
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
- 3.3T개 토큰을 학습한 3.8B 사이즈의 모델 phi-3-mini를 공개. 사이즈가 굉장히 작음에도 불구하고 Mixtral 8x7B, GPT-3.5급의 추론 능력을 보여주어 화제.
- multi-lingual 특성을 강화하여 학습한 phi-3-small 모델(7B)과 mini 모델을 추가학습한 phi-3-medium 모델(14B)을 함께 공개
출처 : https://arxiv.org/abs/2404.14219
1. Introduction
지난 몇 년 간 인공지능의 눈부신 발전은 점점 더 큰 모델과 데이터셋을 만드는, scaling-up에 근거하고 있습니다.
수도 없이 많은 Large Language Models(LLMs)과 그 variation 모델들이 쏟아져 나오고 있습니다.
이는 또 모델의 크기와 학습에 사용되는 데이터셋의 사이즈가 일정한 scale을 갖추고 있음을 주장한 scaling law를 따르고 있죠.
이러한 기조와 달리 Microsoft에서 Phi 모델을 만든 것은 사이즈가 작음(사실 그렇게 작진 않지만 LLM에 비하면..😅)에도 불구하고 뛰어난 '추론' 능력을 갖추게 만들고 싶어서라고 볼 수 있습니다.
왜냐하면 일반적으로 개인이나 작은 단체에서 운용 가능한 13B 이하의 모델들은 특히나 추론과 같은 태스크에 취약하다는 것이 잘 알려져 있었기 때문입니다.
그래서 이를 단순히 emergent ability 중 하나로 해석하는 것이 아니라, 작은 모델에서도 큰 모델이 지닌 능력들을 보유하게 만드는 것에 관한 연구가 진행된 것이죠.
이 연구의 가장 중요한 핵심은 "데이터셋"이라고 강조합니다.
여기에는 웹에 존재하는 데이터를 빡세게 필터링해서 얻은 데이터와 LLM을 통해 생성한 데이터가 활용된다고 해요.
자세한 내용은 후술하겠습니다.
2. Technical Specifications
| context length | training tokens | hidden dimension | tokenizer | vocab size | model size | |
| phi-3-mini | 4K | 3.3T | 3072 | llama | 32064 | 3.8B |
| phi-3-mini-128K | 128K (LongRoPE) | 3.3T | 3072 | llama | 32064 | 3.8B |
| phi-3-small | 8K | 3.3T + 10% extra | 4096 | tiktoken | 100352 | 7B |
| phi-3-medium | 4K | 4.8T | 5120 | llama | 32064 | 14B |
phi-3-mini 모델은 이미 chat-finetuned 모델입니다.
사용 가능한 채팅 탬플릿은 다음과 같습니다.
<|user|>/n Question <|end|>/n <|assistant|>
이 모델을 4-bit로 quantization하면 1.8GB 정도의 메모리에 할당할 수 있다고 합니다.
이를 iPhone 14에 deploy 가능하다고 하네요.
