
주로 분류를 위해 사용되는 함수인 softmax는 딥러닝에서 가장 많이 쓰이는 녀석 중 하나일 겁니다.
이번에 '밑바닥부터 시작하는 딥러닝 1,2권'을 구현하면서 정말 여러 번 코드를 치면서 구현했었는데, 코드의 원리가 생각보다는 이해하기 쉽지 않았던 것 같습니다 🤔
함수 자체는 엄청 간단한데 의외로 역전파 원리는 그렇지 않습니다.
오늘은 이를 코드와 함께 꼼꼼히 살펴보면서 어떻게 구현이 되어있는지, 특히 미분이 왜 이렇게 되는 건지 알아보겠습니다!!
1. softmax 함수 정의하기
우선 총 n개의 클래스가 존재한다는 상황을 가정하겠습니다.
그리고 앞으로 이 함수의 입력은 벡터 a, 출력은 벡터 y, 정답은 벡터 t라고 하겠습니다.
따라서 각 벡터는 n개의 원소로 구성되어 있으므로 a = [a1, a2, ... an], y = [y1, y2, ..., yn], t = [t1, t2, ..., tn]이 됩니다.
함수를 식으로 적으면 다음과 같습니다.
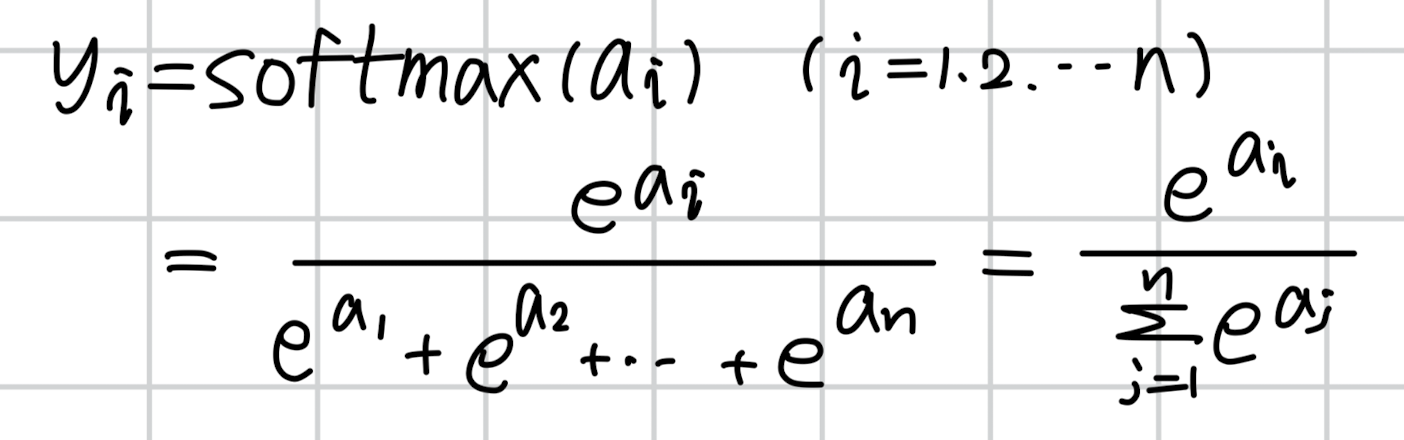
i의 값을 1에서부터 n으로 바꿔가면서 y1, y2, ... , yn을 구해보면 우리는 이 출력의 총합이 1이 될 것임을 알 수 있습니다.
분모는 전부 동일할 것이고 분자의 변수는 a1, a2, ..., an이 될테니 분모와 분자가 같아지게 되겠죠.
이를 softmax라는 이름의 함수로 정의하면 다음과 같습니다.
import numpy as np
def softmax(a):
y = np.exp(a) / np.sum(np.exp(a))
return y
그리고 이를 실행해보면 다음과 같은 결과를 얻을 수 있습니다.
a = np.array([1,2,3,4])
print(softmax(a)) # array([0.0320586 , 0.08714432, 0.23688282, 0.64391426])당연한 이야기지만 softmax(a)의 총합은 1입니다.
2. softmax 함수 변형하기
아주 간단한 위 함수 구현은 향후 overflow 문제를 일으킬 수 있습니다 👿
지수 함수의 특성상 변수에 오는 값이 커지면 그 결과값이 너무 가파르게 커지기 때문이죠.
따라서 정확한 값을 출력하지 못할 가능성이 큽니다.
그래서 이번에는 softmax에 아주 간단한 트릭을 적용해서 출력 결과는 동일하면서도 overflow를 방지해보겠습니다.
식은 다음과 같습니다.
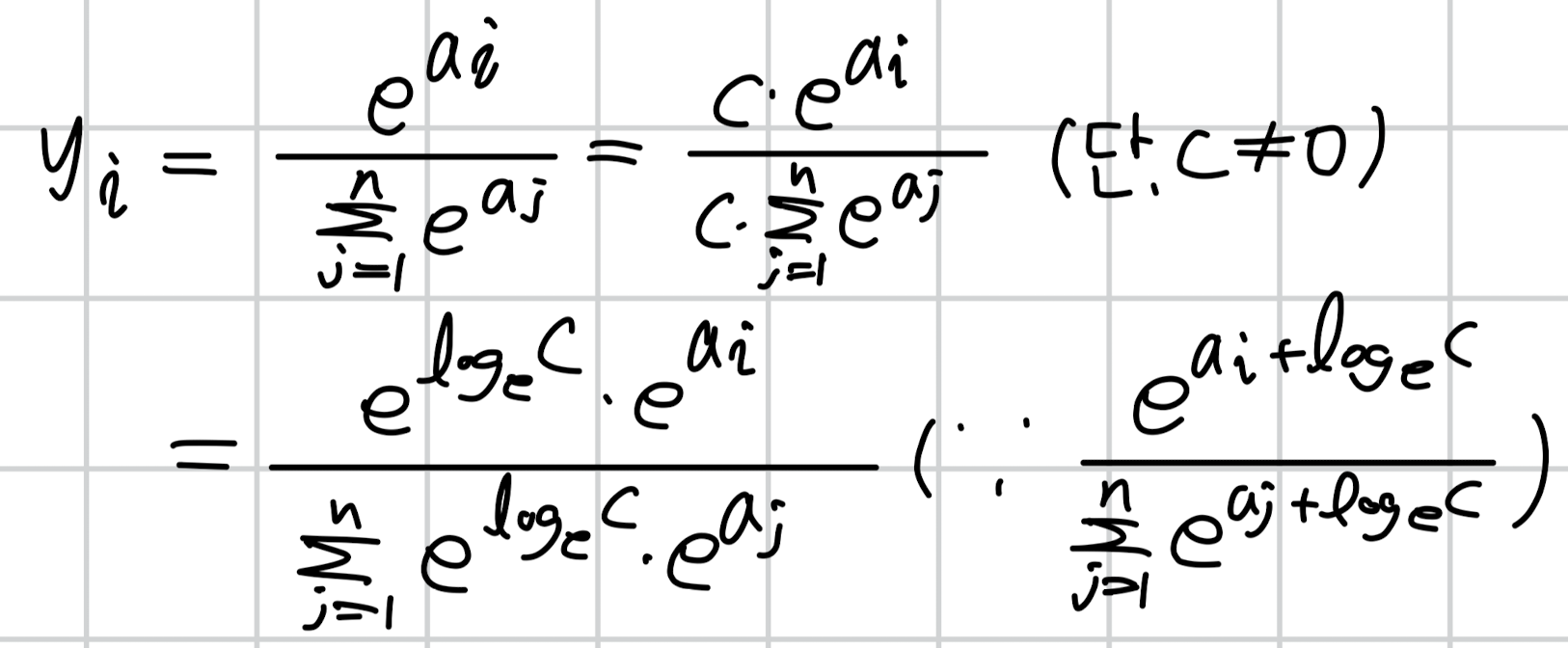
맨 윗줄에 c는 0이 아닌 상수입니다.
분수에서 분자와 분모에 동일한 숫자를 곱해도 값의 변화가 없다는 것은 다들 잘 아시겠죠?? 🤧
그럼 이번에는 주어진 상수 c를 지수 형태로 변경해봅니다.
이는 간단한 지수의 밑변환 공식을 적용한 것입니다.
(참고 블로그 링크: https://color-change.tistory.com/29#google_vignette)
두 번째 줄에서는 지수 법칙에 의해 밑을 e로 삼는 두 항의 지수가 덧셈으로 표현이 됩니다.
(분모도 마찬가지입니다. 시그마는 덧셈이므로 모든 항에 곱셈을 추가해야 하죠)
따라서 분모와 분자에 상수 c를 모두 곱해주면, 결과적으로 지수에 밑을 e로 삼는 log(c)를 더해주는 꼴이 됩니다.
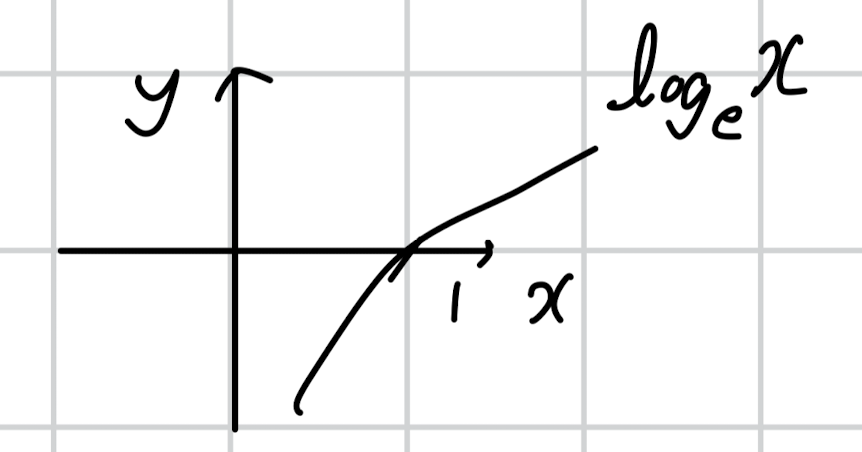
(너무 허졉하지만...) 로그의 그래프는 위와 같은 꼴이죠.
즉, 정의역은 x > 0 이고 공역은 실수 전체입니다.
따라서 '밑을 e로 삼는 log(c)'는 '어떤 실수값이든지 될 수 있다!'는 결론에 이르게 됩니다.
쉽게 말하면 기존 입력 a를 구성하는 모든 원소에 대해 동일한 값을 더하거나 빼더라도 (실수는 음수도 가능하니까요) 그 결과는 처음과 동일하다는 것이죠!! 😲
따라서 우리는 overflow 현상을 방지하기 위해 기존 입력 벡터 a의 모든 원소에서 벡터 a의 최댓값을 빼주도록 하겠습니다.
코드 구현은 다음과 같습니다.
def softmax(a):
a = a - a.max()
y = np.exp(a) / np.sum(np.exp(a))
return y
코드로는 너무나도 간단해서 당황스럽지만(?), 이렇게나 쉽게 구현됩니다.
3. softmax 함수에 미니배치 추가하기 (1)
다음은 미니배치 추가입니다.
지금까지 코드들은 전부 딱 한 개의 샘플에 대해서만 동작하는 코드입니다.
예를 들어 n차원으로 구성된 입력 벡터가 두 개인 경우, 입력 차원은 (2, n)이 되므로 이전 코드로는 처리가 어렵습니다.
