 수 있음을 주장함.
- 이러한 모델들은 계산적 관점에서 주장되었으나, 실제 작업에서의 유효성은 광범위하게 검증되지 않음.
3. Method
3.1 선택 메커니즘의 동기: 압축 수단으로서의 선택
- 문제 정의: 시퀀스 모델링의 핵심 문제는 맥락을 더 작은 상태로 압축하는 것임.
- 효율성 vs. 효과성: 효율적인 모델은 작은 상태를 가지며, 효과적인 모델은 맥락에서 필요한 모든 정보를 포함한 상태를 가짐.
- 선택 메커니즘의 제안: 시퀀스 상태로의 입력 집중 또는 필터링을 가능하게 하는 맥락 인식 능력을 강조.
3.2 선택을 통한 SSM 개선
- 선택 메커니즘의 구현: 시퀀스 내 상호작용을 조절하는 매개변수(예: RNN의 재발 동력학 또는 CNN의 컨볼루션 커널)를 입력 의존적으로 설정.
- 기술적 도전: 시간 변화하는 SSM은 컨볼루션을 사용할 수 없으므로, 이를 효율적으로 계산하는 방법이 필요.
3.3 선택적 SSM의 효율적 구현
- 하드웨어 인식 알고리즘: 현대 하드웨어(GPU)의 메모리 계층을 활용하는 하드웨어 친화적 알고리즘 도입.
- 계산 문제 해결: 커널 융합, 병렬 스캔, 재계산을 통해 시간적인 자연스러움과 대규모 메모리 사용 문제 해결.
3.4 간소화된 SSM 아키텍처
- 아키텍처 설계: 선형 주의와 MLP 블록을 하나의 블록으로 결합하여 반복적으로 구성.
- 모델 차원 확장: 모델 차원을 제어 가능한 확장 인자로 확장하여 더 많은 매개변수를 포함.
3.5 선택 메커니즘의 특성
- 게이팅 메커니즘과의 연결: 전통적인 RNN의 게이팅 메커니즘은 SSM의 선택 메커니즘의 한 예시임.
- 변수 간격 및 맥락 필터링: 불필요한 정보를 걸러내어 시퀀스 모델의 맥락을 효과적으로 압축.
- 경계 재설정: 독립적인 시퀀스 간 정보의 유출을 방지하고 맥락을 초기화할 수 있는 능력.
3.6 추가 모델 세부사항
- 실수 대 복소수: 대부분의 SSM은 복소수를 사용하지만, 일부 작업에서는 실수 값 SSM이 더 효과적일 수 있음.
- 초기화 및 매개변수화: 특정 초기화 방법과 선택적 조정을 위한 매개변수화 방법 제시.
4. Experiments
4.1 합성 작업
- 선택적 복사: 선택 메커니즘을 사용하여 기존 S4 모델을 S6 모델로 개선, 이를 통해 선택적 복사 작업을 쉽게 해결함.
- 유도 헤드: Mamba는 유도 헤드 작업에서 완벽한 해결능력을 보여주며, 특히 훈련 중 보지 못한 백만 길이의 시퀀스에서도 완벽한 일반화를 보임.
4.2 언어 모델링
- 모델 규모: Mamba는 기존의 Transformer 아키텍처와 비교하여 크기 및 성능 면에서 우수함을 보임.
- 하류 평가: 다양한 하류 작업에서 Mamba는 동급 또는 더 큰 크기의 모델들과 비교하여 우수한 성능을 보임.
4.3 DNA 모델링
- 스케일링: 모델 크기와 시퀀스 길이 측면에서 Mamba는 기존 모델들보다 더 나은 성능을 보임.
- 합성 종 분류: Mamba는 DNA 시퀀스를 사용한 종 분류 작업에서 높은 성능을 보임.
4.4 오디오 모델링 및 생성
- 자기회귀 사전훈련: Mamba는 기존의 SaShiMi 모델보다 더 긴 시퀀스에 대해 더 나은 성능을 보임.
- 자기회귀 음성 생성: Mamba는 SC09 벤치마크에서 다양한 기준으로 기존 모델들을 능가함.
4.5 속도 및 메모리 벤치마크
- 효율성: Mamba는 유사한 크기의 Transformer 모델보다 4-5배 더 높은 추론 처리량을 달성함.
- 메모리 소비: Mamba는 효율적인 메모리 사용을 보임.
4.6 모델 세부 사항 분석
- 아키텍처: Mamba는 H3 아키텍처와 유사한 성능을 보이면서 더 단순함.
- 선택적 SSM: 선택적 SSM 요소가 성능 향상에 중요한 역할을 함.
- 초기화 및 매개변수화: 단순한 실수 값 초기화와 선택적 매개변수화가 언어 모델링에서 효과적임.
5. Conclusion & Limit
5.1 관련 연구
- 선택 메커니즘: 부록 A에서는 선택 메커니즘과 유사한 개념과의 관계를 논의함.
- SSM 관련 연구: 부록 B에서는 SSM 및 기타 관련 모델에 대한 확장된 연구를 제공함.
5.2 무료 점심 없음: 연속-이산 스펙트럼
- SSM의 이산화: SSM은 원래 연속 시스템의 이산화로 정의되어 주로 연속 시간 데이터 모달리티(오디오, 비디오 등)에 강한 편향을 가짐.
- 선택 메커니즘의 장점과 단점: 텍스트와 DNA와 같은 이산 모달리티에서 선택 메커니즘은 SSM의 약점을 극복하나, LTI SSM이 우수한 데이터에서는 성능을 저해할 수 있음.
5.3 하류 작업의 기회
- Transformer 기반 모델의 생태계: Transformer 모델은 미세 조정, 적응, 프롬프팅, 인컨텍스트 학습, 명령어 튜닝 등과 같은 다양한 상호 작용 모드를 가짐.
- SSM의 속성 및 기능: SSM이 Transformer 대안으로서 유사한 속성과 기능을 가질 수 있는지에 대한 관심이 있음.
5.4 스케일링
- 모델 크기의 제한: Mamba의 평가는 대부분의 강력한 오픈 소스 LLM보다 작은 모델 크기에 국한됨.
- 더 큰 규모의 평가 필요: Mamba가 더 큰 규모(예: 7B 매개변수 이상)에서 여전히 유리한지 평가할 필요가 있음.
- SSM 확장의 도전: SSM을 확장하는 데는 추가적인 공학적 도전과 모델 조정이 필요할 수 있음.
5.5 결론
- 선택 메커니즘의 도입: 구조화된 상태 공간 모델에 선택 메커니즘을 도입하여 시퀀스 길이에 선형적으로 확장되는 맥락 의존적 추론 수행 가능.
- Mamba의 성과: 간단한 주의(attention)-없는 아키텍처인 Mamba는 다양한 도메인에서 최첨단 성능을 달성함.
- Mamba의 일반 시퀀스 모델 백본 후보로서의 가능성: Mamba는 유전체학, 오디오, 비디오와 같이 긴 맥락이 필요한 새로운 모달리티에 대한 기초 모델을 구축하는데 강력한 후보임.
출처 : https://arxiv.org/abs/2312.00752v1
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution
arxiv.org