
관심 있는 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
- scan된 문서에 대한 text와 layout 정보 간의 interaction을 함께 학습
- 사전학습 단계에서 문서 단위로 학습
출처 : https://arxiv.org/abs/1912.13318
1. Introduction
Business document를 이해하고 그 정보를 활용하기 위한 연구는 오래 전부터 이어져오고 있었습니다.
기존에는 대부분의 문서 작업을 사람이 직접 하는 방식이었기 때문에, 이를 인공지능 모델을 이용하여 효율적으로 해결하고자 한 것이죠.
그러나 실제로 여러 문서들은 다양한 layout과 형식으로 구성되는 경우가 많기도 하고, 스캔된 문서 이미지의 품질에 따라 영향을 크게 받는다는 것이 문제점으로 지적되었습니다.
문서에 대한 정보를 추출하기 위해 computer vision, natural language processing 또는 둘의 관점으로 deep neural network를 구축한 다양한 연구들이 있습니다.
논문에 제시되어 있기 때문에 여기서는 언급하지 않겠습니다만 어쨌든 기존 방식에 하자가 있다는 것을 추가적으로 언급하고 있습니다.
가장 핵심적인 문제점 두 가지가 정리되어 있는데, 첫째로 few human-labeled 학습용 데이터를 사용한다는 것입니다.
즉, 기존 AI 모델들은 supervised learning을 하다 보니 이를 위해 필요한 데이터를 직접 구축해야 하는 것이 큰 한계점이라는 것이죠.
이런 방식으로는 대량의 데이터를 확보하기가 어렵다는 근본적인 문제점이 있습니다.
둘째는 CV 모델과 NLP 모델을 별도로 학습한다는 것입니다.
한 문서에 대한 이미지 정보와 텍스트 정보를 별도로 다루는 모델들의 조합이다보니 올바른 문서 이해가 어렵다고 보는 것이죠.
이는 다소 결과론적인 해석이라는 생각도 듭니다.
왜냐하면 end-to-end 방식이 좋은지 아닌지는 성능으로 말하는 경우가 많기 때문입니다..
어쨌든 이를 문제점으로 지적하며 본 논문에서는 joint training 방식을 도입했음을 강조하고 있습니다.
2. LayoutLM
LayoutLM 모델을 BERT의 아키텍쳐와 사전학습된 가중치를 사용합니다.
그래서 논문에서는 BERT 모델에 대한 설명을 간단히 제시하고 있습니다.
혹시나 BERT에 대한 자세한 설명이 필요하신 분은 링크를 참고해주세요.
여기서 BERT를 언급하는 핵심적인 이유는 'self-supervised task with large-scale training data'입니다.
위에서 언급한 첫 번째 문제점을 해결할 수 있는 아주 좋은 해결책이라는 것이죠.
BERT에서는 MLM(Masked Language Modeling)과 NSP(Next Sentence Prediction)이라는 두 사전학습 태스크가 제시되었는데, 이중에서 MLM을 multi-modal 모델에 맞게끔 적용한 것(Masked Visual-Language Modeling, MVLM)이 핵심이라고 볼 수 있겠습니다.
The LayoutLM Model
문서와 관련된 태스크 중에서는 오직 텍스트만을 활용하여 처리하는 경우가 많았다고 합니다.
이를테면 BERT, RoBERTa와 같은 모델을 사용하여 주어진 텍스트들이 어떤 정보에 해당하는 것인지 분류하는 등으로 처리할 수 있었던 것이죠.
그러나 이는 근본적으로 문서의 layout과 같은 시각적 정보를 전혀 사용하지 않는 방식이므로, 이를 텍스트 정보와 align 할 수 있다면 큰 성능 향상을 도모할 수 있을 것이라는 가설을 세우게 됩니다.
언어에 대한 representation을 개선하기 위해 여기서 제시한 방법을 두 가지입니다.
Document Layout Information
어떤 텍스트가 문서 내 어디에 위치하고 있는지에 대한 정보는 AI 모델이 텍스트에 대해 더욱 정교한 이해를 할 수 있도록 도와줍니다.
예를 들어 문서의 제목은 주로 문서의 가장 맨 위, 중간에 위치하는 경향이 있겠죠.
따라서 본 연구에서는 텍스트의 위치를 2D로 제공하게 됩니다.
Visual Information
이미지로부터 직접 획득 가능한 시각적인 정보는 문서에 대한 이해도를 높이는데 충분히 도움이 될 수 있습니다.