구체적으로는 다음과 같습니다.
a = np.array([[1,2,3,4],
[5,6,7,8]])
print(np.max(a)) # 8
print(a - np.max(a)) # [[-7 -6 -5 -4]
# [-3 -2 -1 0]]
numpy.max 함수는 전체 배열의 최댓값을 반환하므로 우리가 원하는 결과를 얻을 수 없게 되죠 🥲
(각 샘플에 대해서는 각 샘플의 최댓값을 빼야겠죠?)
따라서 우리는 각 샘플마다의 최댓값을 뺄 수 있도록 axis 개념을 잘 활용해야 합니다!
두 가지 정도의 방식을 살펴볼테니 차근차근 따라가 봅시다.
첫 번째 방식입니다.
def softmax_1(a):
# a: (b, n)
if a.ndim == 2:
# a.max(axis=1, keepdims=True): (b, 1)
a = a - a.max(axis=1, keepdims=True)
a = np.exp(a)
# np.sum(a, axis=1, keepdims=True): (b, 1)
y = a / np.sum(a, axis=1, keepdims=True)
elif a.ndim == 1:
# 이전 구현과 동일
a = a - np.max(a)
y = np.exp(a) / np.sum(np.exp(a))
return y
a_1 = np.array([1,2,3,4])
a_2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,13]])
print("ndim:1")
print(softmax_1(a_1))
print("\nndim:2")
print(softmax_1(a_2))
# ndim:1
# [0.0320586 0.08714432 0.23688282 0.64391426]
# ndim:2
# [[0.0320586 0.08714432 0.23688282 0.64391426]
# [0.0320586 0.08714432 0.23688282 0.64391426]
# [0.01521943 0.0413707 0.11245721 0.83095266]]
여기서 b는 batch를, ndim은 해당 array의 차원수를 뜻합니다.
'ndim == 2' 조건은 입력이 batch 단위로 주어졌다는 것을 의미하게 됩니다.
따라서 이때는 'axis = 1', 즉 열을 기준으로 최댓값을 구해 각 행에 대해 빼줍니다.
😳..
아마 축 개념이 익숙치 않은 경우 여기서 조금 헷갈리실텐데, 배열의 차원수를 천천히 생각해 봅시다.
a는 현재 (b, n) 차원입니다.
이때 앞에서부터 축의 번호를 매기므로, axis = 0 = b, axis = 1 = n이 됩니다.
따라서 n차원 중에서 가장 큰 값을 골라야 하는 것입니다. (이 행위를 b번 반복하게 됨)
우리가 사용한 예시인 a_2의 첫 행을 보면 [1,2,3,4]입니다. 이것이 n = 4 차원일 때의 예시이므로 여기에서의 최댓값 4를 찾습니다.
다음으로 두 번째 행은 [5,6,7,8] 이므로 최댓값 8을, 마지막 세 번째 행에서는 최댓값 13을 추출합니다.
그런데 keepdims=True 옵션으로 인해 기존의 차원수(ndim==2)가 유지되어야 합니다.
따라서 a.max(axis=1, keepdims=True)의 결과는 위 예시에서 [[4], [8], [13]]이 되고 차원은 (3, 1)이 됩니다.
그런데 a의 형상은 (3, 4)이므로 여기서 (3, 1) 차원의 벡터를 빼주면 브로드 캐스팅이 일어납니다.
즉, (3,1) 차원의 벡터가 (3,4)차원으로 복사되어 뺄셈을 수행하게 되죠.
다시 말하자면 [[4], [8], [13]] -> [[4,4,4,4], [8,8,8,8], [13,13,13,13]] 이 됩니다.
이 값을 지수 함수의 변수로 던져주면 됩니다.
하나 더 주의할 것은 np.sum 함수를 적용할 때도 'axis=1' 이어야 한다는 점입니다.
각 샘플 케이스를 나타내는 행(axis=0)이 아니라 클래스의 개수를 나타내는 차원(n)에 대한 sum을 해줘야 된다는 뜻이죠.
추가로 ndim:2 의 결과를 좀 더 자세히 보시면 재밌는 것을 알 수 있습니다.
첫 번째 행의 결과값과 두 번째 행의 결과값이 완전히 동일합니다!!
이는 위에서 언급한 '입력 벡터의 모든 원소에 동일한 값을 더하거나 빼더라도 함수값은 동일하다'는 내용과 완전히 일치하는 결과입니다 😄
(ndim == 1인 경우는 이전과 동일하므로 설명을 생략합니다)
4. softmax 함수에 미니배치 추가하기 (2)
조금 다른 방식으로 배치를 처리해도 동일한 결과를 얻을 수 있습니다.
코드부터 살펴보도록 하죠.
def softmax_2(a):
# a: (b, n)
if a.ndim == 2:
a = a.T # (a.T): (n, b)
a = a - a.max(axis=0) # a.max(axis=0): (b,)
y = np.exp(a) / np.sum(np.exp(a), axis=0) # np.sum(np.exp(a), axis=0): (b,)
return y.T # (n, b) -> (b, n)
elif a.ndim == 1:
# 이전 구현과 동일
a = a - np.max(a)
y = np.exp(a) / np.sum(np.exp(a))
return y
a_1 = np.array([1,2,3,4])
a_2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,13]])
print("ndim:1")
print(softmax_2(a_1))
print("\nndim:2")
print(softmax_2(a_2))
# ndim:1
# [0.0320586 0.08714432 0.23688282 0.64391426]
# ndim:2
# [[0.0320586 0.08714432 0.23688282 0.64391426]
# [0.0320586 0.08714432 0.23688282 0.64391426]
# [0.01521943 0.0413707 0.11245721 0.83095266]]
이번에도 'ndim == 2' 조건만을 살펴보도록 하겠습니다.
a.T에 사용된 '.T'는 transpose를 의미하는데 여기서는 단순하게 행과 열을 뒤바꾸었다고 생각할 수 있습니다.
그래서 a_2를 입력으로 주었을 때 출력을 살펴보면 다음과 같습니다.
array([[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11],
[ 4, 8, 13]])
기존에 한 행 내에서 펼쳐져 있던 [1,2,3,4]가 여러 행에 걸쳐 내려온 것을 알 수 있습니다.
이제 행 단위가 아니라 '열 단위'로 하나의 샘플을 의미하게 되었다는 것이죠.
그래서 이번에 overflow 방지 대책으로 최댓값을 빼줄 때는 한 행 내의 최댓값이 아니라 한 열 내의 최댓값을 구해주어야 합니다.
즉, (n, b) 차원에서 n개 값들 중에 가장 큰 것을 구해야 하므로 a.max(axis=0)이 되는 것이죠.
이를 구해서 뺄셈을 수행하면(a - a.max(axis=0)) 결과는 다음과 같습니다.
array([[-3, -3, -4],
[-2, -2, -3],
[-1, -1, -2],
[ 0, 0, 0]])각 열의 최댓값 4, 8, 13을 각 열별로 빼준 것을 알 수 있습니다.
이때도 이전과 마찬가지로 브로드캐스팅이 일어난 것이죠.
이제 열에 포함된 각 원소를 입력값으로 갖는 소프프맥스 스코어를 구해야 합니다.
분모에는 열에 포함된 원소를 모두 더한 값이 들어가야겠죠?
그래서 마찬가지로 axis=0인 sum 연산을 수행해주면 됩니다.
즉, [-3, -2, -1, 0] (세로로 훑어서 구한 값)을 모두 더한 -6, 같은 방식으로 구한 -6, -9가 sum 연산을 통해 획득됩니다.
그리고 이것은 (n, b) 차원의 행렬을 (b) 차원으로 바꾸게 되죠.
(axis에 해당하는 축이 사라집니다)
분자인 np.exp(a)는 전치된 a를 입력으로 받아 여전히 (n, b) 차원입니다.
따라서 분모에 (b) 차원이 오게 되면 분모가 브로드 캐스팅될 것임을 알 수 있습니다.
y의 출력은 다음과 같습니다.
[[0.0320586 0.0320586 0.01521943]
[0.08714432 0.08714432 0.0413707 ]
[0.23688282 0.23688282 0.11245721]
[0.64391426 0.64391426 0.83095266]]
이제 y를 반환해야 하는데, 우리가 원하는 y의 차원은 (b, n)입니다.
즉, 행과 열이 전치된 상황이므로 이를 원래대로 되돌려 놓아야 합니다.
따라서 return y.T 를 해주면 됩니다.
transpose를 통해 차원수를 유지하면서도 연산을 잘 수행했으나 직관성이 떨어지는 것 같아 이전의 구현 코드보다 더 선호되기는 어렵다는 생각이 드네요!
5. Softmax 클래스 구현하기
지금까지는 softmax 함수를 구현했습니다.
이번에는 이 함수를 활용하는 클래스를 구현해보려고 해요.
왜 클래스를 사용해야 할까요?
답변은 아주 간단합니다.
이를 '계층(layer)'으로 사용하기 위해서죠.
어떤 벡터를 확률값으로 변환해주는 softmax까지 도달하기 이전의 상황을 상상해보세요.
맨 처음의 입력을 가중치와 곱하고 편향을 더해주고 활성화 함수를 거치고 등등..
우리는 이러한 과정을 각각 하나의 계층으로 만들어 줬습니다.
중요한 것은 통일된 클래스 형식을 따라가는 것입니다.
동일한 인스턴스 변수와 메서드를 사용하는 것이죠.
즉, 어떤 계층이든지 간에 params, grads 변수를 init에서 초기화 해주어야 하고, forward / backward 메서드를 포함해야 하죠.
이렇게 해야지만 나중에 연쇄적으로 forward / backward를 수행하기가 편해지기 때문입니다!
Softmax 클래스
각설하고, Softmax 계층을 클래스로 구현하되, 여기서는 forward 까지만 다루겠습니다.
class Softmax:
def __init__(self):
self.params, grads = [], []
self.out = None
def forward(self, a):
out = softmax(a)
self.out = out
return self.out
def backward(self, dout):
# dout = (∂L/∂y)
da = self.out * dout
sumda = np.sum(da, axis=1, keepdims=True)
da -= self.out * sumda
return da
각 요소를 하나씩 살펴봅시다.
1) __init__
각 계층에 포함된 파라미터와 미분계수가 저장될 공간을 만들어줘야 합니다.
지금 당장에는 사용되지 않지만 전체 학습을 돌리는 코드에서 활용되는 변수들입니다.
또한 self.out 변수를 미리 선언해줌으로써 이 계층의 최종 출력을 알립니다.
2) forward
입력 벡터 a에 대해 softmax 함수를 적용합니다.
단, 미니 배치 단위로 입력이 들어올 수 있다는 점에 유의합니다. (2차원 배열)
위에서 코드를 구현할 때 이미 배치 처리까지 완료했습니다.
3) backward 🔥🔥🔥
저는 이 구현을 이해하는데 엄청나게 많은 시간을 쏟았습니다.
softmax가 cross entropy와 같은 손실 함수와 결합되면 미분이 너무 간단한데 단독으로 쓰이는 상황을 이해하는게 굉~장히 어렵습니다.
(저만 그럴 수도 있지만..)
그래서 내용을 완전히 뜯어보려고 합니다.
우선 softmax 함수의 미분 계수를 식으로, 그리고 그래프로 구해보겠습니다.
3-1) softmax 미분 계수 그래프로 구하기

맨 처음 가정했던 것을 그래프로 표현하면 위와 같습니다.
입력 벡터 a, 출력 벡터 y, 타겟 벡터 t 인 것이죠.
이에 대해 t와 y 사이의 손실을 계산하고 편미분을 통한 역전파를 수행하면 아래와 같은 그림이 됩니다.
