
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Apple]
- query에 explicit information이 부족한 경우 retrieval 성능 향상에 도움이 되는 Context Tuning for RAG를 제안
- LambdaMART에 Reciprocal Rank Fusion (RRF)를 적용한 lightweight 모델이 GPT-4 기반 retireval보다 뛰어남

1. Introduction
- 다양한 태스크를 두루 잘 처리할 수 있는 LLM의 능력 덕분에, LLM을 planning agent로 활용하고자 하는 연구가 활발히 이뤄짐
- 최신 정보가 반영되지 않는 등의 inherent limitation은 hallucination 문제로 이어짐
- 이와 같은 문제를 해결하기 위해 information으로 input을 augment하는 RAG (Retrieval Augmented Generation) 방식이 제안됨
- specificity 또는 context가 부족한 query에 대한 근본적인 한계가 존재
- Tool Retrieval, Plan Generation, Execution 세 가지 요소로 구성되나, 본 논문에서는 Tool Retrieval을 개선하는 것에 집중
2. Realted Work
- Retrieval
- text-based retriever은 모호한 query를 처리하기에 부적절 -> semantic search의 필요성
- CoT augmentation
- vanilla semantic search와 같은 baseline method의 성능 향상에 도움이 됨
- 그러나 LLM의 input length 제한을 고려하면 아쉬운 방법
- Distillation-based query augmentation approache도 제안됨
- LLM을 zero-shot ranker로 사용하고자 하는 연구도 존재
3. Contributions
- Traditional RAG가 implicit/context-seeking query에 부적합함과 동시에 context tuning이 대안이 될 수 있음을 입증
- lightweight 모델과 LLM 둘 다에 context retrieval method를 적용하여 systematic comprasion을 수행
- Chain of Thought (CoT) augmentation이 context retrieval 성능을 향상시키는 데 도움을 줌. 반면에 fine-tuning은 CoT augmentation의 필요성을 삭제해줌
- 경량화된 모델, Reciprocal Rank Fusion (RRF) with LambdaMART를 제안
- plan 단계에서 context augmentation을 수행하는 것이 hallucination을 줄이는 데 도움을 줌
4. Methodology
4.1. Data Generation
- GPT-4를 이용하여 현실 시나리오를 반영할 수 있는 synthetic application data를 생성
- 총 791개의 distinct persona
- 4,338개의 implicit queries for training / 936개의 implicit queries for evaluation
- 59개의 API를 포함하는 toolbox 또한 GPT-4를 이용하여 생성
- 가상의 assistant와 user interaction을 생성하기 위해 다시 한 번 GPT-4를 사용
- application data를 바탕으로 realistic queries를 생성
- query에 대해 toolbox를 바탕으로 적절한 tool를 retrieve
- 마지막으로 정확한 parameter를 바탕으로 tool's API를 사용
4.2. Context Tuning
text-based & vector-based retrieval을 비교
- BM25
- text-based search
- 여기서는 BM25T를 사용
- Semantic Search