예를 들어 밑줄, 글자의 두께, 기울기 등 텍스트의 다양한 특징들을 활용할 수 있죠.
따라서 전통적인 text의 representation에 image의 특징을 결합함으로써 보다 유의미한 representation을 이끌어낼 수 있을 것으로 보고 있습니다.
Model Architecture
BERT의 아키텍쳐를 활용하여 사전학습된 모델의 이점을 이용했습니다.
이때 텍스트의 위치에 관한 2-D position embedding과 image embedding을 함께 더해준다는 특징을 갖고 있습니다.
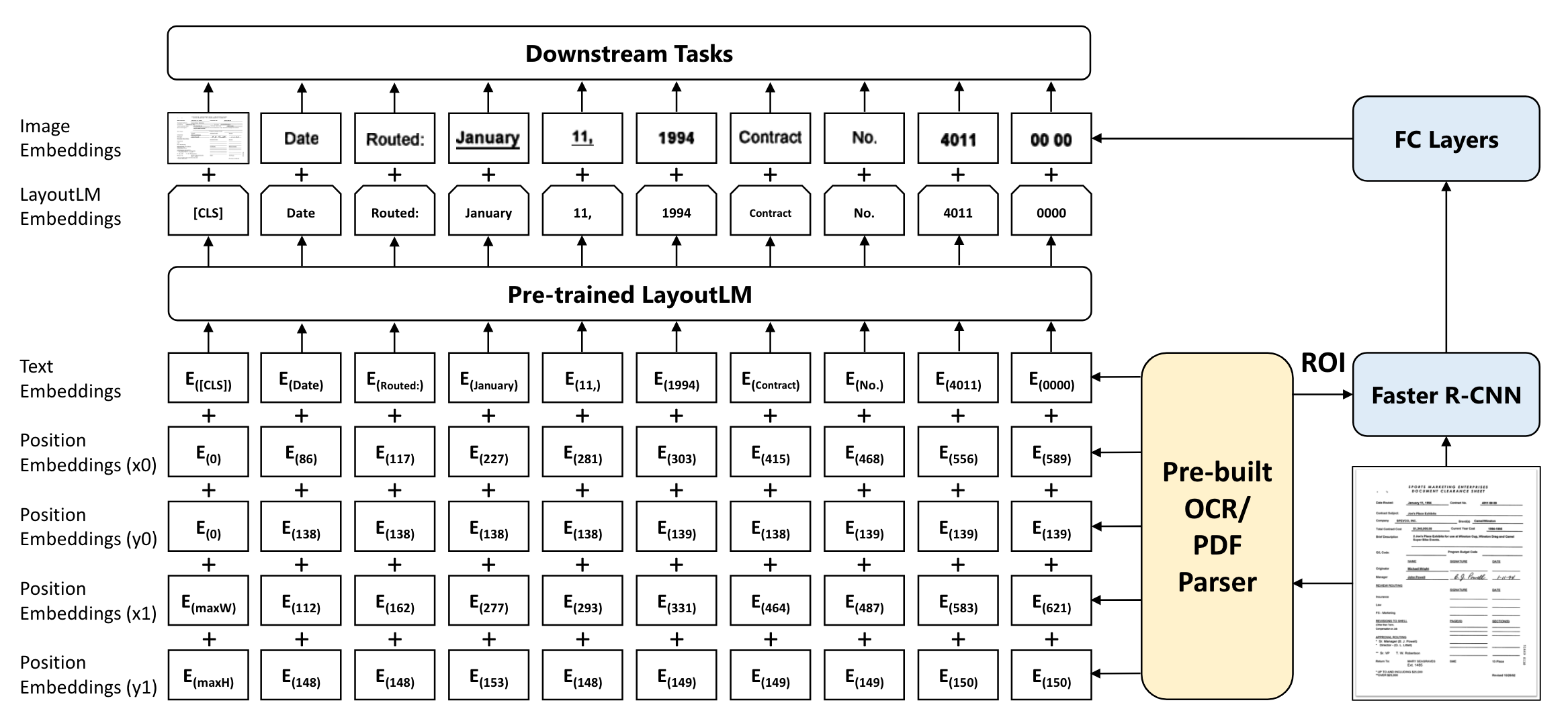
2-D Position Embedding
$(x_0, y_0, x_1, y_1)$으로 정의된 bounding box를 뜻합니다. $(x_0, y_0)$은 bounding box의 좌상단, $(x_1, y_1)$은 bounding box의 우하단에 해당합니다.
이때 $x,y$는 각각의 embedding table을 사용합니다.