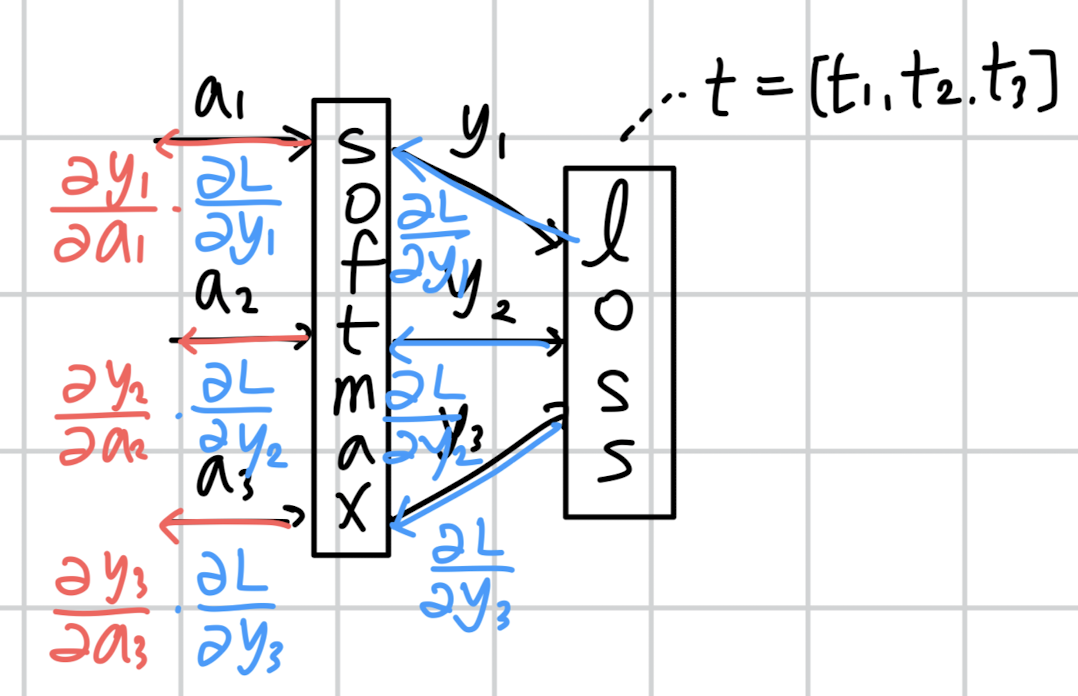
Loss를 y에 대해 각각 편미분하고, y를 a에 대해 각각 편미분한 것을 곱해주는 양상입니다.
이렇게만 보면 너무 간단한데, 사실 softmax는 이러한 구조가 아닙니다.
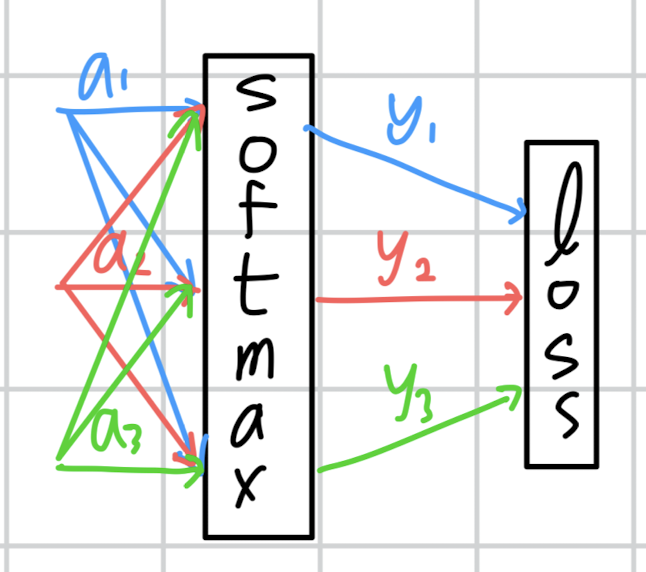
각 입력이 다른 출력에 영향을 주는 구조로 표현해야 softmax에 대한 올바른 도식이라고 볼 수 있을 것입니다.
여기서 잘 생각해볼 것은 하나의 노드(예를 들어 a1)가 여러 개의 출력을 만들어 내기 위해 '복사'되고 있다는 점입니다.
이를 (밑시딥 구현 공부를 해보셨으면 알겠지만) repeat 계층으로 생각할 수도 있겠죠.
즉, 이에 대한 미분은 각 출력으로부터 얻은 미분 계수의 합이 된다는 것입니다.
역전파를 시각화하면 다음과 같습니다.
(a1 하나에 대해서만 표현해보겠습니다)
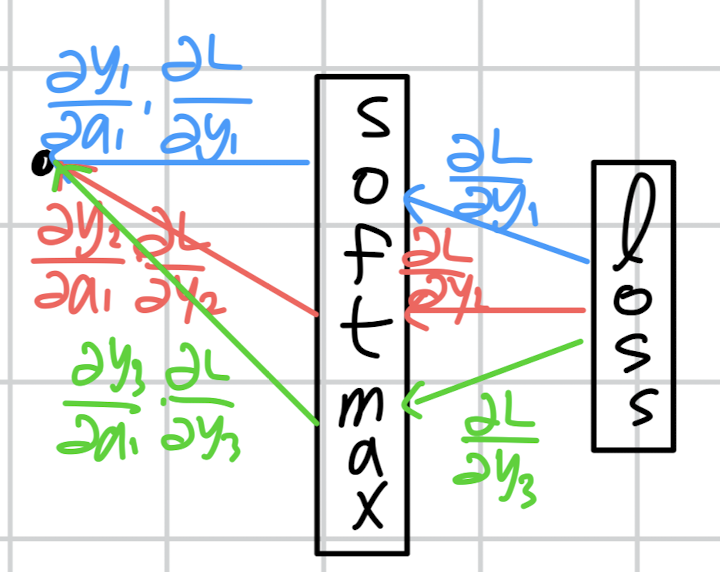
a1 노드에 세 개의 미분 계수가 흘러 들어오는 것을 볼 수 있습니다.
그래서 세 개의 미분 계수를 합해준 것이 손실 L에 대한 a1의 미분 계수가 됩니다.
이처럼 소프트맥스는 하나의 노드가 다른 출력에도 영향을 주는 구조이기 때문에 미분을 식으로 표현해도 조금 독특하게 표현됩니다.
3-2) softmax 미분 계수 식으로 구하기

softmax 함수를 미분할 때, 크게 i = j인 경우와 그렇지 않은 경우로 나눕니다.
소프트맥스 함수의 결과값을 생각해보면 이를 편미분 한다는 것 자체가, 하나의 출력 결과에 대한 여러 입력의 영향력을 각각 파악하겠다는 뜻입니다.
따라서 하나의 출력(i)에 대해 여러 개의 입력(j)이 주어지므로 j 번 편미분 해야 하는 것입니다.
결국 주어진 y_{i}를 a_{j}에 대해 편미분 하는데 총 j번 인 것이고, 이때 한 번은 i = j가 되겠죠.
위에 식이 전개되는 과정을 살펴보면 가장 먼저 알아야 하는 것은 몫의 미분법입니다.
(분수 형태로 표현된 함수를 미분하는 방법으로, 기억이 나지 않는 분들은 링크를 참고해보세요)
규칙에 따라 분모는 제곱이 되고, 분자는 각각 미분을 적용한 것의 차로 구할 수가 있게 됩니다.
식을 잘 정리하면 처음 y_{i}로 정의한 것을 바탕으로 식을 깔끔하게 정리할 수가 있게 되죠.
i != j 일 때가 조금 헷갈릴 수 있는데, 이때는 y_{i}를 a_{j}에 대해 편미분한 것입니다.
따라서 분자의 경우 a_{j} 항을 포함하고 있지 않으므로 미분 결과가 0이 등장하게 된 것입니다.
시그마의 경우 합연산이므로 그 중에 a_{j} 가 포함된 항에 대한 미분 결과만 살아남은 것으로 이해할 수 있습니다.
(지수 함수의 미분이 이해되지 않는 분은 링크를 참고해보세요)
이제 그래프와 식을 종합해보면 하나의 노드(예를 들어 a1)에 대한 여러 미분 계수(class 개수가 되겠죠)를 누적합해줘야 한다는 것을 이해할 수 있을 것입니다.
그런데 아무리봐도 코드와 잘 매칭이 되지 않습니다.
backward 코드를 다시 살펴보죠.
def backward(self, dout):
# dout = (∂L/∂y)
da = self.out * dout
sumda = np.sum(da, axis=1, keepdims=True)
da -= self.out * sumda
return da
시작부터 이상합니다.
대체 출력 y와 미분 계수 ∂L/∂y를 왜 곱하고 시작할까요..?
그리고 이걸 갑자기 합치고는 출력과 다시 곱하고.. 이것의 의미가 뭘까요?
예시 하나를 바탕으로 위 코드의 실행 과정을 살펴보겠습니다.

우선 첫 행의 da = self.out * dout 입니다.
기존의 출력 y에 이전 층에서 흘러 들어온 미분 계수가 각각 곱해진 것을 알 수 있습니다.
이는 원래 역전파 과정에서 이전 계층의 미분 계수를 곱하는 것이기 때문에 너무 당연한 이야기입니다.
하지만 소프트맥스는 하나의 입력 노드가 여러 출력에 영향을 주기 때문에 다른 출력에 대한 미분 계수는 아직 반영되지 않은 상태입니다.
즉, a1을 기준으로 한다면 y1에 대한 미분 계수는 처리했지만 y2, y3에 대한 것은 적용하지 않은 상태죠.
그래서 모든 미분 계수를 하나로 합칩니다.
sumda = np.sum(da, axis=1, keepdims=True)
우리는 i = j 가 아닌 경우에 대한 케이스에 대해서는 미분 계수가 -y_{i} * y_{j}로 구해진다는 것을 위에서 확인했습니다.
각 케이스를 더해야 하므로 시그마 연산이라 생각하고 sum을 미리 취해주면 그 결과가 동일해질 수 있겠죠.
이를 표현한 것이 마지막 행의 '-self.out * sumda' 입니다.
즉, 각 미분계수를 합한 것을 기존의 출력과 곱해서 빼주게 되면, '-y_{i} * y_{j}' 연산에 시그마를 취한 것이 되죠.
하지만 문제가 하나 있습니다.
바로 이 시그마 연산에 i = j 인 케이스가 포함된다는 것입니다.
그래서 이를 시그마에서 분리하여 i = j 인 항끼리 모으고 나머지를 따로 둡니다.
이 과정이 그림에서 빨간색으로 표시된 부분입니다.
이를 통해 i = j 일 때와 그렇지 않을 때의 적절한 미분 계수에 이전 계층에서 흘러들어온 미분 계수가 곱해지고 있다는 것을 알 수가 있습니다.
그래서 이 방식을 간단히 요약하면
1) i = j 인 케이스의 미분 계수를 구하는 것처럼 기존 출력 y와 이전 계층에서 흘러 들어온 미분 계수를 곱한다. 이때 y(1-y)에서 -y 에 대해서는 아직 연산하지 않은 상태이다.
2) 미분 계수를 모두 합쳐서 i != j 인 경우의 미분 계수를 구할 준비를 한다. sum 연산이 시그마를 의미하는 것으로 볼 수 있다.
3) 두 연산을 결합하고 i = j 인 경우와 그렇지 않은 경우로 식을 정리한다.
가 됩니다.
사실 세 줄짜리 코드를 이렇게까지 봐야하나..? 싶기도 하지만..
개인적으로는 엄청나게 구현이 신기하게 되어있다는 생각에 뜯어보다가 위 내용들을 다루게 되었네요.