- vector-based search
- GTR-T5-XL을 사용
- CoT를 이용하여 pre-traind & fine-tuned semantic search를 둘 다 평가
- LambdaMART with RRF
4.3. Tool Retrieval
- 사전 학습된 GTR-T5-XL 모델을 semantic search에 활용하여 top-K tools를 retrieve
- tool retrieval performance를 with/without context retrieval 상황으로 평가. 이때 Recall@K를 지표로 사용
4.4. Planner
- tool list로부터 가장 적절한 tool을 고르고 well-formed plan을 생성하는 것이 planner의 목표
- OpenLLaMA-v2-7B를 fine-tune
- Abstract Syntax Tree (AST)를 사용하여 planner의 성능을 평가
5. Results
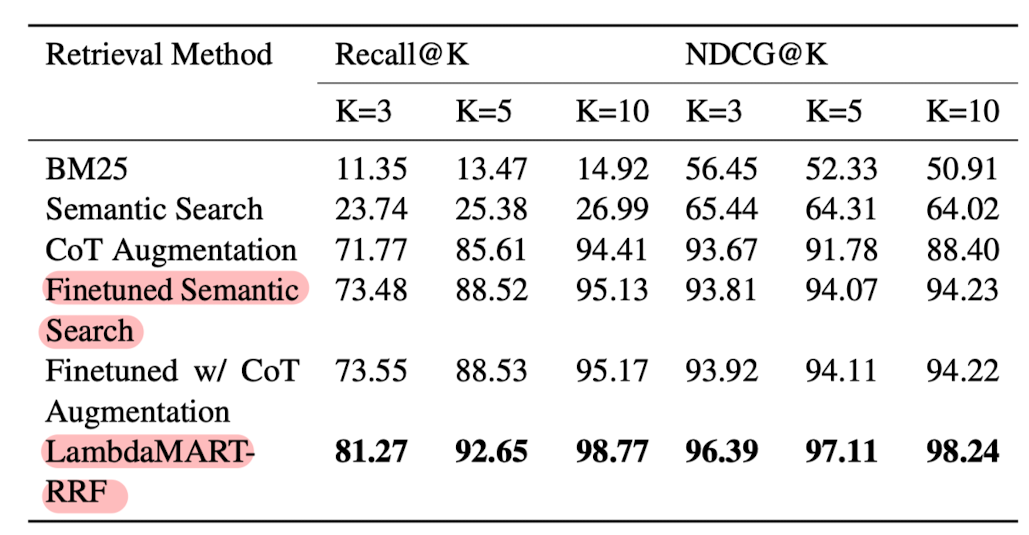
- Context Retrieval
- vector-based search가 text-based search보다 뛰어난 결과
- 물론 둘 다 under-specified queries에 대해서는 retrieve 성능이 낮음
- Fine-tuend semantic search와 CoT augmentation with pre-trained semantic search 둘 다 retrieval 성능을 크게 향상시킴
- LlambdaMART with RRF는 fine-tuned sematic search and CoT augmentation보다 뛰어난 것을 확인
- vector-based search가 text-based search보다 뛰어난 결과
- Tool Retrieval
- relevant context를 tool retrieval에 통합시키는 것이 여러 K-values를 향상시키는 데 도움을 줌
- Planner
- 상한선과 하한선을 설정
- context-tuned planner가 기존의 semantic search를 사용하는 RAG 대비 뛰어난 것을 확인


6. Insights
단순 technical report 수준의 글이었다..
Apple이 RAG를 다루는게 신기해서 봤는데 뭔가를 얻어갈 것이 없는 논문이었던 것 같다.
새로운 아이디어보다는 RRF (Reciprocal Rank Fusion)과 LambdaMART가 무엇인지에 대한 궁금증만 남은 것 같다.
최근 prompt에 대한 중요성이 대두됨에 따라 인공지능 모델이 필요로 하는 양식에 맞추어 입력을 제공하는 것이 더욱 더 중요하다고 생각했는데, 실제 사용자들은 그렇게 맞출 수 없다는 것을 바탕으로 제시된 방법론이 아닌가 싶은 생각도 들었다.
Apple은 결국 자사 제품에 탑재할 수 있는 인공지능 기술을 만들어내는 데 관심이 있기 때문에..
인공지능에 큰 관심이 없는 사람들은 자신들이 편한대로 모델에게 입력을 제공할 것이므로 애매하고 implicit한 query를 어떻게 처리할 것인지에 대한 연구가 더욱 필요하다는 입장에는 공감할 수 있었다.
다만 저자들이 말하는 context-seeking query가 어떤 것인지 나와 있는 것은 아니라서 많이 아쉽게 느껴졌다.
출처 : https://arxiv.org/abs/2312.05708
Context Tuning for Retrieval Augmented Generation
Large language models (LLMs) have the remarkable ability to solve new tasks with just a few examples, but they need access to the right tools. Retrieval Augmented Generation (RAG) addresses this problem by retrieving a list of relevant tools for a given ta
arxiv.org