
-
1. Introduction
-
2. Related Works
-
3. Model Architecture
-
3.1. Residual block
-
3.2. MLP block
-
3.3. Temporal-mixing blocks
-
3.4. Real-Gated Linear Recurrent Unit (RG-LRU)
-
4. Recurrent Models Scale as Efficiently as Transformers
-
Scaling curves
-
5. Other Experiments & Results
-
5.1. Training Recurrent Models Efficiently on Device
-
5.2. Inference Speed
-
5.3. Long Context Modeling
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- RNN과 gated linear recurrence를 결합한 Hawk, gated linear recurrence와 local attention을 결합한 Griffin을 제안
- Hawk는 특정 태스크에서 Mamba 수준의 성능을, Griffin은 Llama-2 수준의 성능을 보임. 특히 후자의 경우 학습 당시에 접한 텍스트 보다 긴 데이터에 대해서도 뛰어난 성능을 보임.
- 두 모델은 Transformers 대비 hardward efficient하며 lower latency & higher throughput을 가짐
출처 : https://arxiv.org/abs/2402.19427
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recu
arxiv.org
1. Introduction
최근에 Mamba 모델이 크게 주목을 받으면서 Transformer architecture를 넘어서는 아키텍쳐가 존재할 수 있을가에 대한 관심이 뜨겁습니다.
원래는 RNN 계통의 모델들은 parallel 학습이 불가능하기 때문에 (sequential한 연산) transformer 아키텍쳐가 선호되었는데, 이제는 오히려 RNN 기반의 아키텍쳐를 사용하면 sequence의 길이를 늘릴 수 있고 연산 속도도 빨라 초당 생성 토큰이 많다는 것이 장점으로 알려지고 있습니다.
물론 현재까지는 transformer 기반의 LLM 대비 상대적으로 훨씬 작은 크기의 모델들만 제시되었고 (3B 이하), 또 그 열풍의 중심에 서있던 Mamba 논문이 ICLR 2024에서 reject 당하면서 앞으로 이 분야의 연구가 어떻게 흘러갈지 다시 또 전혀 알 수 없게 된 상황입니다.
2. Related Works
- State-space Models (SSMs)
- S4, S5, H3
- RetNet
- RWKV
- Mamba
- Flash Attention
3. Model Architecture
본 모델 아키텍쳐를 구성하는 것은 크게 세 가지 요소입니다.
(a) a residual block
(b) an MLP block
(c) a temporal-mixing block
이때 (c) a temporal-mixing block의 경우,
(1) global Multi-Query Attention (MQA)
(2) local (sliding-window) MQA
(3) recurrent block (논문에서 제시한 방법)
이렇게 세 개의 block을 사용하여 그 실험 결과를 비교했다고 합니다.
그럼 각 요소를 하나씩 살펴보도록 하겠습니다.
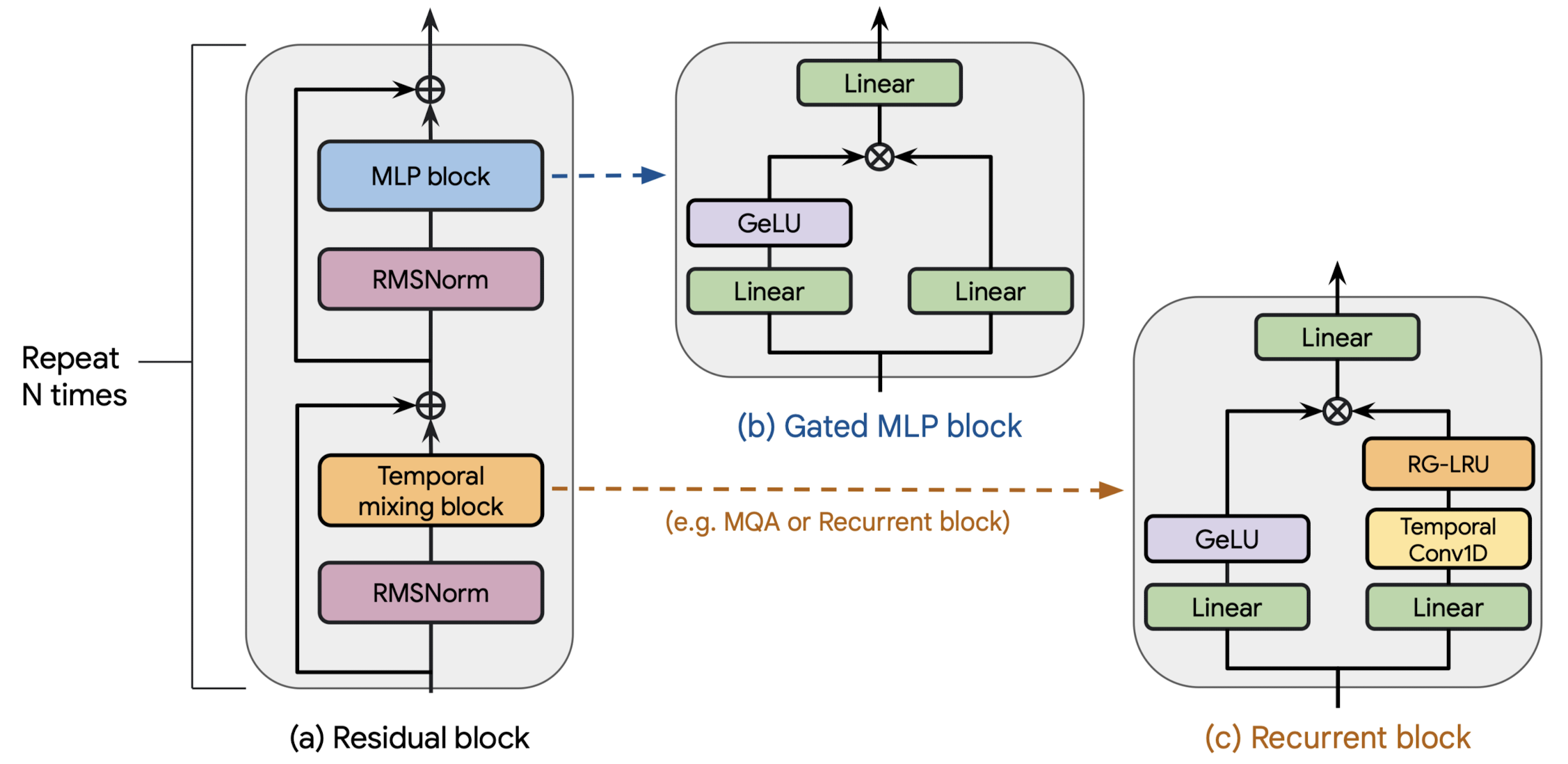
3.1. Residual block
residual block은 그림의 (a)에서 볼 수 있는 것처럼 두 개의 요소로 구성되어 있습니다.