6. Softmax with Cross Entropy
잘 아시다시피 분류를 위한 softmax 연산은 cross entropy와 자주 함께 쓰입니다.
물론 논리적으로 타당하기 때문인 것도 그 이유이지만, 연산의 효율성 그리고 직관성때문이라는 것도 둘을 짝꿍처럼 붙여놓는 핵심적인 이유가 됩니다.
우선 Cross Entropy를 밑시딥 교재에 나온 것처럼 그래프 형태로 forward / backward를 표현해보겠습니다.
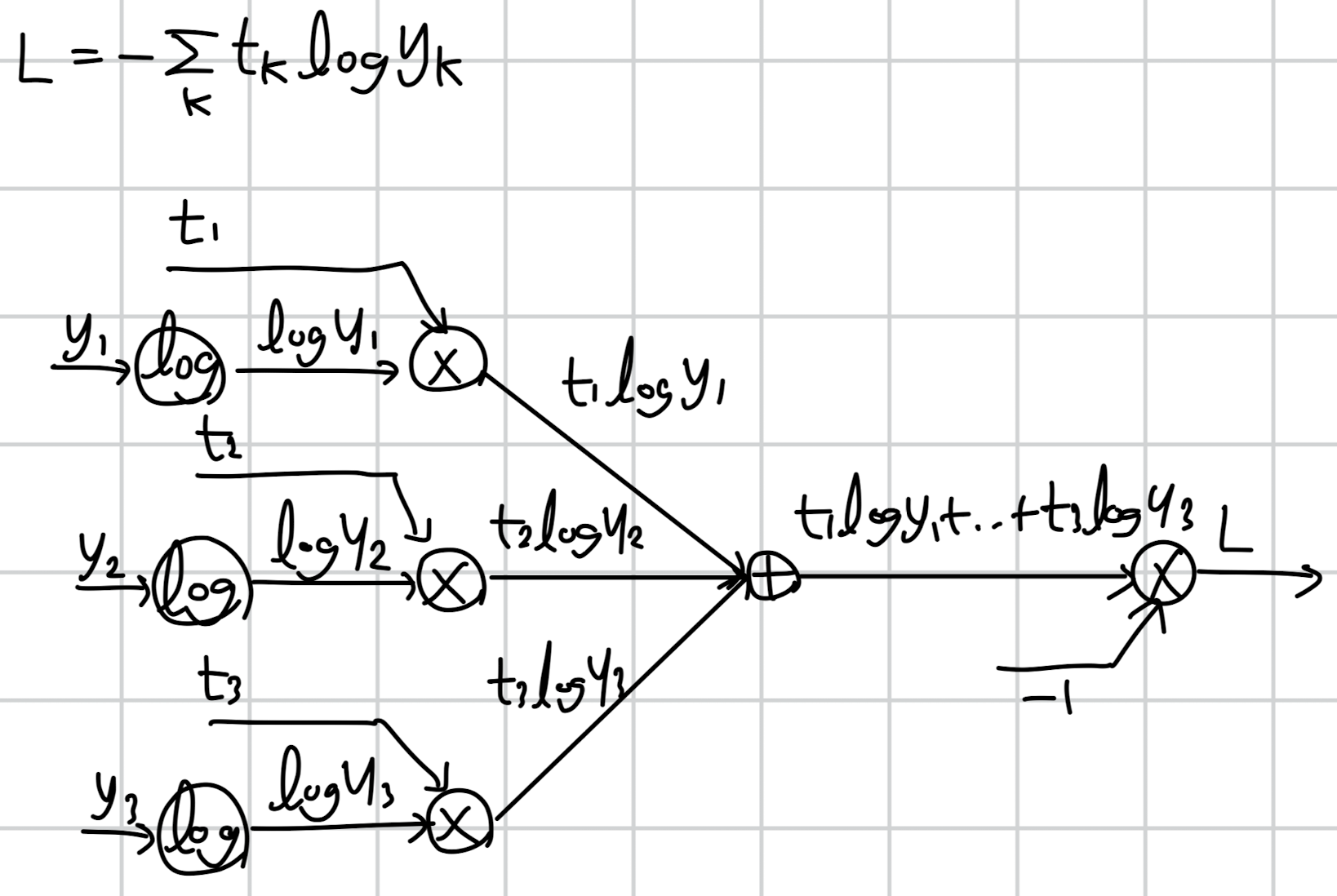
입력 y1에 로그를 취하고, 이를 t1과 곱한 것을 다른 항들과 모두 더하고, 여기에 -1을 곱하면 L 식이 구현됩니다.
이제 역전파를 진행할 건데, 처음 자기 자신에 대한 미분 계수는 1로 시작됩니다.

여기에서의 핵심은 각 연산마다 어떻게 미분 계수를 구하냐겠죠.
곱셈 연산은 다른 입력을 곱해서 전달하면 됩니다.
예를 들어 y = a * b 라고 한다면 y에 대한 a 미분 계수는 b, b 미분 계수는 a가 될 것입니다.
서로 반대 변수를 취해 전달하는 것이죠.
그래서 처음에는 1이 -1로 바뀝니다.
덧셈 연산은 그대로 전달하는 것 뿐입니다.
정확히는 덧셈을 수행한 것만틈 복사해서 다시 뿌려주는 거죠.
그래서 전달된 -1이 세 갈래로 뻗어나가게 됩니다.
그리고 다시 곱셈 연산을 만납니다.
위에서와 마찬가지로 반대편의 항을 곱해서 전달하면 됩니다.
따라서 -1에 반대편 항인 t1, t2, t3를 각각 곱한 -t1, -t2, -t3가 전달됩니다.
마지막은 로그입니다.
y = log x 의 경우 미분을 취하면 1 / x가 됩니다.
(기억이 안 나는 경우 링크 참고!)
따라서 전해져 내려온 미분 계수에 입력값의 역수를 취해 곱해줍니다.
즉, -t1, -t2, -t3에 각각 1/y1, 1/y2, 1/y3을 곱하면 됩니다.
이 최종 결과가 softmax 계층에 전달되는 dout이 됩니다!!
이어서 softmax의 순전파를 다시 살펴볼텐데 이번엔 자세한 설명을 생략하겠습니다.
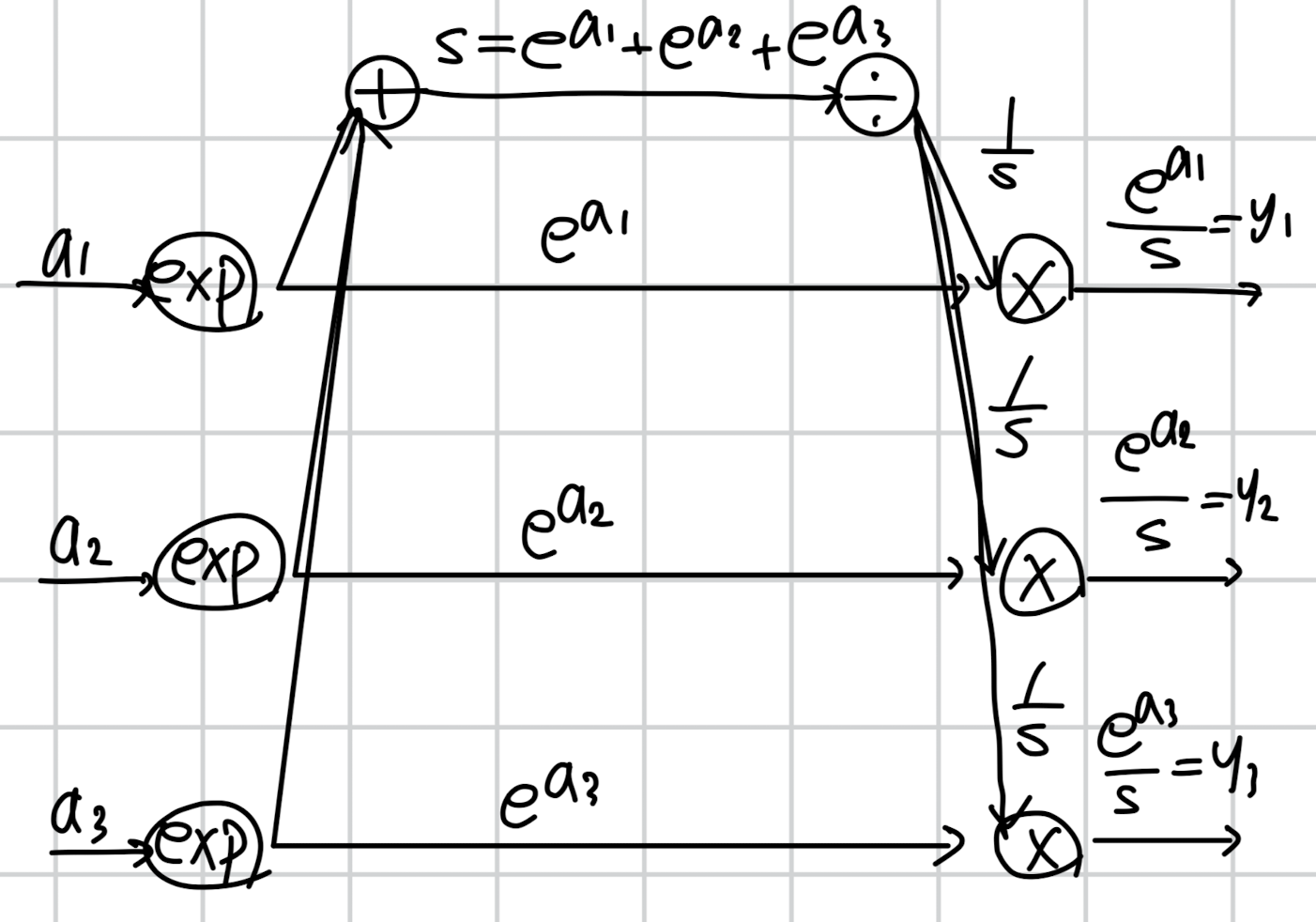
아까는 굉장히 단순하게 표현된 것을 식에 맞게끔 풀어 표현한 그림입니다.
입력에 exp를 취하고 그 값들을 전부 더하여 분모로 취함과 동시에 그 값을 각각 분자로 취한 것이 y1, y2, y3가 되죠.
이때 exp 값들을 합쳐서 S로 칭하겠습니다.
위에서 구한 cross entropy의 미분 계수를 그대로 가져다 쓰면서 역전파를 수행하겠습니다.
