관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[McGill University, University of Toronto, Mila, Google Research]
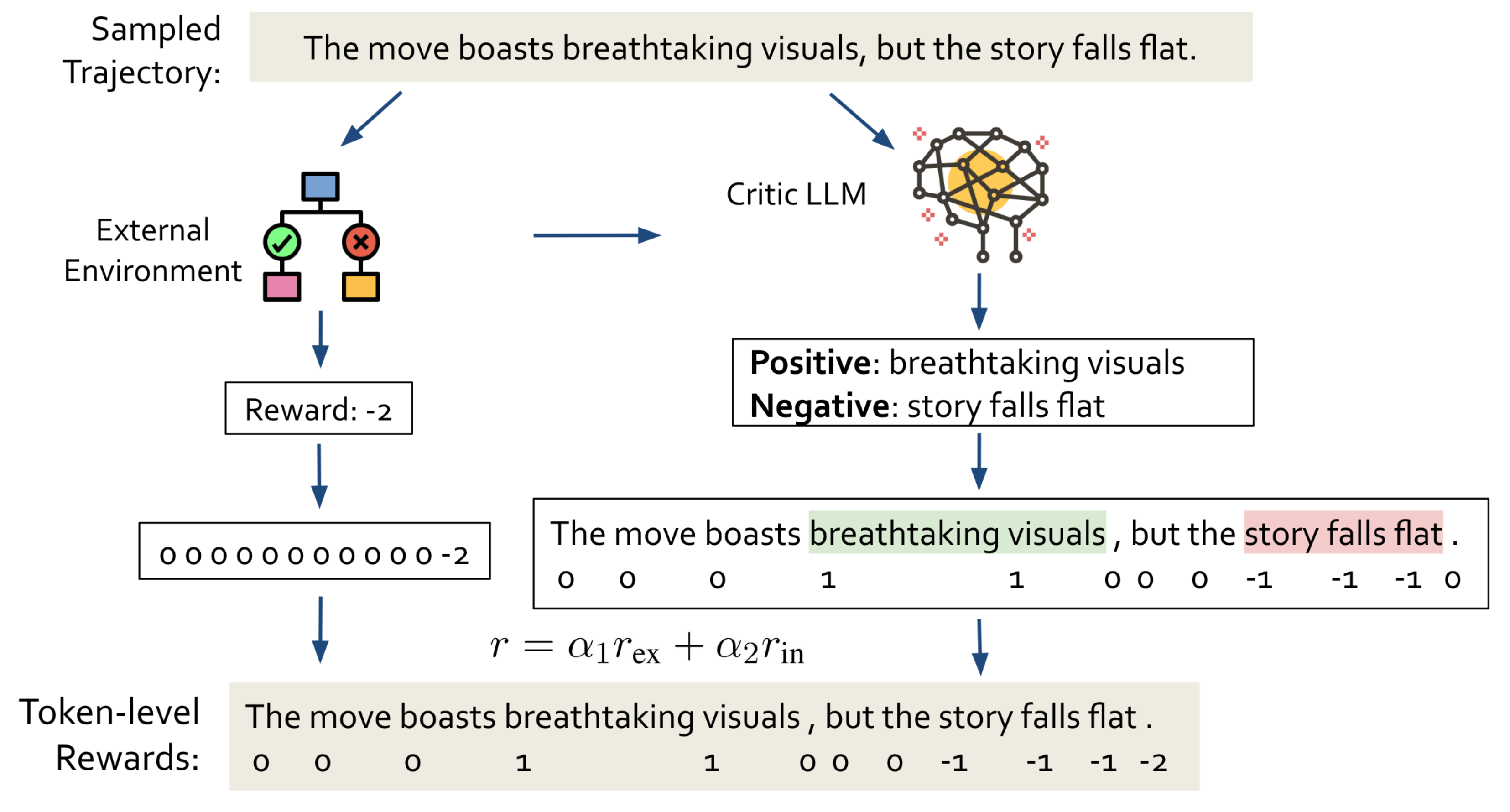
- LLMs의 비판 능력을 활용하여 RL 학습 동안 intermediate-step rewards를 생성할 수 있도록 하는 프레임워크, RELC를 제안
- poicy model과 critic language model을 결합하는 method
- critic language model로부터의 feedback은 token 또는 span 단위의 rewards로 전달됨
출처 : https://arxiv.org/abs/2401.07382
1. Introduction
언어 모델 사람의 선호에 보다 align 될 수 있도록 하기 위해 Reinforcement Learning을 활용하기 시작했고, 그 결과가 아주 뛰어나 이제는 거의 필수적인 것으로 인식되고 있습니다.
