
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[University of Illinois at Urbana-Champaign, Tsinghua University]
- 7B 사이즈를 넘지 않으면서도 top code 모델들과의 gap을 크게 줄인 fully open-source LLMs, Magicoder
- OSS-Instruct & Evol-Instruct 둘을 활용하여 구축한 MagicoderS가 뛰어난 성능을 보임
1. Introduction
- program synthesis로도 잘 알려진 code generation은 오랜 시간에 걸쳐 지속적으로 연구되어 온 분야임
- LLM의 발전에 힘입어 코드 생성 분야도 눈에 띄는 속도로 발전하기 시작함
- GPT-3.5 Turbo, GPT-4와 같은 closed-source 모델들이 code generation benchmark와 leaderboard를 차지
- 현존하는 LLM의 instruction following 능력은 predefined task의 범위에 한정된다는 문제점이 존재함
2. Realted Work
- Foundation models for code
- 수십억 줄의 코드를 학습한 LLM은 code generation, program repair, fuzzing과 같은 여러 태스크에 대해 우수한 성능을 입증함
- CopdeGen, CodeT5, StarCoder, CodeLlama와 같은 사전학습 모델들이 존재
- Instruction tuning
- 사전학습된 LLM을 instruction & corresponding response의 조합에 대해 finetuning
- 고품질의 instructional data를 확보하는 것은 상당히 많은 자원을 필요로 함
- Evaluating LLMs for code
- 대부분의 코드 벤치마크는 LLM의 자연어 설명에 따른 single-function program 생성 능력을 평가
- 충분하지 않은 테스트 케이스는 false negative 문제로 이어질 가능성이 높음
3. Contributions
- LLM으로 하여금 open-source code snippet을 활용하여 더 diverse, realistic, controllable coding instruction data를 생성할 수 있도록 하는 OSS-Instruct 방식을 도입. 이를 활용하여 low-bais & high-quality instruction-tuning data를 획득할 수 있음
- OSS-Instruct & Evol-Instruct 조합에 대해 학습한 Magicoder & MagicoderS 시리즈 모델 구축 (7B 사이즈 모델)
- model weights, training data, source code를 온전히 오픈소스로 공개
4. OSS-Instruct: Instruction Tuning from Open Source
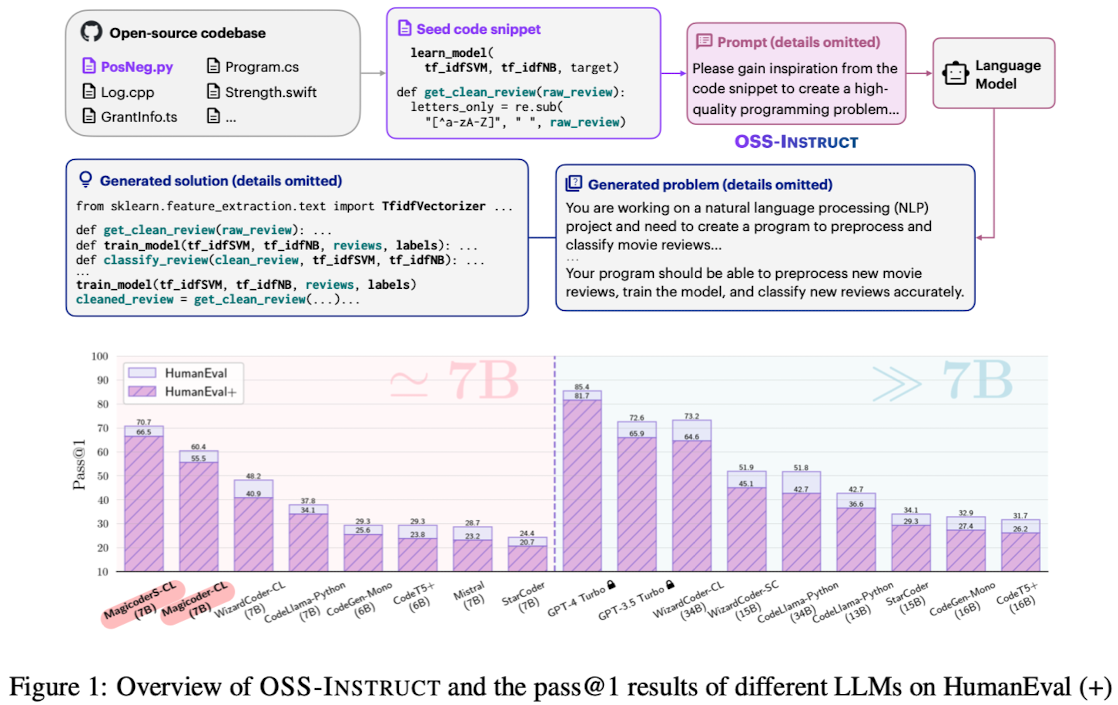
ChatGPT와 같은 LLM를 prompting하여 coding problem과 그에 따른 seed code snippet을 생성하도록 함
4.1. Generating Coding Problems
- The Stack 데이터셋의 filtered version인 starcoderdata를 seed corpus로 채택
- 15개의 연속적인 라인을 추출하여 seed snippet으로 사용하면 모델은 inspiration을 얻고 coding problem을 생성
- 80K 개의 code document로부터 80K 개의 initial seed snippet을 수집
- 40K from Python
- 5K from each of C++, Java, TypeScript, Shell, C#, Rust, PHP, Swift
4.2. Data Cleaning and Decontamination
- 동이랗거나 동일한 seed code snippet을 공유하는 sample들을 제외하는 data cleaning을 수행
- 실제로 data cleaning을 적용했을 때 9개의 샘플만을 제외하게 됨
- OSS-Instruct 데이터셋이 data leakage를 범할 가능성이 굉장히 낮다는 뜻
- starcoderdata가 이미 decontamination 작업을 잘 수행해놓은 데이터셋이기 때문
4.3. Qualitative Examples of OSS-Instruct