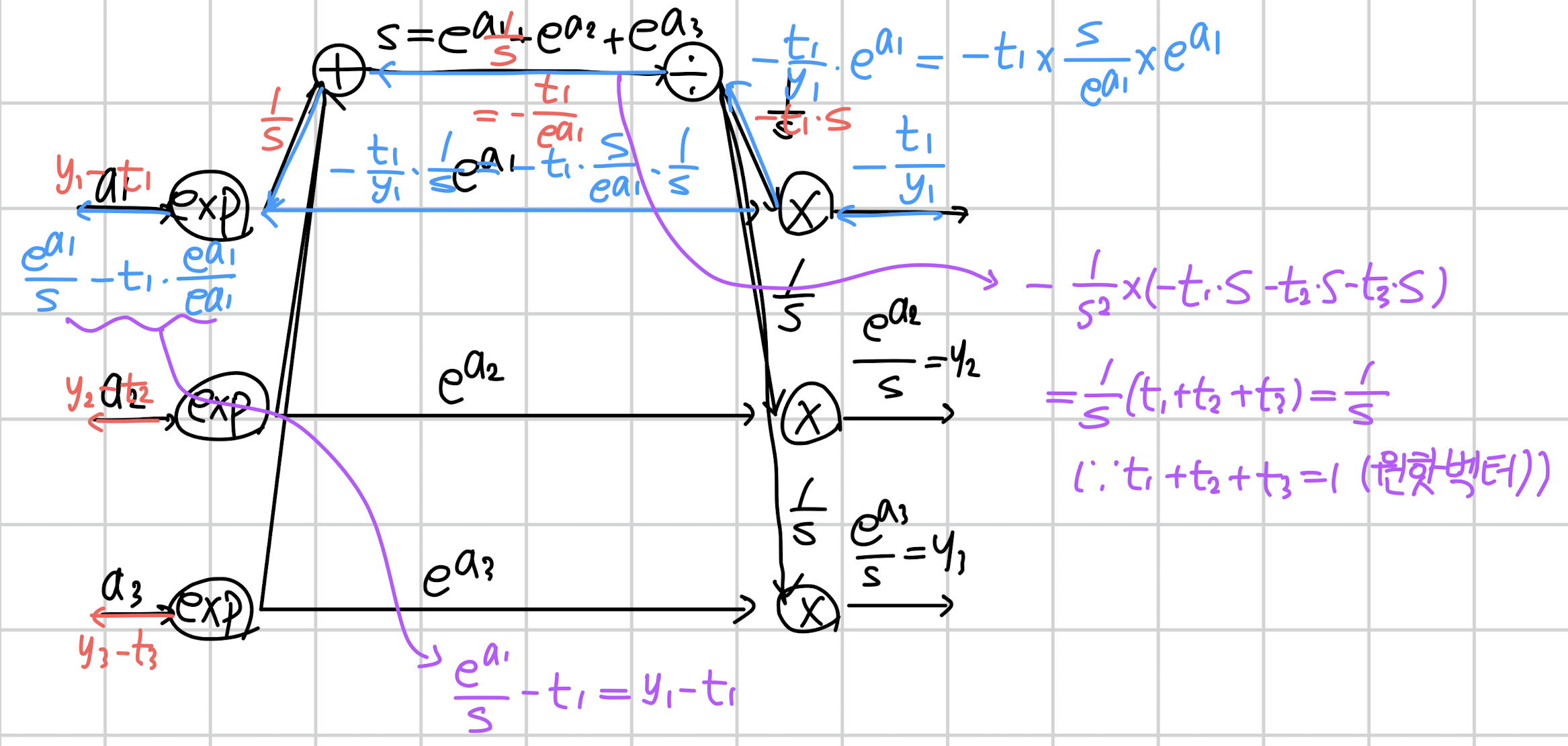
천천히 살펴보도록 하겠습니다.
우선 처음 만나는 곱셈 연산입니다.
곱셈은 반대편의 입력을 곱해서 가져간다고 했죠.
그래서 이전에서 흘러내려온 -t1/y1에 exp(a1)을 곱해서 위로 올려보냅니다.
반대로 exp(a1)에는 1/s을 곱해서 보내주고요.
이때 S는 exp(a1) + exp(a2) + exp(a3)로 정의되어 있기 때문에 이를 적절히 활용하여 가장 간단한 형태로 만들어줍니다.
결과적으로 나눗셈 방향으로 올라가는 것은 -t1*S, exp(a1)으로 흘러가는 것은 -t1/exp(a1)이 됩니다.
다음은 나눗셈 연산이 갈라져있다는 것에 주목합시다.
이는 S를 복사(repeat)하여 다른 연산을 수행한 것이므로, 역전파 시에는 미분 계수를 누적합해야 합니다.
따라서 -t1*S + (-t2*S) + (-t3*S)를 계산해줍니다.
동시에 나눗셈 연산의 미분이 어떻게 되는지도 생각해보세요.
y = 1/x를 미분하면 -1/x^2가 됩니다.
(1/x = x^(-1) 이기 때문에 이를 미분하면 되죠)
따라서 미분 계수를 누적합한 -t1*S + (-t2*S) + (-t3*S)에 -1/S^2을 곱해줍니다.
결과적으로는 아주 간단하게 1/S이 되는 것을 알 수 있습니다.
(이 과정은 보라색으로 표현되어 있습니다)
덧셈 노드는 미분 계수를 그대로 흘려보낸다고 했으니 1/S이 그대로 전달됩니다.
이제 마지막 exp 노드입니다.
exp는 미분을 수행하면 자기 자신이 반환됩니다.
따라서 exp(a1)이 반환되고 이를 1/S과 곱해줍니다.
또한 exp 노드도 갈라져 있기 때문에(repeat) 이를 -t1/exp(a1) 과도 곱합니다.
두 곱셈 결과를 더해주면 y1-t1 으로 정리할 수 있습니다.
(보라색으로 표현되어 있습니다)
동일한 과정을 a2, a3에 대해서도 수행해주면 softmax + cross entropy의 역전파 결과가 (y - t)로 일반화된다는 것을 알 수 있습니다 😲😲😲
Cross Entropy
이제 softmax를 cross entropy와 묶어서 사용하는 이유가 납득이 되네요!!
좋습니다. 그럼 이제 마지막으로 코드를 구현해보도록 하죠.
def cross_entropy_error(y, t):
if y.ndim == 1: # 1차원인 경우 배치 처리할 때와 동일하게 2차원으로 맞춰주기
y = y.reshpae(1, y.size)
t = t.reshape(1, t.size)
if t.size == y.size: # 원 핫 벡터를 레이블 인덱스로 변환하기
t = t.argmax(axis=1)
batch_size = y.shape[0] # 샘플 개수로 나눠 평균 취하기
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
우선 cross entropy 함수 구현입니다.
분류 문제에서의 타겟은 주로 단 한 개의 값만 1이고 나머지는 0인 원핫 벡터로 주어집니다.
예를 들어 3개를 분류하는 상황이라면, [1, 0, 0], [0, 1, 0], [0, 0, 1] 셋 중 하나가 타겟이 될 수 있죠.
하지만 우리는 보다 효율적으로 코드를 작성하기 위해 이를 [0], [1], [2]로 바꿔줄 것입니다.
(마지막 return 부분에 열에 대한 인덱스가 됨)
t.size == y.size는 벡터 t가 원핫 벡터 형태라는 것을 의미하므로 레이블 인덱스로 바꿔주게 되는 것입니다.
return 부분은 조금 까다로운데 'y[np.arange(batch_size), t]' 에만 집중해보세요.
array y의 형상은 (batch, class) 입니다.
예를 들어 두 개의 샘플을 세 개 카테고리로 분류한다면 (2, 3)이 되겠네요.
이때 정답 레이블은 각 샘플별로 0과 1이라고 가정하겠습니다.
y = np.array([[0.1, 0.2, 0.7],
[0.2, 0.3, 0.5]])
batch_size = y.shape[0]
print(f"batch size: {batch_size}") # 2
t = np.array([[1, 0, 0],
[0, 1, 0]])
t = t.argmax(axis=1)
print(f"t: {t}") # [0 1]
print(f"y[np.arange(batch_size), t]: {y[np.arange(batch_size), t]}") # [0.1 0.3]
이 예시를 보면 y의 각 샘플에 'np.arange(batch_size)'를 이용하여 행으로 접근하고, 레이블 인덱스 t를 이용해 원하는 열에 접근하는 것을 알 수 있습니다.
이에 따라 정답에 해당하는 0.1과 0.3을 각 샘플별로 추출할 수 있게 된 것입니다.
이런 식으로 코드를 짜는 이유는 살펴본 것처럼 t가 주로 원핫 벡터이기 때문입니다.
일반적인 분류에서는 정답이 하나이므로 다른 케이스, 즉 t=0인 케이스는 손실값에 포함되지 않습니다.
원래 수식을 생각해보시면 t * np.log(y) 라는 것을 알 수 있고, 이때 t=0이면 결과값이 0이 되기 때문입니다.
Softmax + Cross Entropy
이제 이 cross_entropy_error를 활용한 최종 클래스를 살펴보겠습니다.
class SoftmaxWithLoss:
def __init__(self):
self.params, grads = [], []
self.y = None # 소프트맥스 출력값
self.t = None # 정답 레이블 인덱스
def forward(self, x, t):
self.t = t
self.y = softmax(x)
if self.t.size == self.y.size: # 원핫 벡터인 경우 레이블 인덱스로 변환
self.t = self.t.argmax(axis=1)
loss = cross_entropy_error(self.y, self.t)
return loss
def backward(self, dout=1):
batch_size = self.t.shape[0] # 샘플 개수 체크
dx = self.y.copy() # 입력을 복사
dx[np.arange(batch_size), self.t] -= 1 # 정답 인덱스에 접근하여 -1
dx *= dout # 이전 계층 미분 계수 곱해주기
dx = dx / batch_size # 샘플 개수로 나눠 평균 취하기
return dx
1) __init__
모든 클래스들은 params, grads 변수를 담을 공간이 필요합니다.
그리고 소프트맥스 함수의 출력값과 레이블 인덱스를 담을 변수를 할당해줍니다.
2) forward
소프트맥스 함수에 넣을 x, 그리고 레이블 t를 입력으로 받습니다.
cross_entropy_error에도 원핫 인덱스 처리를 해주긴 하지만 한 번 더..? 점검하고 들어갑니다.
우리가 클래스 인스턴스를 생성해 얻고 싶은 것은 softmax를 통해 얻은 결과를 타겟과 비교해 얻은 손실(loss)값입니다.
따라서 이를 return 해주면 됩니다.
3) backward
여기서 주의할 점은 self.y를 copy한다는 것입니다.
미분 계수를 구해야 하는데 기존 출력값을 변경하면 안되기 때문에 새로운 주소를 할당하며 값만 복사하는 것이죠.
다음은 cross_entropy_error를 구현할 때와 비슷합니다.
np.arange(batch_size)를 통해 행에 접근하고, self.t를 통해 열에 접근하게 되는 것이죠.
그런데 왜 1을 빼줄까요?
softmax with cross entropy의 미분 계수를 다시 떠올려 봅시다.
'y - t', 아주 심플하게 정리되었죠.
그런데 타겟인 t는 어차피 1 또는 0입니다.
물론 이를 전부 레이블 인덱스로 바꿔주었기 때문에 실제로 t는 그냥 전부 1입니다.
따라서 'y - t'는 'y - 1'이 됩니다.
이를 아주 간단히 인덱싱해서 처리한 코드가 'dx[np.arange(batch_size), self.t] -= 1'입니다.
이제 이전 계층에서 전해져 온 미분 계수(dout)를 곱해주면 됩니다.
(y - t) * dout 연산을 해야 되니까 괄호 안쪽부터 순서대로 계산한 것으로 이해할 수 있습니다.
이를 샘플 개수만큼 나눠주면 되겠죠.
softmax 단독으로 쓰일 때 backward를 이해했던 것에 비하면 구현을 이해하기가 훨씬 쉽죠 :)
이상으로 softmax 함수, Softmax 클래스, cross_entropy_error, SoftmaxWithLoss 클래스 구현에 대해 알아보았습니다.
개인적으로는 softmax 함수가 이렇게까지 어려울 일인가 했는데 많은 걸 배우게 됐네요..
별 거 아닌 녀석이라고 생각했는데 그건 저였습니다 🤕
이렇게 빡센 복습 & 포스팅은 오랜만이네요 😂
혹시라도 설명이 잘못되거나 이해가 되지 않는 부분이 있다면 댓글 부탁드리겠습니다~!!
참고 자료: 밑바닥부터 시작하는 딥러닝 1
'딥러닝' 카테고리의 다른 글
주로 분류를 위해 사용되는 함수인 softmax는 딥러닝에서 가장 많이 쓰이는 녀석 중 하나일 겁니다.