이때 미분 불가능한 reward signal에 대해 최적화되는 과정을 겪게 됩니다.
하지만 본 논문에서는 이러한 reward signal가 sparse한 특성을 지닌다는 것을 한계로 지적합니다.
즉, 모델이 생성하는 output은 sequence인데, 이것에 대하여 굉장히 뭉뚱그려진 reward를 반환하게 된다는 것이죠.
예를 들어 sequence 내의 특정 부분에 대해서는 만족하지만, 나머지 부분에 대해서는 만족스럽지 않은 결과라고 인식을 할 수도 있는 것인데, 이것을 통째로 좋다 or 나쁘다로 구분하는 것이 문제라고 지적한 것입니다.
따라서 이를 해결하기 위한 방법으로 토큰별, 혹은 구간별 reward를 구하여 이를 기존의 reward와 가중합하는 방식을 제안합니다.
기존에 external environment로부터 획득할 수 있었던 reward를 extrinsic reward, critic language model을 통해 획득하는 reward를 intrinsic reward라고 표현합니다.
2. Related Work
- RL for Text Generation
- Reward Shaping and Intrinsic Rewards
- LLM for Reward Design
3. Method
논문에서 제시하는 방법론의 가장 주된 목표는 intrinsic rewards와 extrinsic rewards의 적절한 조합에 최적화 하는 것입니다.
3.1. RL for Text Generation
여기서는 RL의 기본 개념을 설명하고 있습니다.
언어 모델의 생성 절차를 MDP (Markov Decision Process)로 간주한다면 다음과 같은 요소들을 고려할 수 있습니다.
$$(S, A, P, R, \gamma)$$
$S$는 가능한 모든 상태의 조합을, $A$는 행동의 집합을 의미합니다.
$P: S \times A \times S \mapsto [0,1]$는 상태 변화 함수를 의미하고, $R: S \times A \times S \mapsto \mathbb{R}$는 각 변화 $(s, a, s^{'})$에 할당되는 숫자값을 의미합니다.
이때 $\gamma \in [0,1]$은 discount factor가 됩니다.
언어 모델의 관점에서 생각해보면 input prompt는 $s_{0} \in S$가 되어 시작 상태가 됩니다.
그리고 각 decoding step $t$에 대해 state $s_{t} \in S$는 prompt와 이전에 생성된 토큰의 concatenation입니다.
새로이 생성되는 토큰을 append하는 과정을 반복하게 되고, 토큰을 생성할 때는 agent's policy $\pi_{\theta}(a|s)$를 따릅니다.
agent의 목표는 생성 과정 동안의 cumulative reward를 최대화하는 것이고 이는 $J(\theta)=\mathbb{E}_{\tau\sim \pi_{\theta}}[\sum_{t=0}^{T}\gamma^{t}r_t]$로 표현됩니다.
3.2. Policy Gradient based RL & PPO
최근까지 언어 생성 모델 학습에 가장 활발히 사용되었던 policy gradient methods에 대해 설명하는 부분입니다.
policy 모델의 parameters $\theta$를 최대화하는 직전의 수식을 따릅니다.
논문에서는 과거 연구들에서 제시되었던 이에 대한 gradient 수식을 설명하고 있는데 본 논문의 주된 내용은 아니라서 생략하겠습니다.
다만 Proximal Policy Optimization (PPO)에서는 각 스텝에서의 policy 업데이트를 제한하도록 식을 구성했고, 본 연구에서는 clipped surrogate objective function을 사용하는데 수식은 다음과 같습니다.
$$L(\theta)=\hat{\mathbb{E}}[\mathrm{min}(r_t(\theta)\hat{A}_t, \mathrm{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)]$$
여기서 $r_t(\theta)=\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t|s_t)}$이며 현재 policy를 따르는 state가 주어졌을 때 action $a_t$ 확률을 이전의 것으로 나누는 식이 됩니다.
3.3. Learning with LLM Generated Intrinsic Rewards
environment가 생성된 텍스트 전체를 입력으로 받아 scalar score로 반환하던 것을 extrinsic reward $r^{\mathrm{ex}}$라고 표현하며 이는 $r_{t<T}^{\mathrm{ex}}=0$입니다.
이와 달리 LLM으로부터 생성되는 추가적인 reward를 intrinsic reward라고 부르며 $r^{\mathrm{in}}$으로 표시합니다.
이때 사용되는 LLM을 critic model이라고 부릅니다.
critic model이 하는 일은 policy가 생성한 output의 token 또는 segment을 정확히 지적하는 것입니다.
이 모델에는 task description $D$, few-shot 예시 $E$, 현재 상태 $s$, 그리고 선택적으로 $r^{mathrm{ex}}$가 주어집니다.