첫 번째 요소는 hidden state $x$에 RMSNorm을 적용한 뒤 temporal-mixing block을 거치게 되어 있습니다.
그 결과는 skip connection을 통해 $x$와 합쳐지게 됩니다.
두 번째 역시 RMSNorm을 적용하는데, 이를 MLP block에 통과시킵니다.
마찬가지로 skip connection을 통해 RMSNorm에 들어갔던 입력과 합쳐줍니다.
3.2. MLP block
그림의 (b)와 같이 gated MLP block을 사용합니다.
이는 $D$ 차원을 갖는 input으로부터 두 개의 branch로 갈라지게 됩니다.
두 개의 branch에 속하는 linear layer들은 $MD$ 차원의 output을 갖게 되는데요, 이때 $M=3$으로 $M$은 expansion factor를 의미합니다.
두 branch로부터의 결과를 element-wise multiplication ($\odot$) 하기 전에 한 branch로부터의 결과는 GeLU 활섬화 함수를 적용합니다.
단, 마지막 layer에 해당하는 경우 $D$ 차원의 output dimension을 갖도록 했다고 합니다.
3.3. Temporal-mixing blocks
현재 그림 (c)에 나타난 것은 Recurrent block으로 본 연구에서 제시한 방법론입니다.
(1) Global multi-query attention (Transformer baseline)
기존 transformer architecture에서 사용하는 MHA (Multi-Head Attention) 대비 MQA 방식의 추론 효율이 좋다는 것은 잘 알려져 있습니다.
여기에서는 $D_{head}=128$로 고정하고 Rotary Position Embedding (RoPE)를 사용했다고 합니다.
(2) Local sliding window attention
기존의 global attention은 시퀀스 길이에 quadratic하게 비례하여 computational complexity가 상승한다는 문제점이 있습니다.
이를 해결하기 위한 방법으로, sliding window attention이라고도 잘 알려진 local attention 방식이 도입되었습니다.
(3) Recurrent block (paper's)
Gated MLP block에서처럼 입력을 두 개의 branch로 나눠서 처리합니다. (parallel)
한쪽에서는 separable Conv1D layer를 통과시키는데, 이는 H3 모델의 Shift-SSM에서 영감을 받은 것이라고 합니다.
이때의 temporal filter diemnsion은 4이므로 굉장히 적은 parameter를 취한다고 하네요.
그리고 이 layer를 통과시켜 얻은 결과를 RG-LRU로 보냅니다.
(RG-LRU에 대해서는 곧 다룹니다)
반대쪽에서는 linear layer를 통과시켜 얻은 결과에 GeLU 활성화 함수를 적용하고,
두 branch로부터 얻은 결과를 element-wise multiplication 합니다.
그럼 이제 마지막으로 (3) Recurrent block에 사용되는 Real-Gated Linear Recurrent Unit (RG-LRU)에 대해서 알아보겠습니다.
3.4. Real-Gated Linear Recurrent Unit (RG-LRU)
RG-LRU layer는 Linear Recurrent Unit (LRU)에서 영감을 받은 아키텍쳐라고 합니다.