Image Embedding
이미지를 여러 조각으로 나누고 단어와 일대일로 대응하는 쌍을 만들어줍니다.
Faster R-CNN 모델로부터 각 조각들의 image region feature를 생성합니다.
또한 스캔된 전체 문서 이미지에 대해서도 Faster R-CNN 모델을 사용하여 [CLS] 토큰으로부터 embedding을 구합니다.
Pre-training LayoutLM
Masked Visual-Language Model (MVLM)
위에서 설명했던대로, BERT의 MLM에서 영감을 받아 MVLM을 제안했습니다.
이는 2-D position embedding과 text embedding을 함께 이용하여 masked token을 복원하는 학습 방식입니다.
모델은 이를 통해 텍스트에 대한 정보 뿐만 아니라 이에 상응하는 2-D 위치 정보도 함께 학습할 수 있게 됩니다.
Multi-label Document Classification
IIT-CDIP Text Collection은 각 이미지에 대해 여러 개의 태그 정보를 포함하고 있습니다.
이에 대해 Multi-label Document Classification (MDC) loss를 사용했다고 합니다.
모델은 이를 통해 여러 도메인으로터의 지식을 clustering하게 됩니다.
실험 단계에서는 이것이 유의미한 loss인지 아닌지를 파악하기 위해 MVLM만 적용했을 때, 그리고 MVLM + MDC를 적용했을 때의 결과를 비교합니다.
Fine-tunign LayoutLM
사전학습이 끝난 LayoutLM 모델은 'form understanding taks, a receipt understanding task, document inmage classification task', 총 세 개의 태스크에 대해 fine-tuning 합니다.
3. Expermiments
Pre-training Dataset
IIT-CDIP Test Collection 1.0을 사용했다고 합니다.
이는 6백만 개 이상의 문서 1100만 개 이상의 스캔된 이미지를 포함하고 있습니다.
각 문서에 대한 텍스트와 메타데이터는 XML 파일로 저장되어 있다고 합니다.
Fine-tuning Dataset
- The FUNSD Dataset: noisy scanned document의 form understanding을 평가하기 위한 데이터셋입니다. 199개의 fully annotated 데이터를 포함하고 있습니다. 이중 149개는 학습용 50개는 평가용입니다.
- The SROIE Dataset: 영수증에 나타난 정보를 추출하는 능력을 평가하기 위한 데이터셋입니다. 학습용과 평가용으로 각각 626개, 347개의 데이터를 사용합니다. 여기서는 'company, date. address, total' 네 개의 entities를 추출하게 됩니다.
- The RVL-CDIP Dataset: 16개 클래스로 나뉘는 400,000개의 흑백 이미지로 구성된 데이터셋입니다. 각 클래스는 25,000개의 이미지로 구성됩니다. 이는 학습용과 검증용, 테스트용으로 각각 320,000개, 40,000, 40,000개로 나뉩니다.
Document Pre-processing
IIT-CDIP Test Collection에는 bounding box에 관한 정보가 포함되어 있지 않습니다.
저자들은 layout 관련 정보를 확보하기 위해 스캔된 이미지를 re-process 했다고 밝힙니다.
여기에는 open-source OCR engine으로 잘 알려진 Tesseract를 사용했다고 합니다.
Model Pre-training
Layoutlm 모델은 BERT의 아키텍쳐를 따르고 있다고 위에서 말씀드렸습니다.
그래서 BERT의 가중치를 그대로 사용하게 됩니다.
즉, BASE 모델의 경우 768차원의 12개 Transformer 레이어, 12개의 attention head, 113M 개의 파라미터로 구성되어 있는데, 동일 사이즈의 BERT 모델의 가중치를 initial point로 사용했다고 합니다.
다만 텍스트의 2-D position embedding을 추가했다는 점이 특징입니다.
이때 이미지마다 사이즈가 전부 다를 수 있으므로 좌표값을 0부터 1,000 사이의 값으로 scaling 해야 합니다.
Task-specific Fine-tuning
세 개의 태스크에 대해 fine-tuning을 수행했다고 말씀드렸는데, 각각 어떤 세팅으로 모델을 학습했는지에 대한 설명이 논문에 제시되어 있습니다.
궁금하신 분들은 직접 한 번 확인해보시길 추천드립니다.
Results
실험 결과에 대한 설명도 여럿 제시되어 있으나 자세히 다루지는 않겠습니다.
간단히만 정리하면 다음과 같습니다.