각 스텝 $t$에 대해서 특정 토큰이 pinpointed된 segment의 일부인 경우 0이 아닌 값을 intrinsic reward $r^{\mathrm{in}}_t$으로 부여합니다.
최종 reward는 $r(s,a)=\alpha_1r^{\mathrm{ex}(s,a)} + \alpha_2r^{\mathrm{in}(s,a)}$가 됩니다.
따라서 policy LM은 다음 식을 최대화하는 방향으로 최적화됩니다.
$$J(\theta)^{\mathrm{RELC}}=\mathbb{E}_{\tau\sim \pi_{\theta}}[\sum_{t=0}^{T}\gamma^{t}(\alpha_1r^{\mathrm{ex}} + \alpha_2r^{\mathrm{in}})]$$
3.4. LLM Choice and Prompt Design
critic 모델로는 gpt-3.5-turbo와 7B Llama2를 사용했다고 합니다.
실험에 관한 구체적인 내용은 다음 파트에서 다루겠습니다.
입력 프롬프트의 경우 세 항목으로 구성했다고 밝혔습니다.
(1) 프롬프트 내에 태스크를 정의합니다.
즉, critic 모델이 확인해야 하는 정확한 response와 error의 종류에 대해 구체적으로 밝힙니다.
(2) 엄선된 few-shot 예시를 포함합니다.
특별한 언급이 없다면 3개의 예시를 사용했다고 합니다.
예시들은 다양한 response를 이끌어 낼 수 있는 내용과 policy model이 주로 만들어내는 전형적인 오류를 다루고 있습니다.
(3) critic 모델에게 현재 질문과 policy 모델로부터의 output을 제공합니다.
environment가 반환한 extrinsic reward는 선택적으로 제공한다고 합니다.
appendix에 구체적인 프롬프트가 나와있는데 너무 길어서 본 포스팅에 포함하지는 않겠습니다.
궁금하신 분들은 논문의 appendix를 직접 참고해보시길 바랍니다.
4. Experiments
본 연구에서는 sentiment control, LM detoxification, text summarization, 세 개의 태스크로 RELC의 성능을 베이스라인과 비교 평가합니다.