(Resurrecting Recurrent Neural Networks for Long Sequences: https://arxiv.org/abs/2303.06349)
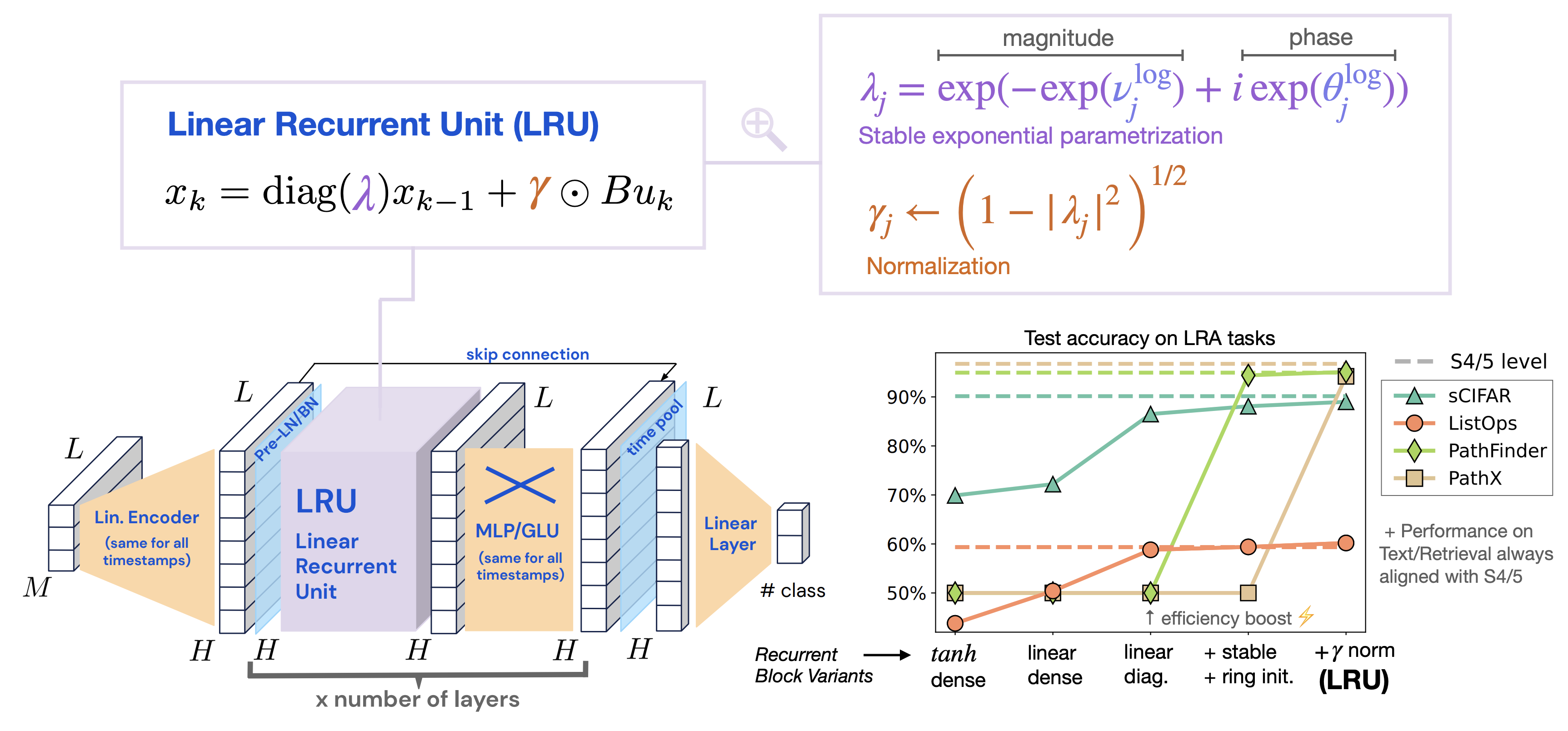
즉, LRU 아키텍쳐에 LSTM 또는 GRU와 같은 gating system을 결합한 것이라고 합니다.
본 논문에서는 다음과 같은 notation들을 이용하여 RG-LRU를 설명하고 있습니다.
$$r_{t}=\sigma(W_{a}x_{t}+b_{a}),$$
$$i_{t}=\sigma(W_{x}x_{t}+b_{x}),$$
$$a_{t}=a^{cr_{t}},$$
$$h_{t}=a_{t}\odot h_{t-1}+\sqrt{1-a_{t}^{2}}\odot (i_{t}\odot x_{t}),$$
특히 세 번째 식은 $a=\sigma(\Lambda)$ 로 계산하는데 $\Lambda$는 학습 가능한 파라미터라고 합니다.
자세한 식은 아래와 같습니다.
$$\mathrm{log}\,a_{t}=\mathrm{log}\,a^{cr_{t}}=\mathrm{log}\,\sigma(\Lambda)^{cr_{t}} = -c\,\mathrm{softplus}(\Lambda)\odot r_{t}$$
의미를 간단히만 정리해보겠습니다.
첫 번째, 두 번째 식은 각각 입력 $x_{t}$를 얼마만큼 recurrence할지, 그리고 input으로 받아들일지 결정하는 gate 역할을 수행합니다.
sigmoid를 활성화 함수로 사용하고 있다는 것은 $x_{t}$의 값을 0과 1 사이로 보내서, 0에 가까우면 사용하지 않을 것임을 1에 가까우면 거의 온전히 사용하겠다는 뜻을 갖게 됩니다.
세 번째 식은 계산 편의를 위해 log로 변환하여 계산한다고 합니다.
이때 $\Lambda$의 값을 잘 초기화하여 $a^{c}$의 값이 0.9에서 0.999의 초기화값을 가질 수 있도록 설계했다고 합니다.
$c$의 값은 상수 8로 고정했다고 밝혔습니다.
참고로 상세식에서 나타낸 softplus 함수의 경우 sigmoid의 적분 함수라고 합니다.
자세한 이해를 위해서는 LRU 논문의 수식들부터 먼저 잘 이해해야 할 것 같습니다.
마지막 네 번째 식을 보면 $a_{t}$를 가중치로 삼고 있는 것으로 이해할 수 있습니다.
이를 바탕으로 이전 hidden state인 $h_{t-1}$과 input gate를 통과한 입력 $i_{t}\odot x_{t}$를 가중합하는 것처럼 보입니다.
4. Recurrent Models Scale as Efficiently as Transformers
위에서 설명한 아키텍쳐를 바탕으로 수행한 실험 결과를 비교합니다.
사용된 베이스라인과 모델 설명을 간단히 하면 아래와 같습니다.
- MQA Transformer baseline
- residual pattern과 gated MLP를 사용한 베이스라인입니다. (1) MQA와 RoPE를 사용합니다.
- Hawk
- residual pattern과 gated MLP를 사용하되, MQA 대신 RG-LRU가 포함된 (3) recurrent block을 사용합니다.
- recurrent block의 폭을 대략 3/4 정도 확장했습니다. ($D_{RNN}\approx 4D/3$)
- Griffin
- MQA의 KV cache를 줄일 수 있는 local attention의 장점과 recurrent block의 장점을 아우르는 방식입니다.
- (3) recurrent block을 가진 residual block과 (2) local (MQA) attention block을 가진 residual block을 번갈아가면서 사용합니다.
Scaling curves
세 종류의 model families를 100M에서 7B parameters 사이즈로 학습하며 scaling합니다.