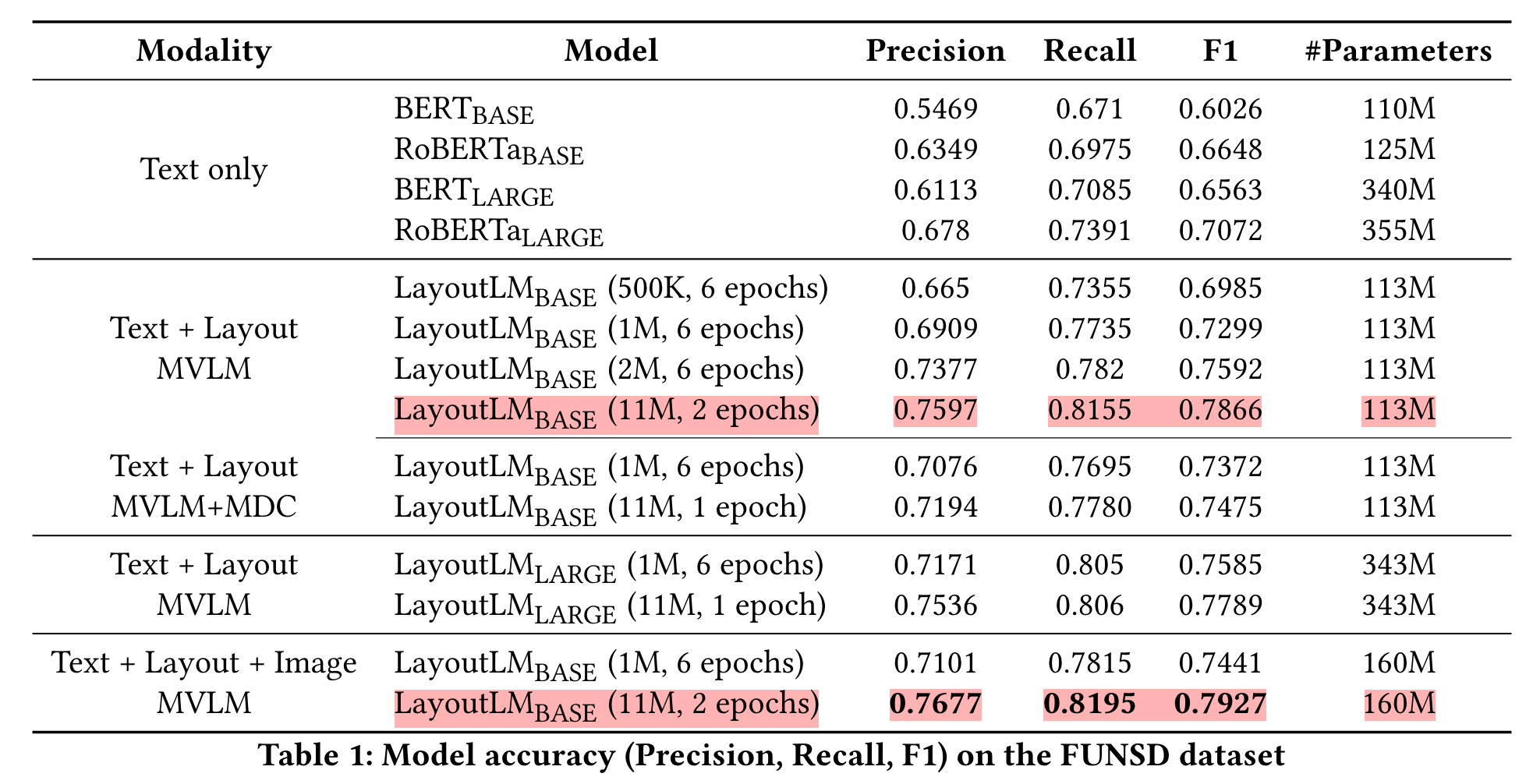
- 기존의 언어 모델(BERT, RoBERTa)에 비해 훨씬 뛰어난 성능을 자랑한다.
- 큰 모델의 성능이 작은 모델에 비해 크게 뛰어나다.
- MVLM + MDC를 적용한 것이 MVLM을 단독으로 사용한 것보다 좋은 결과로 이어졌다.
- 여기에 Image 정보를 추가하면 최고의 결과물을 얻을 수 있다.
4. Related Work
관련 연구를 키워드로 일부 제시하면 다음과 같습니다.
- Rule-based Approaches
- Bottom-up methods
- Docstrum algorithm
- Machine Learning Approaches
- Deep Learning Approaches
- pixel-by-pixel classification problem