이번에 '밑바닥부터 시작하는 딥러닝 1,2권'을 구현하면서 정말 여러 번 코드를 치면서 구현했었는데, 코드의 원리가 생각보다는 이해하기 쉽지 않았던 것 같습니다 🤔
함수 자체는 엄청 간단한데 의외로 역전파 원리는 그렇지 않습니다.
오늘은 이를 코드와 함께 꼼꼼히 살펴보면서 어떻게 구현이 되어있는지, 특히 미분이 왜 이렇게 되는 건지 알아보겠습니다!!
1. softmax 함수 정의하기
우선 총 n개의 클래스가 존재한다는 상황을 가정하겠습니다.
그리고 앞으로 이 함수의 입력은 벡터 a, 출력은 벡터 y, 정답은 벡터 t라고 하겠습니다.
따라서 각 벡터는 n개의 원소로 구성되어 있으므로 a = [a1, a2, ... an], y = [y1, y2, ..., yn], t = [t1, t2, ..., tn]이 됩니다.
함수를 식으로 적으면 다음과 같습니다.
i의 값을 1에서부터 n으로 바꿔가면서 y1, y2, ... , yn을 구해보면 우리는 이 출력의 총합이 1이 될 것임을 알 수 있습니다.
분모는 전부 동일할 것이고 분자의 변수는 a1, a2, ..., an이 될테니 분모와 분자가 같아지게 되겠죠.
이를 softmax라는 이름의 함수로 정의하면 다음과 같습니다.
import numpy as np
def softmax(a):
y = np.exp(a) / np.sum(np.exp(a))
return y
그리고 이를 실행해보면 다음과 같은 결과를 얻을 수 있습니다.
a = np.array([1,2,3,4])
print(softmax(a)) # array([0.0320586 , 0.08714432, 0.23688282, 0.64391426])당연한 이야기지만 softmax(a)의 총합은 1입니다.
2. softmax 함수 변형하기
아주 간단한 위 함수 구현은 향후 overflow 문제를 일으킬 수 있습니다 👿
지수 함수의 특성상 변수에 오는 값이 커지면 그 결과값이 너무 가파르게 커지기 때문이죠.
따라서 정확한 값을 출력하지 못할 가능성이 큽니다.
그래서 이번에는 softmax에 아주 간단한 트릭을 적용해서 출력 결과는 동일하면서도 overflow를 방지해보겠습니다.
식은 다음과 같습니다.
맨 윗줄에 c는 0이 아닌 상수입니다.
분수에서 분자와 분모에 동일한 숫자를 곱해도 값의 변화가 없다는 것은 다들 잘 아시겠죠?? 🤧
그럼 이번에는 주어진 상수 c를 지수 형태로 변경해봅니다.
이는 간단한 지수의 밑변환 공식을 적용한 것입니다.
(참고 블로그 링크: https://color-change.tistory.com/29#google_vignette)
두 번째 줄에서는 지수 법칙에 의해 밑을 e로 삼는 두 항의 지수가 덧셈으로 표현이 됩니다.
(분모도 마찬가지입니다. 시그마는 덧셈이므로 모든 항에 곱셈을 추가해야 하죠)
따라서 분모와 분자에 상수 c를 모두 곱해주면, 결과적으로 지수에 밑을 e로 삼는 log(c)를 더해주는 꼴이 됩니다.
(너무 허졉하지만...) 로그의 그래프는 위와 같은 꼴이죠.
즉, 정의역은 x > 0 이고 공역은 실수 전체입니다.
따라서 '밑을 e로 삼는 log(c)'는 '어떤 실수값이든지 될 수 있다!'는 결론에 이르게 됩니다.
쉽게 말하면 기존 입력 a를 구성하는 모든 원소에 대해 동일한 값을 더하거나 빼더라도 (실수는 음수도 가능하니까요) 그 결과는 처음과 동일하다는 것이죠!! 😲
따라서 우리는 overflow 현상을 방지하기 위해 기존 입력 벡터 a의 모든 원소에서 벡터 a의 최댓값을 빼주도록 하겠습니다.
코드 구현은 다음과 같습니다.
def softmax(a):
a = a - a.max()
y = np.exp(a) / np.sum(np.exp(a))
return y
코드로는 너무나도 간단해서 당황스럽지만(?), 이렇게나 쉽게 구현됩니다.
3. softmax 함수에 미니배치 추가하기 (1)
다음은 미니배치 추가입니다.
지금까지 코드들은 전부 딱 한 개의 샘플에 대해서만 동작하는 코드입니다.
예를 들어 n차원으로 구성된 입력 벡터가 두 개인 경우, 입력 차원은 (2, n)이 되므로 이전 코드로는 처리가 어렵습니다.
구체적으로는 다음과 같습니다.
a = np.array([[1,2,3,4],
[5,6,7,8]])
print(np.max(a)) # 8
print(a - np.max(a)) # [[-7 -6 -5 -4]
# [-3 -2 -1 0]]
numpy.max 함수는 전체 배열의 최댓값을 반환하므로 우리가 원하는 결과를 얻을 수 없게 되죠 🥲
(각 샘플에 대해서는 각 샘플의 최댓값을 빼야겠죠?)
따라서 우리는 각 샘플마다의 최댓값을 뺄 수 있도록 axis 개념을 잘 활용해야 합니다!
두 가지 정도의 방식을 살펴볼테니 차근차근 따라가 봅시다.
첫 번째 방식입니다.
def softmax_1(a):
# a: (b, n)
if a.ndim == 2:
# a.max(axis=1, keepdims=True): (b, 1)
a = a - a.max(axis=1, keepdims=True)
a = np.exp(a)
# np.sum(a, axis=1, keepdims=True): (b, 1)
y = a / np.sum(a, axis=1, keepdims=True)
elif a.ndim == 1:
# 이전 구현과 동일
a = a - np.max(a)
y = np.exp(a) / np.sum(np.exp(a))
return y
a_1 = np.array([1,2,3,4])
a_2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,13]])
print("ndim:1")
print(softmax_1(a_1))
print("\nndim:2")
print(softmax_1(a_2))
# ndim:1
# [0.0320586 0.08714432 0.23688282 0.64391426]
# ndim:2
# [[0.0320586 0.08714432 0.23688282 0.64391426]
# [0.0320586 0.08714432 0.23688282 0.64391426]
# [0.01521943 0.0413707 0.11245721 0.83095266]]
여기서 b는 batch를, ndim은 해당 array의 차원수를 뜻합니다.
'ndim == 2' 조건은 입력이 batch 단위로 주어졌다는 것을 의미하게 됩니다.
따라서 이때는 'axis = 1', 즉 열을 기준으로 최댓값을 구해 각 행에 대해 빼줍니다.
😳..
아마 축 개념이 익숙치 않은 경우 여기서 조금 헷갈리실텐데, 배열의 차원수를 천천히 생각해 봅시다.
a는 현재 (b, n) 차원입니다.
이때 앞에서부터 축의 번호를 매기므로, axis = 0 = b, axis = 1 = n이 됩니다.
따라서 n차원 중에서 가장 큰 값을 골라야 하는 것입니다. (이 행위를 b번 반복하게 됨)
우리가 사용한 예시인 a_2의 첫 행을 보면 [1,2,3,4]입니다. 이것이 n = 4 차원일 때의 예시이므로 여기에서의 최댓값 4를 찾습니다.
다음으로 두 번째 행은 [5,6,7,8] 이므로 최댓값 8을, 마지막 세 번째 행에서는 최댓값 13을 추출합니다.
그런데 keepdims=True 옵션으로 인해 기존의 차원수(ndim==2)가 유지되어야 합니다.
따라서 a.max(axis=1, keepdims=True)의 결과는 위 예시에서 [[4], [8], [13]]이 되고 차원은 (3, 1)이 됩니다.
그런데 a의 형상은 (3, 4)이므로 여기서 (3, 1) 차원의 벡터를 빼주면 브로드 캐스팅이 일어납니다.
즉, (3,1) 차원의 벡터가 (3,4)차원으로 복사되어 뺄셈을 수행하게 되죠.
다시 말하자면 [[4], [8], [13]] -> [[4,4,4,4], [8,8,8,8], [13,13,13,13]] 이 됩니다.
이 값을 지수 함수의 변수로 던져주면 됩니다.
하나 더 주의할 것은 np.sum 함수를 적용할 때도 'axis=1' 이어야 한다는 점입니다.
각 샘플 케이스를 나타내는 행(axis=0)이 아니라 클래스의 개수를 나타내는 차원(n)에 대한 sum을 해줘야 된다는 뜻이죠.
추가로 ndim:2 의 결과를 좀 더 자세히 보시면 재밌는 것을 알 수 있습니다.
첫 번째 행의 결과값과 두 번째 행의 결과값이 완전히 동일합니다!!
이는 위에서 언급한 '입력 벡터의 모든 원소에 동일한 값을 더하거나 빼더라도 함수값은 동일하다'는 내용과 완전히 일치하는 결과입니다 😄
(ndim == 1인 경우는 이전과 동일하므로 설명을 생략합니다)
4. softmax 함수에 미니배치 추가하기 (2)
조금 다른 방식으로 배치를 처리해도 동일한 결과를 얻을 수 있습니다.
코드부터 살펴보도록 하죠.
def softmax_2(a):
# a: (b, n)
if a.ndim == 2:
a = a.T # (a.T): (n, b)
a = a - a.max(axis=0) # a.max(axis=0): (b,)
y = np.exp(a) / np.sum(np.exp(a), axis=0) # np.sum(np.exp(a), axis=0): (b,)
return y.T # (n, b) -> (b, n)
elif a.ndim == 1:
# 이전 구현과 동일
a = a - np.max(a)
y = np.exp(a) / np.sum(np.exp(a))
return y
a_1 = np.array([1,2,3,4])
a_2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,13]])
print("ndim:1")
print(softmax_2(a_1))
print("\nndim:2")
print(softmax_2(a_2))
# ndim:1
# [0.0320586 0.08714432 0.23688282 0.64391426]
# ndim:2
# [[0.0320586 0.08714432 0.23688282 0.64391426]
# [0.0320586 0.08714432 0.23688282 0.64391426]
# [0.01521943 0.0413707 0.11245721 0.83095266]]
이번에도 'ndim == 2' 조건만을 살펴보도록 하겠습니다.
a.T에 사용된 '.T'는 transpose를 의미하는데 여기서는 단순하게 행과 열을 뒤바꾸었다고 생각할 수 있습니다.
그래서 a_2를 입력으로 주었을 때 출력을 살펴보면 다음과 같습니다.
array([[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11],
[ 4, 8, 13]])
기존에 한 행 내에서 펼쳐져 있던 [1,2,3,4]가 여러 행에 걸쳐 내려온 것을 알 수 있습니다.
이제 행 단위가 아니라 '열 단위'로 하나의 샘플을 의미하게 되었다는 것이죠.
그래서 이번에 overflow 방지 대책으로 최댓값을 빼줄 때는 한 행 내의 최댓값이 아니라 한 열 내의 최댓값을 구해주어야 합니다.
즉, (n, b) 차원에서 n개 값들 중에 가장 큰 것을 구해야 하므로 a.max(axis=0)이 되는 것이죠.
이를 구해서 뺄셈을 수행하면(a - a.max(axis=0)) 결과는 다음과 같습니다.
array([[-3, -3, -4],
[-2, -2, -3],
[-1, -1, -2],
[ 0, 0, 0]])각 열의 최댓값 4, 8, 13을 각 열별로 빼준 것을 알 수 있습니다.