이때 Chinchilla scaling lwas를 따르며 MassiveText dataset을 사용했다고 합니다.
모델별 평가 결과를 나타낸 표는 다음과 같습니다.
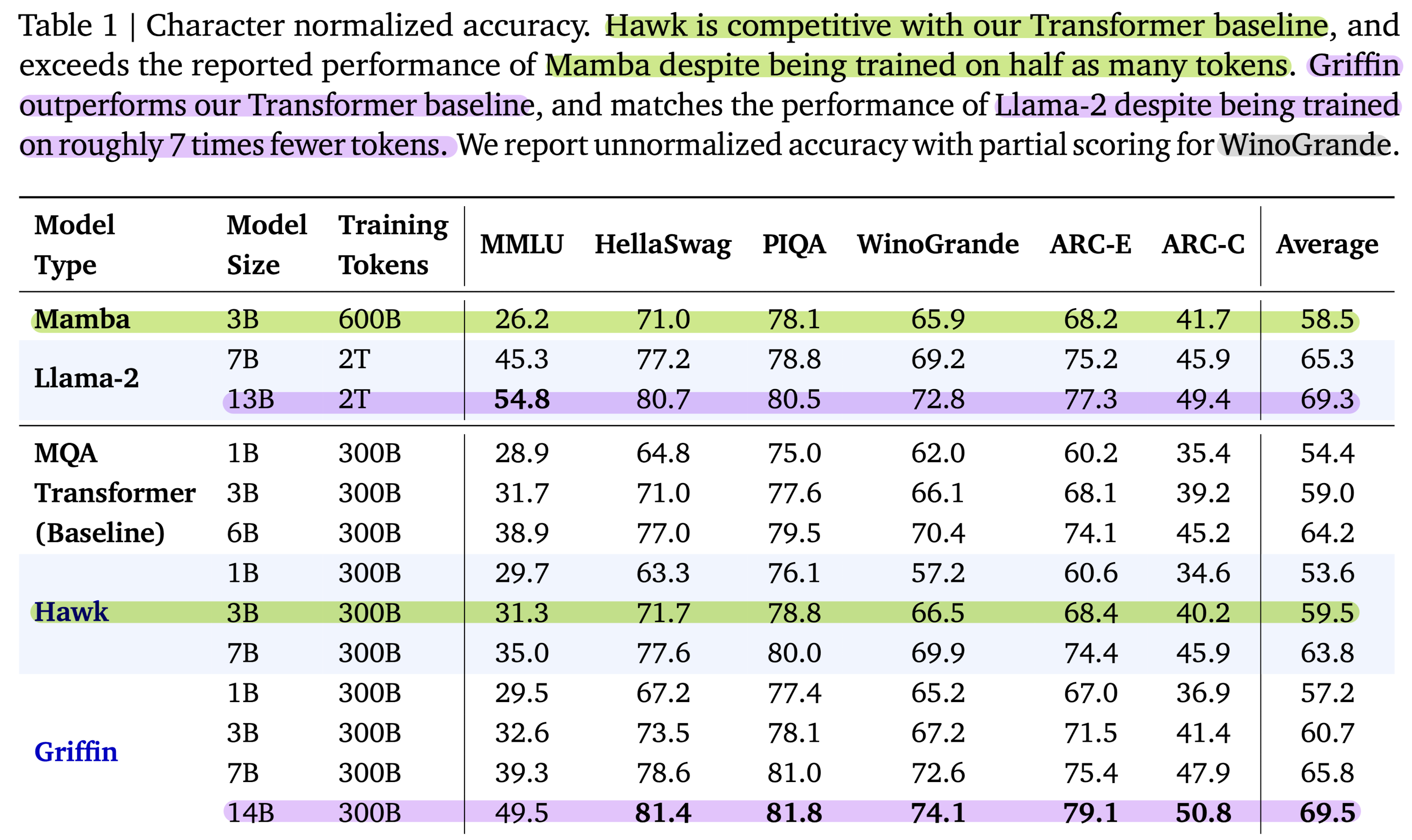
실험 관련된 디테일한 내용들은 논문을 직접 참고해보시길 권장드립니다.
다만, 표에 색으로 구분해둔 것처럼 Hawk 모델은 Mamba에 준하는, 그리고 Griffin 모델은 Llama-2에 준하는 성능을 보였다는 것을 알 수 있습니다.
단순히 성능이 괜찮았다는 것이 포인트가 아니라, 학습에 사용된 모델의 아키텍쳐가 다르고, 또 여기에 사용된 데이터셋의 크기가 훨씬 작다는 점이 주목할만한 점입니다.
5. Other Experiments & Results
5.1. Training Recurrent Models Efficiently on Device
이 파트에서는 large scale training을 위한 model parallelism에 대해 다루고 있습니다.
키워드 두 개만 적자면,
- Megatron-style sharding
- ZeRO parallelism
입니다.
또한 학습에 TPU-v3를 사용했으며, 연산상 문제를 해결하기 위해 linear scan이라는 방법론을 적용했다고 밝혔습니다.
한편 더 긴 길이의 시퀀스에 대해 학습하게 되는 경우 transformer의 학습은 느려질 수밖에 없으나 Griffin은 거의 동일하게 유지된다고 합니다.