단, policy 모델과 critic 모델의 사이즈를 구분하여 비교한 내용이 포함되어 있습니다.
첫 번째 환경은 작은 policy 모델(GPT-2 large)이 큰 critic 모델 (gpt-3.5-turbo)와 함께 쓰이는 상황입니다.
나머지 두 번째 환경은 policy 모델과 critic 모델이 7B Llama2 모델로 동일한 상황입니다.
4.1. Sentiment Control
- Dataset
- 25K 개의 영화 리뷰로 구성된 IMDB 데이터셋을 학습용으로 사용했습니다. 각 리뷰로부터 4~10개의 토큰을 추출하여 입력 프롬프트로 제공했다고 합니다.
- OpenWebText (OWT) Corpus 데이터셋을 이용하여 성능을 평가했다고 합니다. neurtral (5K), positive (2.5K), negative (2.5K), 세 개의 테스트셋으로 구분했다고 합니다.
- Reward Model
- dsitilled BERT classifier 모델을 IMBDB 데이터셋에 학습시켰습니다.
- Baselines and evaluation metrics
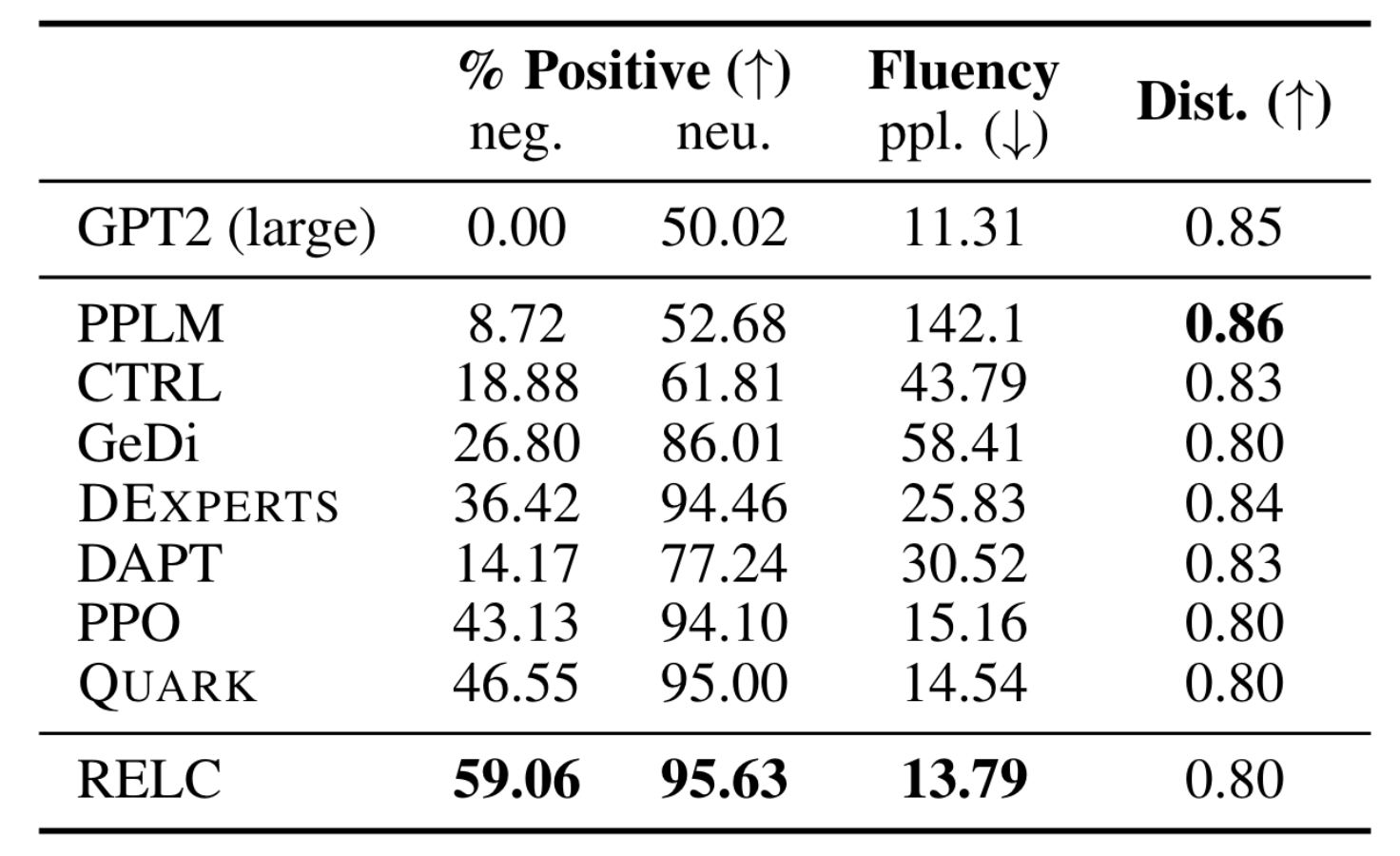
- 7개의 method를 베이스라인으로 사용합니다: PPLM, CTRL, DAPT, GeDi, DExperts, Rect, PPO
- 25개의 생성된 출력으로부터 긍정/부정 continuation의 평균 비율을 구합니다. 이때 SST-2에 fine-tuning된 sentiment analysis classifer를 사용합니다.
- 또한 GPT-2 XL perplexity를 fluency의 proxy로 사용합니다.
- Results
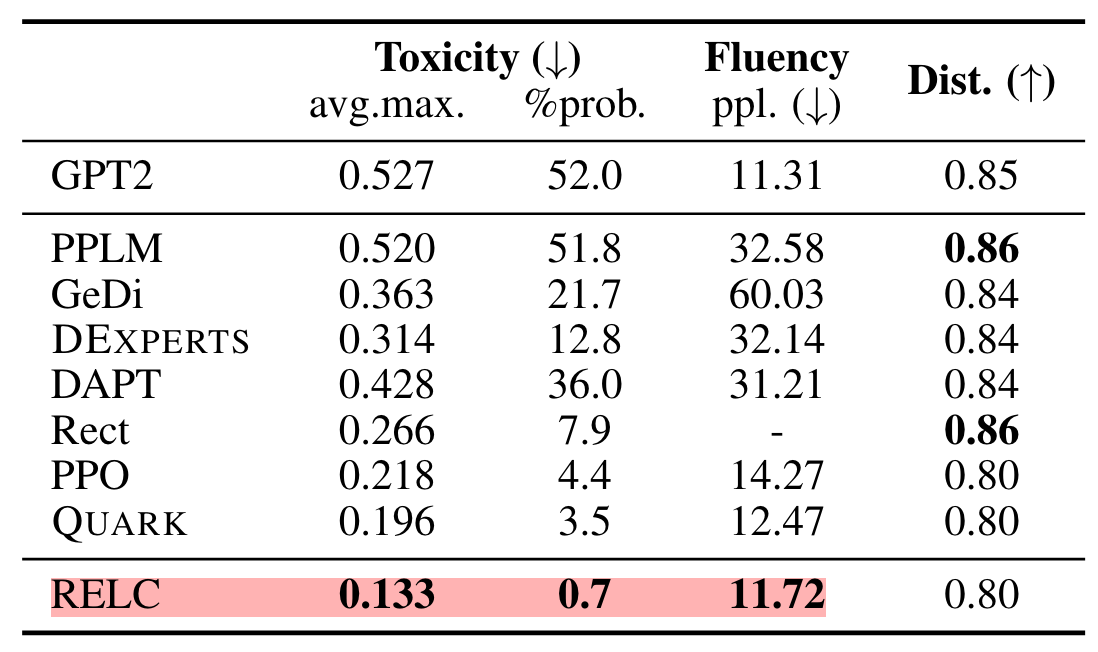
4.2. LM Detoxification
- Benchmark
- RealToxicityPrompts (RTP) 데이터셋을 train & evaluation에 사용했습니다.