이때도 이전과 마찬가지로 브로드캐스팅이 일어난 것이죠.
이제 열에 포함된 각 원소를 입력값으로 갖는 소프프맥스 스코어를 구해야 합니다.
분모에는 열에 포함된 원소를 모두 더한 값이 들어가야겠죠?
그래서 마찬가지로 axis=0인 sum 연산을 수행해주면 됩니다.
즉, [-3, -2, -1, 0] (세로로 훑어서 구한 값)을 모두 더한 -6, 같은 방식으로 구한 -6, -9가 sum 연산을 통해 획득됩니다.
그리고 이것은 (n, b) 차원의 행렬을 (b) 차원으로 바꾸게 되죠.
(axis에 해당하는 축이 사라집니다)
분자인 np.exp(a)는 전치된 a를 입력으로 받아 여전히 (n, b) 차원입니다.
따라서 분모에 (b) 차원이 오게 되면 분모가 브로드 캐스팅될 것임을 알 수 있습니다.
y의 출력은 다음과 같습니다.
[[0.0320586 0.0320586 0.01521943]
[0.08714432 0.08714432 0.0413707 ]
[0.23688282 0.23688282 0.11245721]
[0.64391426 0.64391426 0.83095266]]
이제 y를 반환해야 하는데, 우리가 원하는 y의 차원은 (b, n)입니다.
즉, 행과 열이 전치된 상황이므로 이를 원래대로 되돌려 놓아야 합니다.
따라서 return y.T 를 해주면 됩니다.
transpose를 통해 차원수를 유지하면서도 연산을 잘 수행했으나 직관성이 떨어지는 것 같아 이전의 구현 코드보다 더 선호되기는 어렵다는 생각이 드네요!
5. Softmax 클래스 구현하기
지금까지는 softmax 함수를 구현했습니다.
이번에는 이 함수를 활용하는 클래스를 구현해보려고 해요.
왜 클래스를 사용해야 할까요?
답변은 아주 간단합니다.
이를 '계층(layer)'으로 사용하기 위해서죠.
어떤 벡터를 확률값으로 변환해주는 softmax까지 도달하기 이전의 상황을 상상해보세요.
맨 처음의 입력을 가중치와 곱하고 편향을 더해주고 활성화 함수를 거치고 등등..
우리는 이러한 과정을 각각 하나의 계층으로 만들어 줬습니다.
중요한 것은 통일된 클래스 형식을 따라가는 것입니다.
동일한 인스턴스 변수와 메서드를 사용하는 것이죠.
즉, 어떤 계층이든지 간에 params, grads 변수를 init에서 초기화 해주어야 하고, forward / backward 메서드를 포함해야 하죠.
이렇게 해야지만 나중에 연쇄적으로 forward / backward를 수행하기가 편해지기 때문입니다!
Softmax 클래스
각설하고, Softmax 계층을 클래스로 구현하되, 여기서는 forward 까지만 다루겠습니다.
class Softmax:
def __init__(self):
self.params, grads = [], []
self.out = None
def forward(self, a):
out = softmax(a)
self.out = out
return self.out
def backward(self, dout):
# dout = (∂L/∂y)
da = self.out * dout
sumda = np.sum(da, axis=1, keepdims=True)
da -= self.out * sumda
return da
각 요소를 하나씩 살펴봅시다.
1) __init__
각 계층에 포함된 파라미터와 미분계수가 저장될 공간을 만들어줘야 합니다.
지금 당장에는 사용되지 않지만 전체 학습을 돌리는 코드에서 활용되는 변수들입니다.
또한 self.out 변수를 미리 선언해줌으로써 이 계층의 최종 출력을 알립니다.
2) forward
입력 벡터 a에 대해 softmax 함수를 적용합니다.
단, 미니 배치 단위로 입력이 들어올 수 있다는 점에 유의합니다. (2차원 배열)
위에서 코드를 구현할 때 이미 배치 처리까지 완료했습니다.
3) backward 🔥🔥🔥
저는 이 구현을 이해하는데 엄청나게 많은 시간을 쏟았습니다.
softmax가 cross entropy와 같은 손실 함수와 결합되면 미분이 너무 간단한데 단독으로 쓰이는 상황을 이해하는게 굉~장히 어렵습니다.
(저만 그럴 수도 있지만..)
그래서 내용을 완전히 뜯어보려고 합니다.
우선 softmax 함수의 미분 계수를 식으로, 그리고 그래프로 구해보겠습니다.
3-1) softmax 미분 계수 그래프로 구하기
맨 처음 가정했던 것을 그래프로 표현하면 위와 같습니다.
입력 벡터 a, 출력 벡터 y, 타겟 벡터 t 인 것이죠.
이에 대해 t와 y 사이의 손실을 계산하고 편미분을 통한 역전파를 수행하면 아래와 같은 그림이 됩니다.
Loss를 y에 대해 각각 편미분하고, y를 a에 대해 각각 편미분한 것을 곱해주는 양상입니다.
이렇게만 보면 너무 간단한데, 사실 softmax는 이러한 구조가 아닙니다.
각 입력이 다른 출력에 영향을 주는 구조로 표현해야 softmax에 대한 올바른 도식이라고 볼 수 있을 것입니다.
여기서 잘 생각해볼 것은 하나의 노드(예를 들어 a1)가 여러 개의 출력을 만들어 내기 위해 '복사'되고 있다는 점입니다.
이를 (밑시딥 구현 공부를 해보셨으면 알겠지만) repeat 계층으로 생각할 수도 있겠죠.
즉, 이에 대한 미분은 각 출력으로부터 얻은 미분 계수의 합이 된다는 것입니다.
역전파를 시각화하면 다음과 같습니다.
(a1 하나에 대해서만 표현해보겠습니다)
a1 노드에 세 개의 미분 계수가 흘러 들어오는 것을 볼 수 있습니다.
그래서 세 개의 미분 계수를 합해준 것이 손실 L에 대한 a1의 미분 계수가 됩니다.
이처럼 소프트맥스는 하나의 노드가 다른 출력에도 영향을 주는 구조이기 때문에 미분을 식으로 표현해도 조금 독특하게 표현됩니다.
3-2) softmax 미분 계수 식으로 구하기
softmax 함수를 미분할 때, 크게 i = j인 경우와 그렇지 않은 경우로 나눕니다.
소프트맥스 함수의 결과값을 생각해보면 이를 편미분 한다는 것 자체가, 하나의 출력 결과에 대한 여러 입력의 영향력을 각각 파악하겠다는 뜻입니다.
따라서 하나의 출력(i)에 대해 여러 개의 입력(j)이 주어지므로 j 번 편미분 해야 하는 것입니다.
결국 주어진 y_{i}를 a_{j}에 대해 편미분 하는데 총 j번 인 것이고, 이때 한 번은 i = j가 되겠죠.
위에 식이 전개되는 과정을 살펴보면 가장 먼저 알아야 하는 것은 몫의 미분법입니다.
(분수 형태로 표현된 함수를 미분하는 방법으로, 기억이 나지 않는 분들은 링크를 참고해보세요)
규칙에 따라 분모는 제곱이 되고, 분자는 각각 미분을 적용한 것의 차로 구할 수가 있게 됩니다.
식을 잘 정리하면 처음 y_{i}로 정의한 것을 바탕으로 식을 깔끔하게 정리할 수가 있게 되죠.
i != j 일 때가 조금 헷갈릴 수 있는데, 이때는 y_{i}를 a_{j}에 대해 편미분한 것입니다.
따라서 분자의 경우 a_{j} 항을 포함하고 있지 않으므로 미분 결과가 0이 등장하게 된 것입니다.
시그마의 경우 합연산이므로 그 중에 a_{j} 가 포함된 항에 대한 미분 결과만 살아남은 것으로 이해할 수 있습니다.
(지수 함수의 미분이 이해되지 않는 분은 링크를 참고해보세요)
이제 그래프와 식을 종합해보면 하나의 노드(예를 들어 a1)에 대한 여러 미분 계수(class 개수가 되겠죠)를 누적합해줘야 한다는 것을 이해할 수 있을 것입니다.
그런데 아무리봐도 코드와 잘 매칭이 되지 않습니다.
backward 코드를 다시 살펴보죠.
def backward(self, dout):
# dout = (∂L/∂y)
da = self.out * dout
sumda = np.sum(da, axis=1, keepdims=True)
da -= self.out * sumda
return da
시작부터 이상합니다.
대체 출력 y와 미분 계수 ∂L/∂y를 왜 곱하고 시작할까요..?
그리고 이걸 갑자기 합치고는 출력과 다시 곱하고.. 이것의 의미가 뭘까요?
예시 하나를 바탕으로 위 코드의 실행 과정을 살펴보겠습니다.
우선 첫 행의 da = self.out * dout 입니다.
기존의 출력 y에 이전 층에서 흘러 들어온 미분 계수가 각각 곱해진 것을 알 수 있습니다.
이는 원래 역전파 과정에서 이전 계층의 미분 계수를 곱하는 것이기 때문에 너무 당연한 이야기입니다.
하지만 소프트맥스는 하나의 입력 노드가 여러 출력에 영향을 주기 때문에 다른 출력에 대한 미분 계수는 아직 반영되지 않은 상태입니다.
즉, a1을 기준으로 한다면 y1에 대한 미분 계수는 처리했지만 y2, y3에 대한 것은 적용하지 않은 상태죠.
그래서 모든 미분 계수를 하나로 합칩니다.
sumda = np.sum(da, axis=1, keepdims=True)
우리는 i = j 가 아닌 경우에 대한 케이스에 대해서는 미분 계수가 -y_{i} * y_{j}로 구해진다는 것을 위에서 확인했습니다.
각 케이스를 더해야 하므로 시그마 연산이라 생각하고 sum을 미리 취해주면 그 결과가 동일해질 수 있겠죠.
이를 표현한 것이 마지막 행의 '-self.out * sumda' 입니다.
즉, 각 미분계수를 합한 것을 기존의 출력과 곱해서 빼주게 되면, '-y_{i} * y_{j}' 연산에 시그마를 취한 것이 되죠.
하지만 문제가 하나 있습니다.
바로 이 시그마 연산에 i = j 인 케이스가 포함된다는 것입니다.
그래서 이를 시그마에서 분리하여 i = j 인 항끼리 모으고 나머지를 따로 둡니다.
이 과정이 그림에서 빨간색으로 표시된 부분입니다.
이를 통해 i = j 일 때와 그렇지 않을 때의 적절한 미분 계수에 이전 계층에서 흘러들어온 미분 계수가 곱해지고 있다는 것을 알 수가 있습니다.
그래서 이 방식을 간단히 요약하면
1) i = j 인 케이스의 미분 계수를 구하는 것처럼 기존 출력 y와 이전 계층에서 흘러 들어온 미분 계수를 곱한다. 이때 y(1-y)에서 -y 에 대해서는 아직 연산하지 않은 상태이다.
2) 미분 계수를 모두 합쳐서 i != j 인 경우의 미분 계수를 구할 준비를 한다. sum 연산이 시그마를 의미하는 것으로 볼 수 있다.
3) 두 연산을 결합하고 i = j 인 경우와 그렇지 않은 경우로 식을 정리한다.
가 됩니다.
사실 세 줄짜리 코드를 이렇게까지 봐야하나..? 싶기도 하지만..
개인적으로는 엄청나게 구현이 신기하게 되어있다는 생각에 뜯어보다가 위 내용들을 다루게 되었네요.
6. Softmax with Cross Entropy
잘 아시다시피 분류를 위한 softmax 연산은 cross entropy와 자주 함께 쓰입니다.