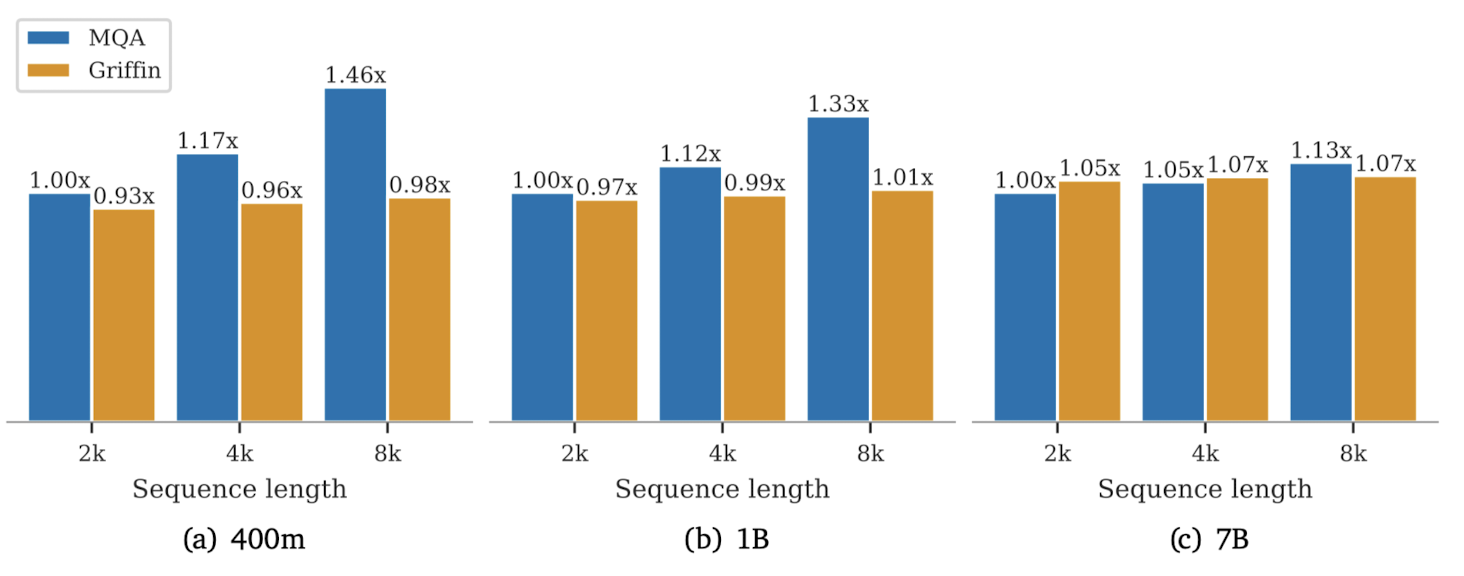
그러나 모델의 사이즈가 커질수록 여기에 포함되는 linear layer의 개수가 많아지고, 이로 인해 그 격차가 줄어들게 됩니다.
linear layer의 복잡도는 $O(TD^{2})$이고 global attention은 $O(T^{2}D)$, RG-LRU는 $O(TD)$입니다.
따라서 linear layer의 영향력이 커져 두 모델의 gap이 줄어든 것으로 이해할 수 있습니다.
5.2. Inference Speed
transformer 모델의 경우, 모델 자체의 파라미터와 KV 캐시로부터 대부분의 memory overhead가 발생합니다.
여기에 고려되는 배치 등의 요소를 나타내면 다음과 같습니다.
$$\mathrm{Time to sample next token}\approx \frac{\mathrm{param size + batch size} \times \mathrm{cache size}}{\mathrm{memory bandwidth}}$$
추론 속도를 평가하는 지표는 크게 두 가지로 latency와 throughput입니다.
latency가 특정 배치 사이즈에서 특정 개수의 토큰을 생성하는데 걸리는 시간이라면, throughput은 한 디바이스에서 1초에 생성할 수 있는 최대 토큰의 개수입니다.
당연하게도 latency를 줄이면 throughput을 늘릴 수 있는 관계입니다.
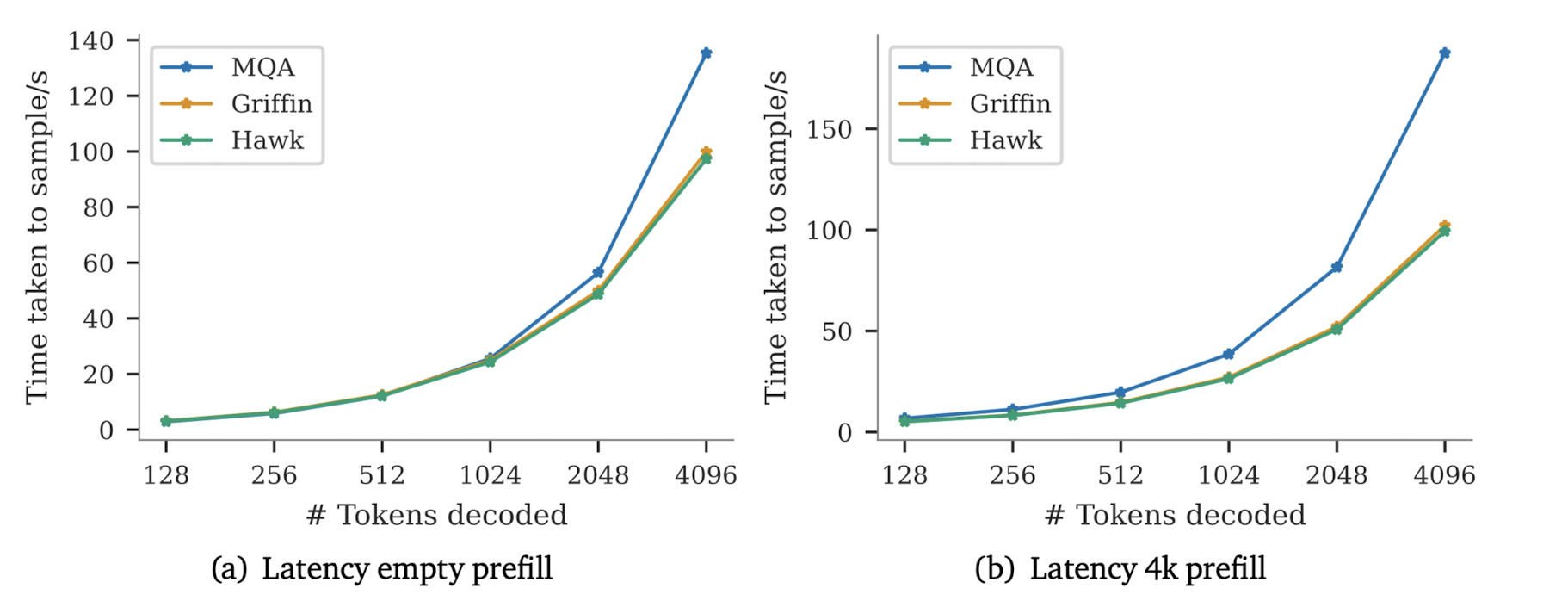
Hawk와 Griffin 모두 MQA 대비 더 낮은 latency를 갖는다는 것을 알 수 있습니다.