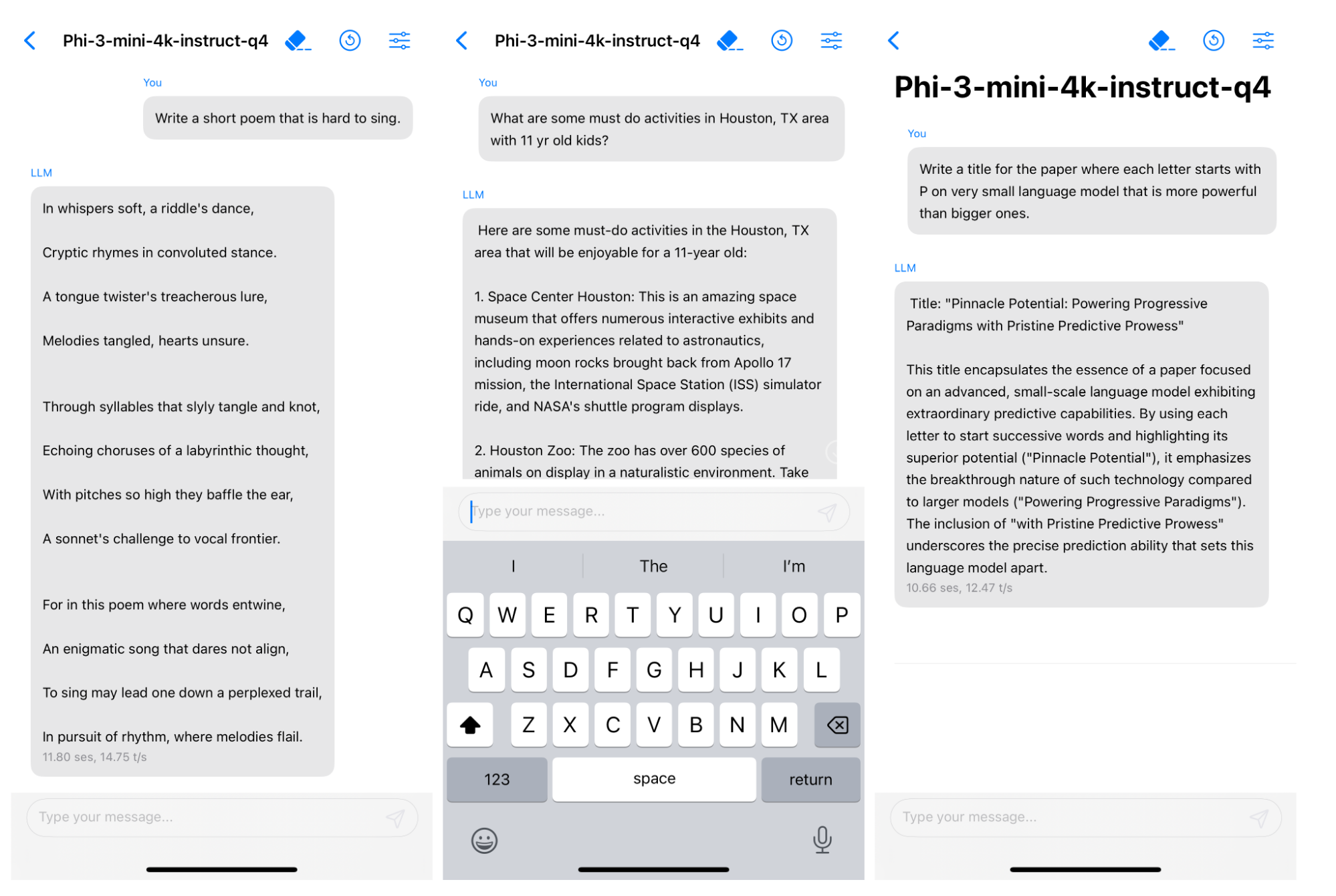
레포트에는 "Textbooks Are All You Need" 방식을 따랐다고 합니다.
즉, 데이터의 퀄리티를 높게 보장하는 것이 더 중요하다고 언급한 것입니다.
filtered web data와 LLM-generated data를 합칩니다.
둘을 이용한 사전학습은 두 단계로 구성됩니다.
첫 단계에서는 web source 데이터를 주로 사용하여 모델에게 일반적 지식과 언어에 대한 이해를 학습시킵니다.
다음 단계에서는 논리적 추론과 다양한 스킬들을 학습할 수 있도록 돕는 합성 데이터를 병합하여 학습을 진행합니다.
phi-3-small 모델의 경우 mini 버전과 다른 토크나이저를 사용했다는 것이 특징입니다.
또한 medium 버전은 mini 버전을 같은 데이터에 대해 추가 학습한 버전입니다.
그러나 최적의 상태로 만든 것은 아니기 때문에 일종의 preview로 해석할 수 있다고 언급하네요.
모든 모델들은 supervised instruction fine-tuning과 preference tuning with DPO를 마지막에 적용하게 됩니다.