물론 논리적으로 타당하기 때문인 것도 그 이유이지만, 연산의 효율성 그리고 직관성때문이라는 것도 둘을 짝꿍처럼 붙여놓는 핵심적인 이유가 됩니다.
우선 Cross Entropy를 밑시딥 교재에 나온 것처럼 그래프 형태로 forward / backward를 표현해보겠습니다.
입력 y1에 로그를 취하고, 이를 t1과 곱한 것을 다른 항들과 모두 더하고, 여기에 -1을 곱하면 L 식이 구현됩니다.
이제 역전파를 진행할 건데, 처음 자기 자신에 대한 미분 계수는 1로 시작됩니다.
여기에서의 핵심은 각 연산마다 어떻게 미분 계수를 구하냐겠죠.
곱셈 연산은 다른 입력을 곱해서 전달하면 됩니다.
예를 들어 y = a * b 라고 한다면 y에 대한 a 미분 계수는 b, b 미분 계수는 a가 될 것입니다.
서로 반대 변수를 취해 전달하는 것이죠.
그래서 처음에는 1이 -1로 바뀝니다.
덧셈 연산은 그대로 전달하는 것 뿐입니다.
정확히는 덧셈을 수행한 것만틈 복사해서 다시 뿌려주는 거죠.
그래서 전달된 -1이 세 갈래로 뻗어나가게 됩니다.
그리고 다시 곱셈 연산을 만납니다.
위에서와 마찬가지로 반대편의 항을 곱해서 전달하면 됩니다.
따라서 -1에 반대편 항인 t1, t2, t3를 각각 곱한 -t1, -t2, -t3가 전달됩니다.
마지막은 로그입니다.
y = log x 의 경우 미분을 취하면 1 / x가 됩니다.
(기억이 안 나는 경우 링크 참고!)
따라서 전해져 내려온 미분 계수에 입력값의 역수를 취해 곱해줍니다.
즉, -t1, -t2, -t3에 각각 1/y1, 1/y2, 1/y3을 곱하면 됩니다.
이 최종 결과가 softmax 계층에 전달되는 dout이 됩니다!!
이어서 softmax의 순전파를 다시 살펴볼텐데 이번엔 자세한 설명을 생략하겠습니다.
아까는 굉장히 단순하게 표현된 것을 식에 맞게끔 풀어 표현한 그림입니다.
입력에 exp를 취하고 그 값들을 전부 더하여 분모로 취함과 동시에 그 값을 각각 분자로 취한 것이 y1, y2, y3가 되죠.
이때 exp 값들을 합쳐서 S로 칭하겠습니다.
위에서 구한 cross entropy의 미분 계수를 그대로 가져다 쓰면서 역전파를 수행하겠습니다.
천천히 살펴보도록 하겠습니다.
우선 처음 만나는 곱셈 연산입니다.
곱셈은 반대편의 입력을 곱해서 가져간다고 했죠.
그래서 이전에서 흘러내려온 -t1/y1에 exp(a1)을 곱해서 위로 올려보냅니다.
반대로 exp(a1)에는 1/s을 곱해서 보내주고요.
이때 S는 exp(a1) + exp(a2) + exp(a3)로 정의되어 있기 때문에 이를 적절히 활용하여 가장 간단한 형태로 만들어줍니다.
결과적으로 나눗셈 방향으로 올라가는 것은 -t1*S, exp(a1)으로 흘러가는 것은 -t1/exp(a1)이 됩니다.
다음은 나눗셈 연산이 갈라져있다는 것에 주목합시다.
이는 S를 복사(repeat)하여 다른 연산을 수행한 것이므로, 역전파 시에는 미분 계수를 누적합해야 합니다.
따라서 -t1*S + (-t2*S) + (-t3*S)를 계산해줍니다.
동시에 나눗셈 연산의 미분이 어떻게 되는지도 생각해보세요.
y = 1/x를 미분하면 -1/x^2가 됩니다.
(1/x = x^(-1) 이기 때문에 이를 미분하면 되죠)
따라서 미분 계수를 누적합한 -t1*S + (-t2*S) + (-t3*S)에 -1/S^2을 곱해줍니다.
결과적으로는 아주 간단하게 1/S이 되는 것을 알 수 있습니다.
(이 과정은 보라색으로 표현되어 있습니다)
덧셈 노드는 미분 계수를 그대로 흘려보낸다고 했으니 1/S이 그대로 전달됩니다.
이제 마지막 exp 노드입니다.
exp는 미분을 수행하면 자기 자신이 반환됩니다.
따라서 exp(a1)이 반환되고 이를 1/S과 곱해줍니다.
또한 exp 노드도 갈라져 있기 때문에(repeat) 이를 -t1/exp(a1) 과도 곱합니다.
두 곱셈 결과를 더해주면 y1-t1 으로 정리할 수 있습니다.
(보라색으로 표현되어 있습니다)
동일한 과정을 a2, a3에 대해서도 수행해주면 softmax + cross entropy의 역전파 결과가 (y - t)로 일반화된다는 것을 알 수 있습니다 😲😲😲
Cross Entropy
이제 softmax를 cross entropy와 묶어서 사용하는 이유가 납득이 되네요!!
좋습니다. 그럼 이제 마지막으로 코드를 구현해보도록 하죠.
def cross_entropy_error(y, t):
if y.ndim == 1: # 1차원인 경우 배치 처리할 때와 동일하게 2차원으로 맞춰주기
y = y.reshpae(1, y.size)
t = t.reshape(1, t.size)
if t.size == y.size: # 원 핫 벡터를 레이블 인덱스로 변환하기
t = t.argmax(axis=1)
batch_size = y.shape[0] # 샘플 개수로 나눠 평균 취하기
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
우선 cross entropy 함수 구현입니다.
분류 문제에서의 타겟은 주로 단 한 개의 값만 1이고 나머지는 0인 원핫 벡터로 주어집니다.
예를 들어 3개를 분류하는 상황이라면, [1, 0, 0], [0, 1, 0], [0, 0, 1] 셋 중 하나가 타겟이 될 수 있죠.
하지만 우리는 보다 효율적으로 코드를 작성하기 위해 이를 [0], [1], [2]로 바꿔줄 것입니다.
(마지막 return 부분에 열에 대한 인덱스가 됨)
t.size == y.size는 벡터 t가 원핫 벡터 형태라는 것을 의미하므로 레이블 인덱스로 바꿔주게 되는 것입니다.
return 부분은 조금 까다로운데 'y[np.arange(batch_size), t]' 에만 집중해보세요.
array y의 형상은 (batch, class) 입니다.
예를 들어 두 개의 샘플을 세 개 카테고리로 분류한다면 (2, 3)이 되겠네요.
이때 정답 레이블은 각 샘플별로 0과 1이라고 가정하겠습니다.
y = np.array([[0.1, 0.2, 0.7],
[0.2, 0.3, 0.5]])
batch_size = y.shape[0]
print(f"batch size: {batch_size}") # 2
t = np.array([[1, 0, 0],
[0, 1, 0]])
t = t.argmax(axis=1)
print(f"t: {t}") # [0 1]
print(f"y[np.arange(batch_size), t]: {y[np.arange(batch_size), t]}") # [0.1 0.3]
이 예시를 보면 y의 각 샘플에 'np.arange(batch_size)'를 이용하여 행으로 접근하고, 레이블 인덱스 t를 이용해 원하는 열에 접근하는 것을 알 수 있습니다.
이에 따라 정답에 해당하는 0.1과 0.3을 각 샘플별로 추출할 수 있게 된 것입니다.
이런 식으로 코드를 짜는 이유는 살펴본 것처럼 t가 주로 원핫 벡터이기 때문입니다.
일반적인 분류에서는 정답이 하나이므로 다른 케이스, 즉 t=0인 케이스는 손실값에 포함되지 않습니다.
원래 수식을 생각해보시면 t * np.log(y) 라는 것을 알 수 있고, 이때 t=0이면 결과값이 0이 되기 때문입니다.
Softmax + Cross Entropy
이제 이 cross_entropy_error를 활용한 최종 클래스를 살펴보겠습니다.
class SoftmaxWithLoss:
def __init__(self):
self.params, grads = [], []
self.y = None # 소프트맥스 출력값
self.t = None # 정답 레이블 인덱스
def forward(self, x, t):
self.t = t
self.y = softmax(x)
if self.t.size == self.y.size: # 원핫 벡터인 경우 레이블 인덱스로 변환
self.t = self.t.argmax(axis=1)
loss = cross_entropy_error(self.y, self.t)
return loss
def backward(self, dout=1):
batch_size = self.t.shape[0] # 샘플 개수 체크
dx = self.y.copy() # 입력을 복사
dx[np.arange(batch_size), self.t] -= 1 # 정답 인덱스에 접근하여 -1
dx *= dout # 이전 계층 미분 계수 곱해주기
dx = dx / batch_size # 샘플 개수로 나눠 평균 취하기
return dx
1) __init__
모든 클래스들은 params, grads 변수를 담을 공간이 필요합니다.
그리고 소프트맥스 함수의 출력값과 레이블 인덱스를 담을 변수를 할당해줍니다.
2) forward
소프트맥스 함수에 넣을 x, 그리고 레이블 t를 입력으로 받습니다.
cross_entropy_error에도 원핫 인덱스 처리를 해주긴 하지만 한 번 더..? 점검하고 들어갑니다.
우리가 클래스 인스턴스를 생성해 얻고 싶은 것은 softmax를 통해 얻은 결과를 타겟과 비교해 얻은 손실(loss)값입니다.
따라서 이를 return 해주면 됩니다.
3) backward
여기서 주의할 점은 self.y를 copy한다는 것입니다.
미분 계수를 구해야 하는데 기존 출력값을 변경하면 안되기 때문에 새로운 주소를 할당하며 값만 복사하는 것이죠.
다음은 cross_entropy_error를 구현할 때와 비슷합니다.
np.arange(batch_size)를 통해 행에 접근하고, self.t를 통해 열에 접근하게 되는 것이죠.
그런데 왜 1을 빼줄까요?
softmax with cross entropy의 미분 계수를 다시 떠올려 봅시다.
'y - t', 아주 심플하게 정리되었죠.
그런데 타겟인 t는 어차피 1 또는 0입니다.
물론 이를 전부 레이블 인덱스로 바꿔주었기 때문에 실제로 t는 그냥 전부 1입니다.
따라서 'y - t'는 'y - 1'이 됩니다.
이를 아주 간단히 인덱싱해서 처리한 코드가 'dx[np.arange(batch_size), self.t] -= 1'입니다.
이제 이전 계층에서 전해져 온 미분 계수(dout)를 곱해주면 됩니다.
(y - t) * dout 연산을 해야 되니까 괄호 안쪽부터 순서대로 계산한 것으로 이해할 수 있습니다.
이를 샘플 개수만큼 나눠주면 되겠죠.
softmax 단독으로 쓰일 때 backward를 이해했던 것에 비하면 구현을 이해하기가 훨씬 쉽죠 :)
이상으로 softmax 함수, Softmax 클래스, cross_entropy_error, SoftmaxWithLoss 클래스 구현에 대해 알아보았습니다.
개인적으로는 softmax 함수가 이렇게까지 어려울 일인가 했는데 많은 걸 배우게 됐네요..
별 거 아닌 녀석이라고 생각했는데 그건 저였습니다 🤕
이렇게 빡센 복습 & 포스팅은 오랜만이네요 😂
혹시라도 설명이 잘못되거나 이해가 되지 않는 부분이 있다면 댓글 부탁드리겠습니다~!!
참고 자료: 밑바닥부터 시작하는 딥러닝 1