5.3. Long Context Modeling
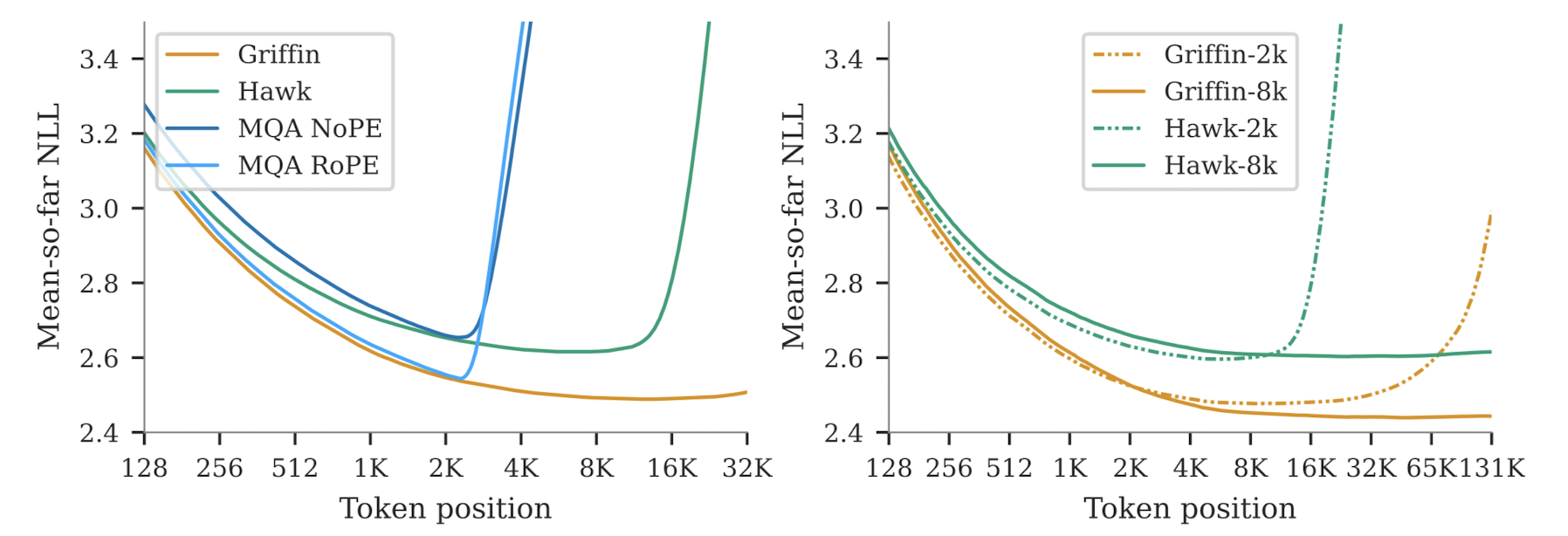
단순히 결과만 언급하자면, Griffin의 long context 상황에서 next token prediction 능력이 압도적으로 좋다는 것을 알 수 있습니다.
local attention layer와 RoPE를 같이 사용하는 Griffin이 뛰어난 결과를 보여주었습니다.
한편, context로부터 관련된 토큰이나 문서를 찾는 태스크, Copy and retrieval capabilites를 수행한 결과도 제시하고 있습니다.
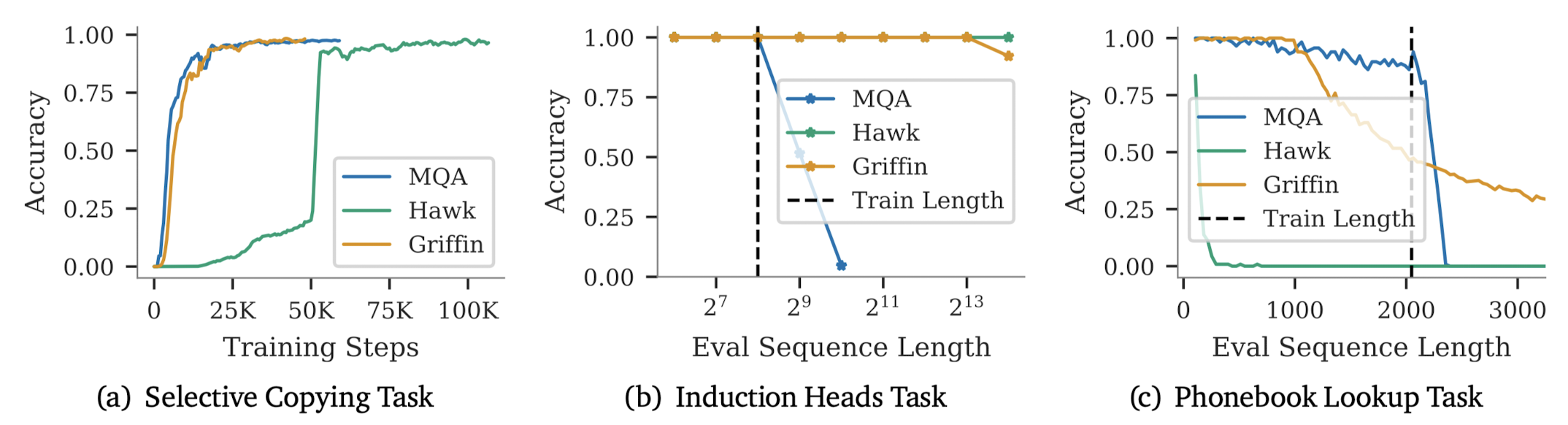
Hawk 모델이 Phonebook Lookup Task를 거의 수행하지 못한다는 점을 제외하면 나머지는 예상 가능했던 결과입니다.