- 위 이미지는 OSS-Instruct가 LLG이 inspiration을 얻어 새로운 코드 문제와 솔루션을 생성한 예를 보여주고 있음
- Categories: coding 관련 10개 카테고리를 직접 design
- Similarity with Human Eval: Human Eval 데이터셋과의 코사인 유사도를 TF-IDF를 활용하여 구한 결과, OSS-Instruct 데이터셋은 가장 낮은 유사도를 보임

5. Experiments
- Data generation
- gpt-3.5-turbo-1106을 foundation 모델로 사용하여 cost-effectiveness를 추구
- starcoderdata에서 선택된 code document로부터 1-15 줄을 추출하고 gpt에게 self-contained coding problem과 correct solution을 생성하도록 지시
- Data decontamination
- 75K 개의 OSS-Instruct 데이터셋과 evol-codealpaca-v1 데이터셋을 decontaminate
- Training
- CodeLlama-Python-7B 모델과 DeepSeek-Coder-Base 6.7B를 base LLM으로 사용
- HuggingFace의 transformers 라이브러리를 사용하여 OSS-Instruct를 통해 생성된 75K 합성 데이터에 대해 base model을 fine-tune
- Results
- Python Text-to-Code Generation: HumanEval+, MBPP+
- Multilingual Code Generation: Java, JavaScript, C++, PHP, Swfit, Rust
- Code Generation for Data Science: 데이터 사이언스 라이브러리
- Comparison with DeepSeek-Coder: 8배 적은 token으로 학습했음에도 불구하고 DeepSeek-Coder 모델을 능가




6. Insights
본 연구에서 가장 흥미로운 점은 seed code snippet을 '참고'하지 않고 '직접 학습'한 결과와 비교한 내용입니다.
저의 직관과는 달리 (아마 일반적으로는 직접 학습한 것이 더 좋을 거라고 예상하시겠지만) 전자가 후자에 비해 훨씬 좋은 결과로 이어졌습니다.
그래서 이 모델(Magicoder)과 데이터셋 구축 방식(OSS-Instruct)이 제안된 것이겠죠.
논문에서는 데이터 쌍에 존재하는 상당한 노이즈가 모델 학습에 방해가 되어서라고 추측하고 있습니다.
이것도 결과론적인 해석에 그치지 않나 싶기는 한데..
굳이 직관을 더 발휘해 보자면 새로운, 그러나 품질이 낮은 데이터로 학습함에 따라 catastrophic forgetting이 일어나는 것과 유사한 현상이라고 느껴졌습니다.
결국 모델의 general한 능력은 그대로 발휘하되 말 그대로 inspiration을 불러 일으킬 수 있을 정도의 source만 제공하는 것이죠.
그래서 다른 것보다도 데이터셋에 직접 fine-tuning한 것의 결과가 reference하는 방식의 결과에 비해 훨씬 좋지 않다는 것이 인상적인 것 같습니다.
출처 : https://arxiv.org/abs/2312.02120
Magicoder: Source Code Is All You Need
We introduce Magicoder, a series of fully open-source (code, weights, and data) Large Language Models (LLMs) for code that significantly closes the gap with top code models while having no more than 7B parameters. Magicoder models are trained on 75K synthe
arxiv.org