- 평가를 위해서 Perspective API를 사용하는데 0부터 1까지의 스코어를 반환한다고 합니다. (높을수록 toxic)
- 85K 개의 prompt를 학습용으로, 10K 개를 non-toxic test prompt로 사용합니다.
- Baslines and evaluation metrics
- 마찬가지로 7개의 baseline을 사용합니다.
- 생성된 25개의 출력에 대한 최대 toxicity score의 평균으로 평가합니다.
- 또한 해당 출력이 생성될 때 toxic continuation의 empirical probability를 평가 기준으로 삼습니다.
- Results

4.3. Summarization
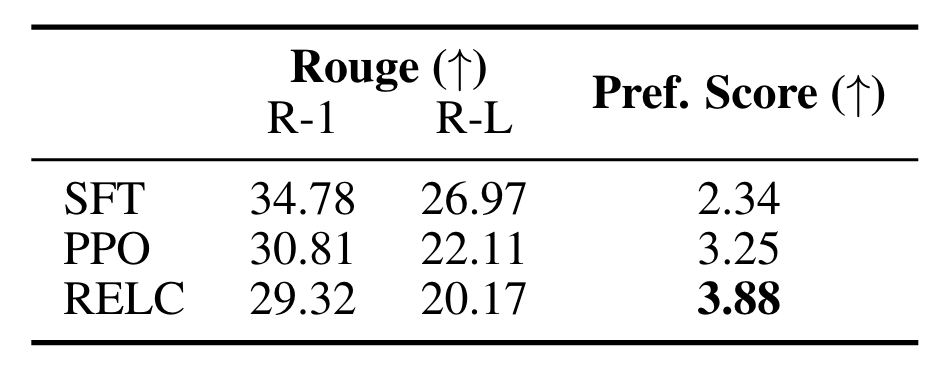
- Dataset
- Reddit TL;DR 데이터셋을 사용합니다. 약 3M 개의 post가 포함되어 있습니다.
- 이중에서 116K 개를 학습용으로, 6K 개를 validation & test용으로 사용합니다.
- Baselines and evaluation metrics
- 두 개의 baseline method와 비교합니다: Supervised fine-tuning (SFT), PPO
- ROUGE score와 reward model을 이용하여 획득한 preference score를 사용합니다.