3. Academic benchmarks
베이스라인으로는 phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-instruct-8b, GPT-3.5가 쓰였다고 합니다.
llama-3 모델을 벌써 사용하고 그 결과를 비교하여 공개한 것이 놀랍네요 😲
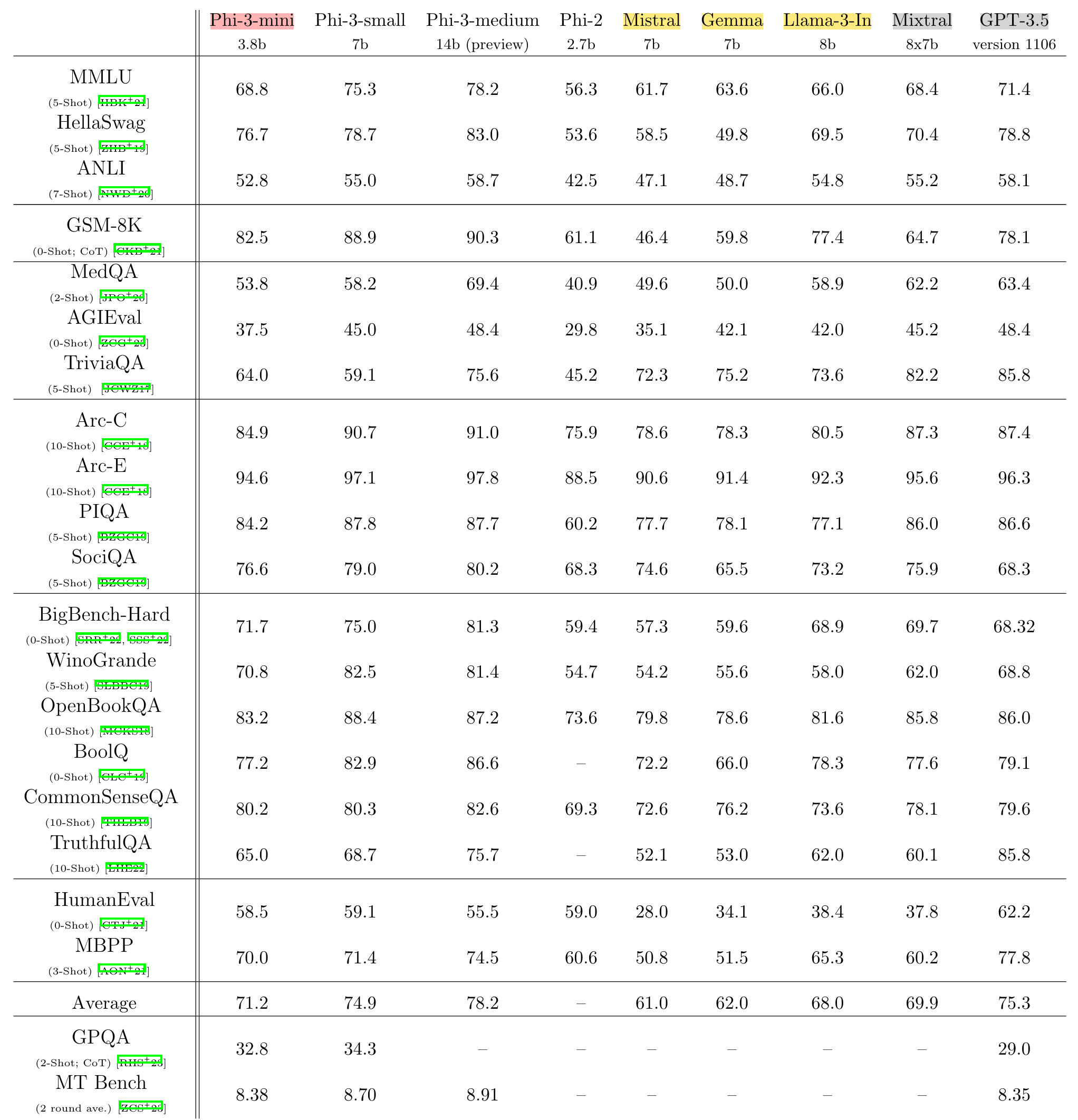
phi-3 모델을 위한 별도의 파이프라인을 갖추지는 않았다고 합니다.
일반적으로 LLM을 평가하기 위해 사용되는 few-shot example을 동일하게 적용하였으며 appendix에는 2-shot prompt를 공개했습니다.