이 태스크에서 특히 약세를 보이는 이유는 고정된 숫자의 state를 사용했기 때문이라고 합니다.
이와 달리 Griffin의 경우 동일 태스크에 대해서도 준수한 결과를 보여주었다는 것을 알 수 있습니다.
이는 1024의 window size를 갖는 local attention을 포함했기 때문으로 해석하고 있습니다.
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- RNN과 gated linear recurrence를 결합한 Hawk, gated linear recurrence와 local attention을 결합한 Griffin을 제안
- Hawk는 특정 태스크에서 Mamba 수준의 성능을, Griffin은 Llama-2 수준의 성능을 보임. 특히 후자의 경우 학습 당시에 접한 텍스트 보다 긴 데이터에 대해서도 뛰어난 성능을 보임.
- 두 모델은 Transformers 대비 hardward efficient하며 lower latency & higher throughput을 가짐
출처 : https://arxiv.org/abs/2402.19427
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recu
arxiv.org
1. Introduction
최근에 Mamba 모델이 크게 주목을 받으면서 Transformer architecture를 넘어서는 아키텍쳐가 존재할 수 있을가에 대한 관심이 뜨겁습니다.
원래는 RNN 계통의 모델들은 parallel 학습이 불가능하기 때문에 (sequential한 연산) transformer 아키텍쳐가 선호되었는데, 이제는 오히려 RNN 기반의 아키텍쳐를 사용하면 sequence의 길이를 늘릴 수 있고 연산 속도도 빨라 초당 생성 토큰이 많다는 것이 장점으로 알려지고 있습니다.
물론 현재까지는 transformer 기반의 LLM 대비 상대적으로 훨씬 작은 크기의 모델들만 제시되었고 (3B 이하), 또 그 열풍의 중심에 서있던 Mamba 논문이 ICLR 2024에서 reject 당하면서 앞으로 이 분야의 연구가 어떻게 흘러갈지 다시 또 전혀 알 수 없게 된 상황입니다.
2. Related Works
- State-space Models (SSMs)
- S4, S5, H3
- RetNet
- RWKV
- Mamba
- Flash Attention
3. Model Architecture
본 모델 아키텍쳐를 구성하는 것은 크게 세 가지 요소입니다.
(a) a residual block
(b) an MLP block
(c) a temporal-mixing block
이때 (c) a temporal-mixing block의 경우,
(1) global Multi-Query Attention (MQA)
(2) local (sliding-window) MQA
(3) recurrent block (논문에서 제시한 방법)
이렇게 세 개의 block을 사용하여 그 실험 결과를 비교했다고 합니다.
그럼 각 요소를 하나씩 살펴보도록 하겠습니다.
3.1. Residual block
residual block은 그림의 (a)에서 볼 수 있는 것처럼 두 개의 요소로 구성되어 있습니다.
첫 번째 요소는 hidden state
그 결과는 skip connection을 통해
두 번째 역시 RMSNorm을 적용하는데, 이를 MLP block에 통과시킵니다.
마찬가지로 skip connection을 통해 RMSNorm에 들어갔던 입력과 합쳐줍니다.
3.2. MLP block
그림의 (b)와 같이 gated MLP block을 사용합니다.
이는
두 개의 branch에 속하는 linear layer들은
두 branch로부터의 결과를 element-wise multiplication (
단, 마지막 layer에 해당하는 경우
3.3. Temporal-mixing blocks
현재 그림 (c)에 나타난 것은 Recurrent block으로 본 연구에서 제시한 방법론입니다.
(1) Global multi-query attention (Transformer baseline)
기존 transformer architecture에서 사용하는 MHA (Multi-Head Attention) 대비 MQA 방식의 추론 효율이 좋다는 것은 잘 알려져 있습니다.
여기에서는
(2) Local sliding window attention
기존의 global attention은 시퀀스 길이에 quadratic하게 비례하여 computational complexity가 상승한다는 문제점이 있습니다.
이를 해결하기 위한 방법으로, sliding window attention이라고도 잘 알려진 local attention 방식이 도입되었습니다.
(3) Recurrent block (paper's)
Gated MLP block에서처럼 입력을 두 개의 branch로 나눠서 처리합니다. (parallel)
한쪽에서는 separable Conv1D layer를 통과시키는데, 이는 H3 모델의 Shift-SSM에서 영감을 받은 것이라고 합니다.
이때의 temporal filter diemnsion은 4이므로 굉장히 적은 parameter를 취한다고 하네요.
그리고 이 layer를 통과시켜 얻은 결과를 RG-LRU로 보냅니다.
(RG-LRU에 대해서는 곧 다룹니다)
반대쪽에서는 linear layer를 통과시켜 얻은 결과에 GeLU 활성화 함수를 적용하고,
두 branch로부터 얻은 결과를 element-wise multiplication 합니다.
그럼 이제 마지막으로 (3) Recurrent block에 사용되는 Real-Gated Linear Recurrent Unit (RG-LRU)에 대해서 알아보겠습니다.