- Results
4.4. Analysis
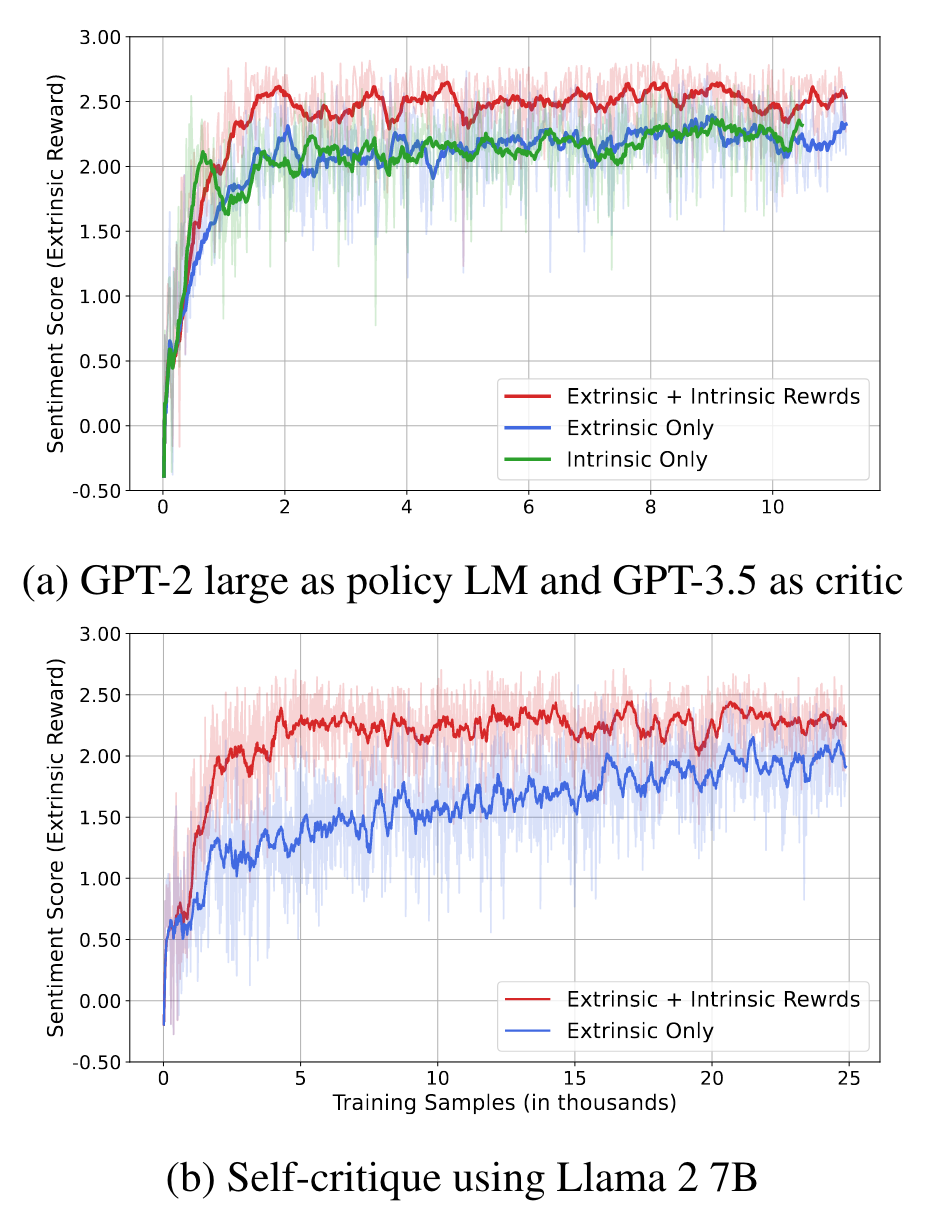
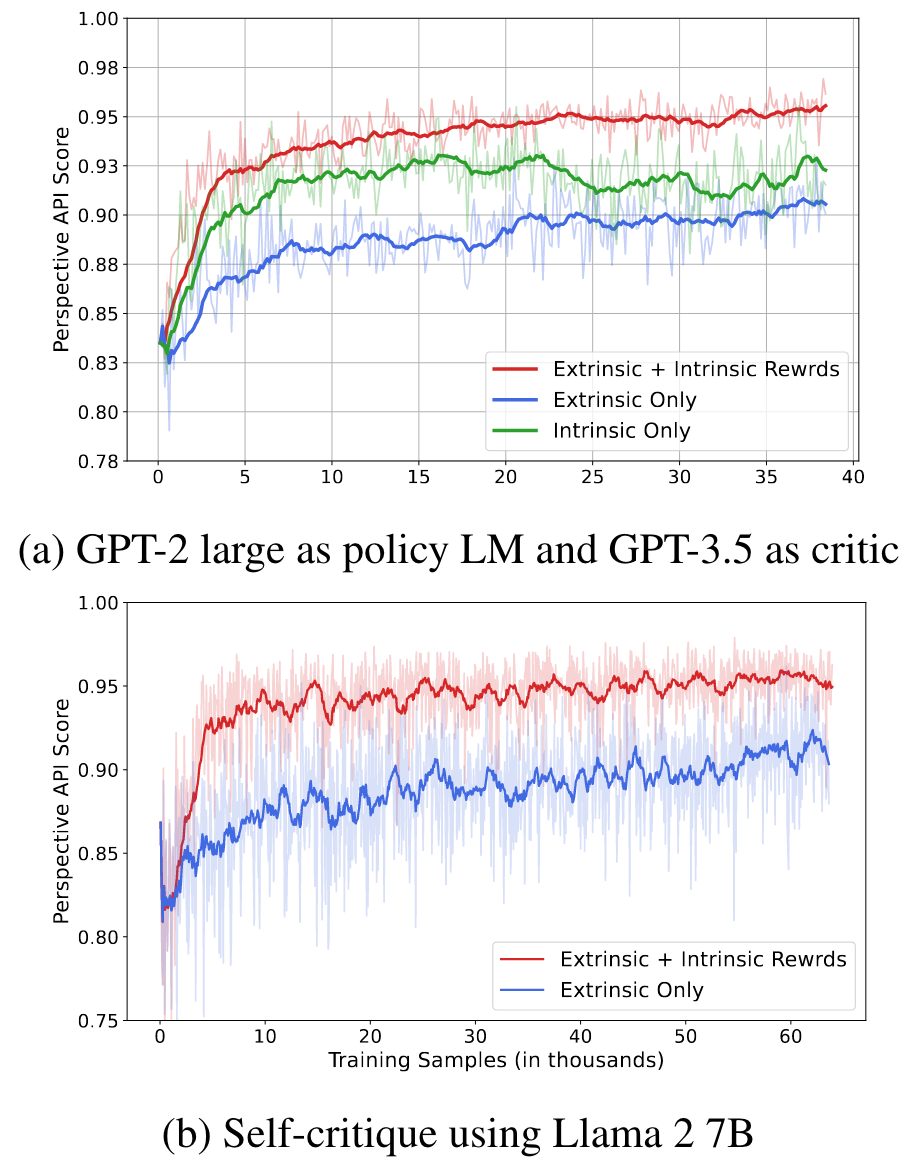
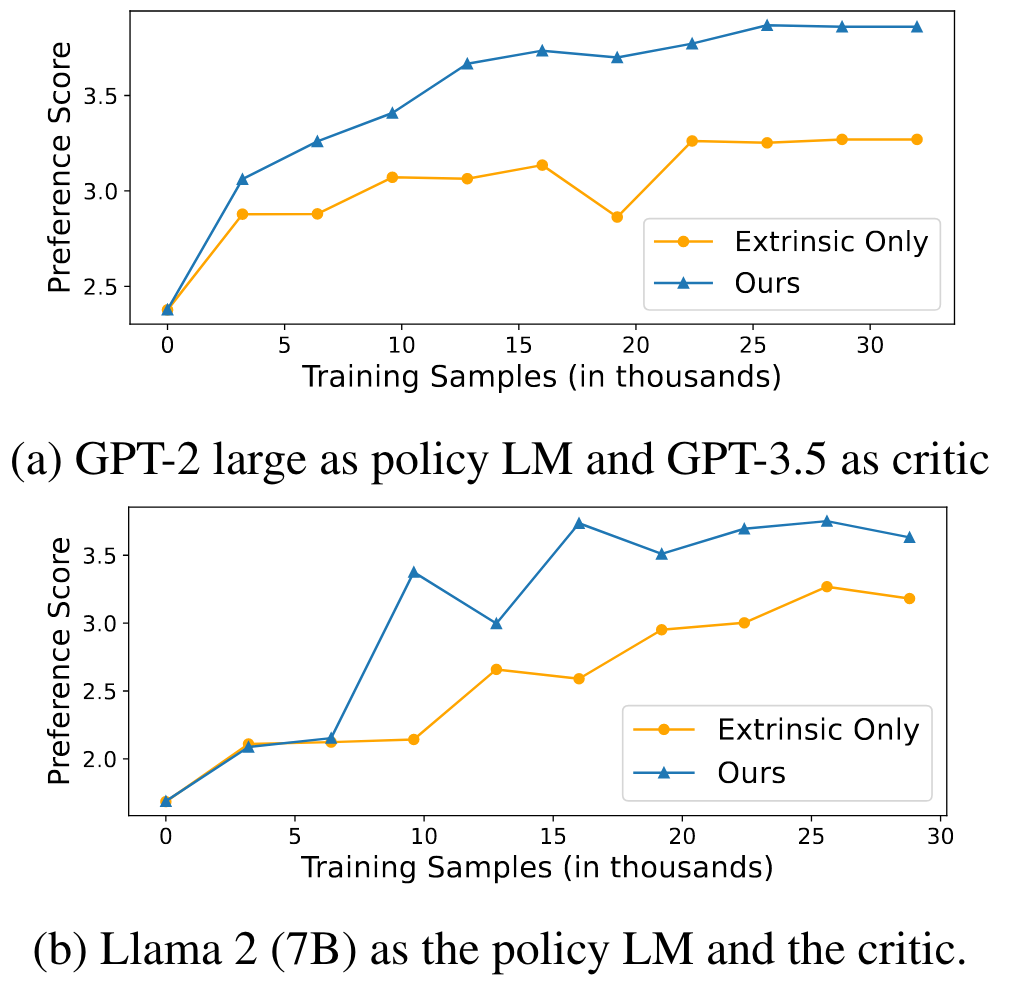
Intrinsic Rewards, 즉 critic language model이 토큰, segment 단위로 반환하는 reward가 실제로 유효한 것인지 확인하기 위해, 이를 랜덤하게 초기화한 값으로 전달하는 실험을 수행하고 본인들의 것과 결과를 비교했습니다.