4. Safety
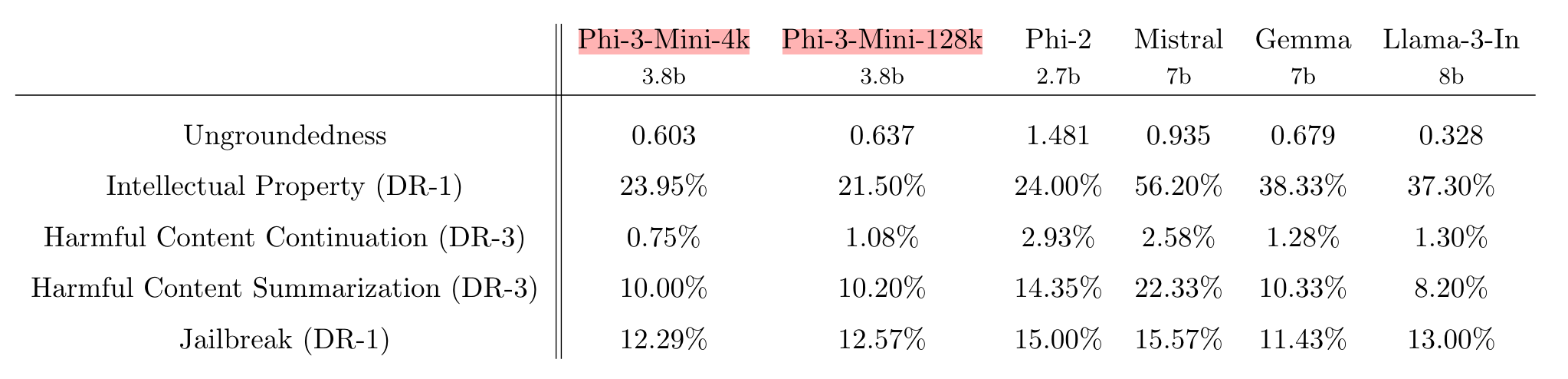
타모델과의 ungroundedness를 비교하고 있습니다.
수치가 높을 수록 여러 턴의 대화에서 근거 없는 생성 결과를 만들었다는 걸 의미합니다.
즉, Phi 모델들이 이전의 대회를 근거로 추가적인 텍스트를 생성하고 있다고 해석 가능합니다.
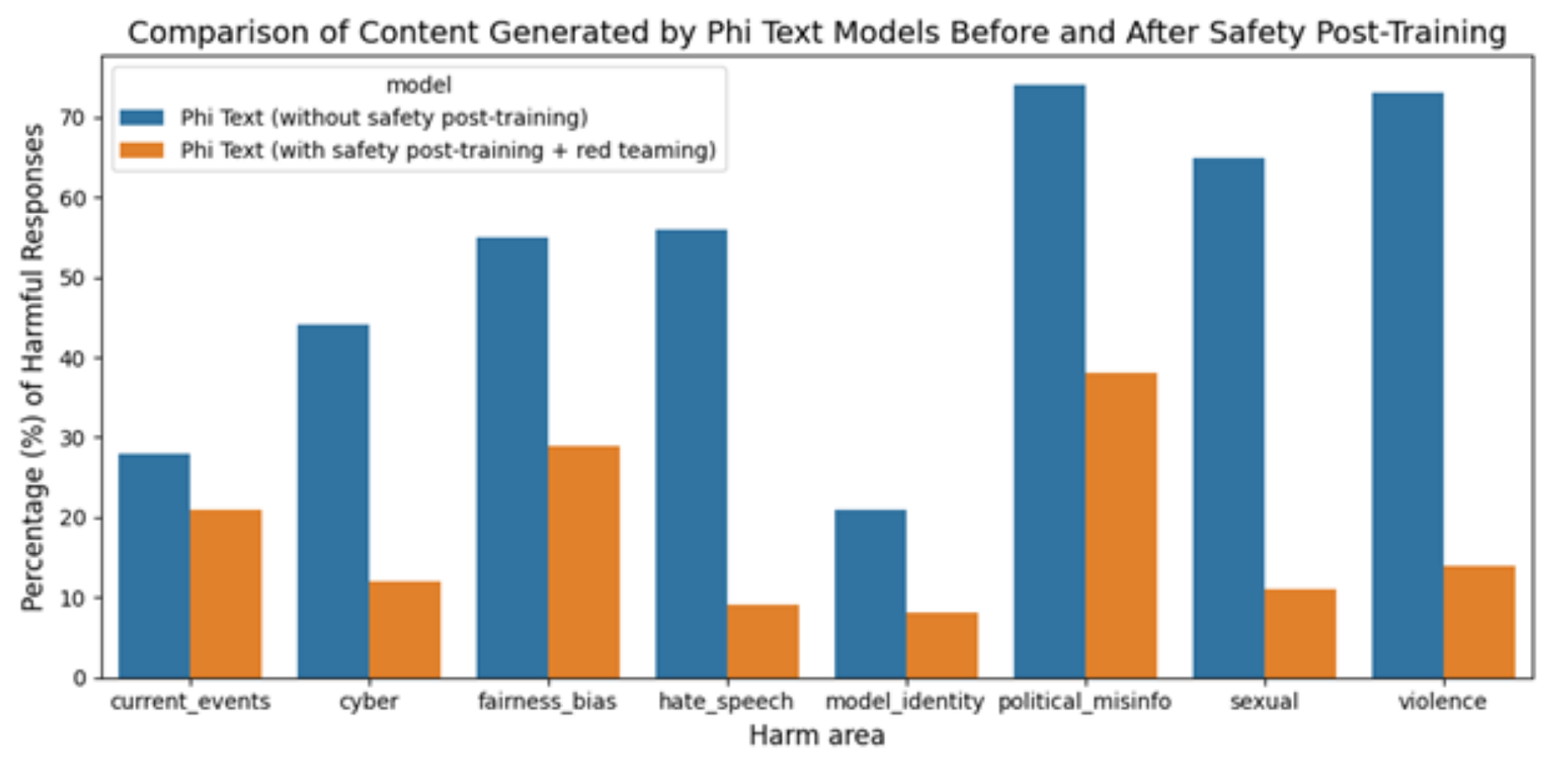
모델의 안정성과 관련해서는 내부팀의 피드백을 받았다고 합니다.
이를 바탕으로 추가적인 데이터셋을 구축하여 post-training을 적용한 결과가 주황색 그래프로 나타납니다.
이전 대비 harmful response를 생성할 가능성이 확연히 낮아지게 된 것을 알 수 있습니다.
5. Weakness
레포트에서는 이 모델의 약점을 크게 두 가지로 들고 있습니다.
1. 특정 태스크에서 모델 사이즈로 인한 한계를 극복하지 못했다.
이를테면 'factual knowledge'를 많이 저장하고 있지는 못한 것으로 확인되었습니다.
이것은 TriviaQA와 같은 벤치마크의 성적이 유독 낮다는 것을 토대로 알 수 있던 정보입니다.
이를 해결하기 위한 방식으로 search engine을 제시하는데, 체리피킹의 결과일수도 있겠지만 레포트에 포함된 것만 보면 꽤 괜찮습니다.

2. 언어가 영어로 제한된다.
Small Language Models의 향후 발전 과제로 multilingual capabilities를 들고 있습니다.
당연한 이야기지만.. 한 개의 언어에 대해서도 좋은 퍼포먼스를 보이지 못하는 모델이 다른 언어까지 함께 잘 처리하길 기대하는 건 무리겠죠.
다른 언어를 입력으로 주지 못하진 않겠지만 결과가 어떨지는 뻔한 것 같습니다 😅
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
- 3.3T개 토큰을 학습한 3.8B 사이즈의 모델 phi-3-mini를 공개. 사이즈가 굉장히 작음에도 불구하고 Mixtral 8x7B, GPT-3.5급의 추론 능력을 보여주어 화제.
- multi-lingual 특성을 강화하여 학습한 phi-3-small 모델(7B)과 mini 모델을 추가학습한 phi-3-medium 모델(14B)을 함께 공개
출처 : https://arxiv.org/abs/2404.14219
1. Introduction
지난 몇 년 간 인공지능의 눈부신 발전은 점점 더 큰 모델과 데이터셋을 만드는, scaling-up에 근거하고 있습니다.