3.4. Real-Gated Linear Recurrent Unit (RG-LRU)
RG-LRU layer는 Linear Recurrent Unit (LRU)에서 영감을 받은 아키텍쳐라고 합니다.
(Resurrecting Recurrent Neural Networks for Long Sequences: https://arxiv.org/abs/2303.06349)
즉, LRU 아키텍쳐에 LSTM 또는 GRU와 같은 gating system을 결합한 것이라고 합니다.
본 논문에서는 다음과 같은 notation들을 이용하여 RG-LRU를 설명하고 있습니다.
특히 세 번째 식은
자세한 식은 아래와 같습니다.
의미를 간단히만 정리해보겠습니다.
첫 번째, 두 번째 식은 각각 입력
sigmoid를 활성화 함수로 사용하고 있다는 것은
세 번째 식은 계산 편의를 위해 log로 변환하여 계산한다고 합니다.
이때
참고로 상세식에서 나타낸 softplus 함수의 경우 sigmoid의 적분 함수라고 합니다.
자세한 이해를 위해서는 LRU 논문의 수식들부터 먼저 잘 이해해야 할 것 같습니다.
마지막 네 번째 식을 보면
이를 바탕으로 이전 hidden state인
4. Recurrent Models Scale as Efficiently as Transformers
위에서 설명한 아키텍쳐를 바탕으로 수행한 실험 결과를 비교합니다.
사용된 베이스라인과 모델 설명을 간단히 하면 아래와 같습니다.
- MQA Transformer baseline
- residual pattern과 gated MLP를 사용한 베이스라인입니다. (1) MQA와 RoPE를 사용합니다.
- Hawk
- residual pattern과 gated MLP를 사용하되, MQA 대신 RG-LRU가 포함된 (3) recurrent block을 사용합니다.
- recurrent block의 폭을 대략 3/4 정도 확장했습니다. (
- Griffin
- MQA의 KV cache를 줄일 수 있는 local attention의 장점과 recurrent block의 장점을 아우르는 방식입니다.
- (3) recurrent block을 가진 residual block과 (2) local (MQA) attention block을 가진 residual block을 번갈아가면서 사용합니다.
Scaling curves
세 종류의 model families를 100M에서 7B parameters 사이즈로 학습하며 scaling합니다.
이때 Chinchilla scaling lwas를 따르며 MassiveText dataset을 사용했다고 합니다.
모델별 평가 결과를 나타낸 표는 다음과 같습니다.
실험 관련된 디테일한 내용들은 논문을 직접 참고해보시길 권장드립니다.
다만, 표에 색으로 구분해둔 것처럼 Hawk 모델은 Mamba에 준하는, 그리고 Griffin 모델은 Llama-2에 준하는 성능을 보였다는 것을 알 수 있습니다.
단순히 성능이 괜찮았다는 것이 포인트가 아니라, 학습에 사용된 모델의 아키텍쳐가 다르고, 또 여기에 사용된 데이터셋의 크기가 훨씬 작다는 점이 주목할만한 점입니다.
5. Other Experiments & Results
5.1. Training Recurrent Models Efficiently on Device
이 파트에서는 large scale training을 위한 model parallelism에 대해 다루고 있습니다.
키워드 두 개만 적자면,
- Megatron-style sharding
- ZeRO parallelism
입니다.
또한 학습에 TPU-v3를 사용했으며, 연산상 문제를 해결하기 위해 linear scan이라는 방법론을 적용했다고 밝혔습니다.
한편 더 긴 길이의 시퀀스에 대해 학습하게 되는 경우 transformer의 학습은 느려질 수밖에 없으나 Griffin은 거의 동일하게 유지된다고 합니다.
그러나 모델의 사이즈가 커질수록 여기에 포함되는 linear layer의 개수가 많아지고, 이로 인해 그 격차가 줄어들게 됩니다.
linear layer의 복잡도는
따라서 linear layer의 영향력이 커져 두 모델의 gap이 줄어든 것으로 이해할 수 있습니다.
5.2. Inference Speed
transformer 모델의 경우, 모델 자체의 파라미터와 KV 캐시로부터 대부분의 memory overhead가 발생합니다.
여기에 고려되는 배치 등의 요소를 나타내면 다음과 같습니다.
추론 속도를 평가하는 지표는 크게 두 가지로 latency와 throughput입니다.
latency가 특정 배치 사이즈에서 특정 개수의 토큰을 생성하는데 걸리는 시간이라면, throughput은 한 디바이스에서 1초에 생성할 수 있는 최대 토큰의 개수입니다.
당연하게도 latency를 줄이면 throughput을 늘릴 수 있는 관계입니다.
Hawk와 Griffin 모두 MQA 대비 더 낮은 latency를 갖는다는 것을 알 수 있습니다.
5.3. Long Context Modeling
단순히 결과만 언급하자면, Griffin의 long context 상황에서 next token prediction 능력이 압도적으로 좋다는 것을 알 수 있습니다.
local attention layer와 RoPE를 같이 사용하는 Griffin이 뛰어난 결과를 보여주었습니다.
한편, context로부터 관련된 토큰이나 문서를 찾는 태스크, Copy and retrieval capabilites를 수행한 결과도 제시하고 있습니다.
Hawk 모델이 Phonebook Lookup Task를 거의 수행하지 못한다는 점을 제외하면 나머지는 예상 가능했던 결과입니다.
이 태스크에서 특히 약세를 보이는 이유는 고정된 숫자의 state를 사용했기 때문이라고 합니다.
이와 달리 Griffin의 경우 동일 태스크에 대해서도 준수한 결과를 보여주었다는 것을 알 수 있습니다.
이는 1024의 window size를 갖는 local attention을 포함했기 때문으로 해석하고 있습니다.