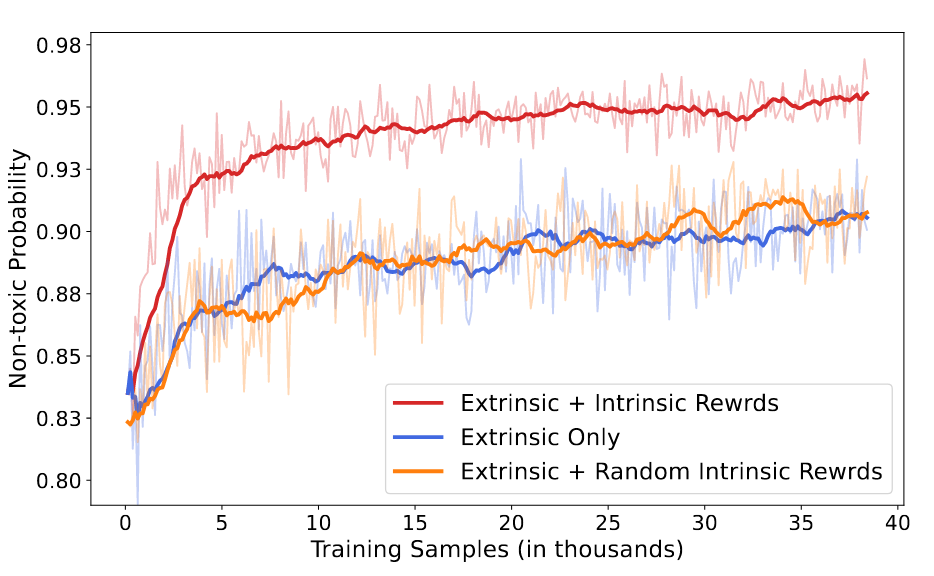
그래프를 보시면 기존의 environment가 reward를 제공하는 extrinsic only 방식과 random intrinsic rewards를 합친 것의 차이가 없다는 것을 알 수 있습니다.
따라서 critic model이 상황에 따라 적절한 reward를 제공하고 있다고 해석할 수 있습니다.
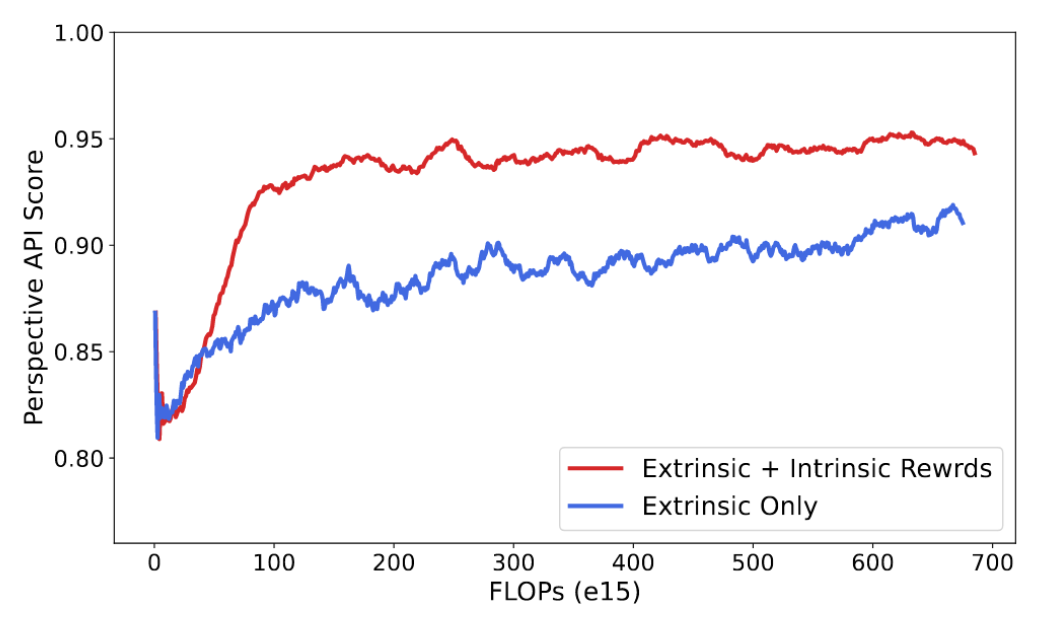
또한 Detoxification 태스크를 수행할 때 floating point operations (FLOPs)를 체크해본 결과, intrinsic rewards를 사용하게 되는 경우 그렇지 않을 때보다 동일 연산량 대비 performance가 뛰어나다는 것을 알 수 있습니다.
이는 intrinsic rewards를 extrinsic rewards와 함께 사용하는 본 논문의 방식이 자원 효율성이 좋은 것이라고 해석 가능합니다.