수도 없이 많은 Large Language Models(LLMs)과 그 variation 모델들이 쏟아져 나오고 있습니다.
이는 또 모델의 크기와 학습에 사용되는 데이터셋의 사이즈가 일정한 scale을 갖추고 있음을 주장한 scaling law를 따르고 있죠.
이러한 기조와 달리 Microsoft에서 Phi 모델을 만든 것은 사이즈가 작음(사실 그렇게 작진 않지만 LLM에 비하면..😅)에도 불구하고 뛰어난 '추론' 능력을 갖추게 만들고 싶어서라고 볼 수 있습니다.
왜냐하면 일반적으로 개인이나 작은 단체에서 운용 가능한 13B 이하의 모델들은 특히나 추론과 같은 태스크에 취약하다는 것이 잘 알려져 있었기 때문입니다.
그래서 이를 단순히 emergent ability 중 하나로 해석하는 것이 아니라, 작은 모델에서도 큰 모델이 지닌 능력들을 보유하게 만드는 것에 관한 연구가 진행된 것이죠.
이 연구의 가장 중요한 핵심은 "데이터셋"이라고 강조합니다.
여기에는 웹에 존재하는 데이터를 빡세게 필터링해서 얻은 데이터와 LLM을 통해 생성한 데이터가 활용된다고 해요.
자세한 내용은 후술하겠습니다.
2. Technical Specifications
| context length | training tokens | hidden dimension | tokenizer | vocab size | model size | |
| phi-3-mini | 4K | 3.3T | 3072 | llama | 32064 | 3.8B |
| phi-3-mini-128K | 128K (LongRoPE) | 3.3T | 3072 | llama | 32064 | 3.8B |
| phi-3-small | 8K | 3.3T + 10% extra | 4096 | tiktoken | 100352 | 7B |
| phi-3-medium | 4K | 4.8T | 5120 | llama | 32064 | 14B |
phi-3-mini 모델은 이미 chat-finetuned 모델입니다.
사용 가능한 채팅 탬플릿은 다음과 같습니다.
<|user|>/n Question <|end|>/n <|assistant|>
이 모델을 4-bit로 quantization하면 1.8GB 정도의 메모리에 할당할 수 있다고 합니다.
이를 iPhone 14에 deploy 가능하다고 하네요.
레포트에는 "Textbooks Are All You Need" 방식을 따랐다고 합니다.
즉, 데이터의 퀄리티를 높게 보장하는 것이 더 중요하다고 언급한 것입니다.
filtered web data와 LLM-generated data를 합칩니다.
둘을 이용한 사전학습은 두 단계로 구성됩니다.
첫 단계에서는 web source 데이터를 주로 사용하여 모델에게 일반적 지식과 언어에 대한 이해를 학습시킵니다.
다음 단계에서는 논리적 추론과 다양한 스킬들을 학습할 수 있도록 돕는 합성 데이터를 병합하여 학습을 진행합니다.
phi-3-small 모델의 경우 mini 버전과 다른 토크나이저를 사용했다는 것이 특징입니다.
또한 medium 버전은 mini 버전을 같은 데이터에 대해 추가 학습한 버전입니다.
그러나 최적의 상태로 만든 것은 아니기 때문에 일종의 preview로 해석할 수 있다고 언급하네요.
모든 모델들은 supervised instruction fine-tuning과 preference tuning with DPO를 마지막에 적용하게 됩니다.
3. Academic benchmarks
베이스라인으로는 phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-instruct-8b, GPT-3.5가 쓰였다고 합니다.
llama-3 모델을 벌써 사용하고 그 결과를 비교하여 공개한 것이 놀랍네요 😲
phi-3 모델을 위한 별도의 파이프라인을 갖추지는 않았다고 합니다.
일반적으로 LLM을 평가하기 위해 사용되는 few-shot example을 동일하게 적용하였으며 appendix에는 2-shot prompt를 공개했습니다.
4. Safety
타모델과의 ungroundedness를 비교하고 있습니다.
수치가 높을 수록 여러 턴의 대화에서 근거 없는 생성 결과를 만들었다는 걸 의미합니다.
즉, Phi 모델들이 이전의 대회를 근거로 추가적인 텍스트를 생성하고 있다고 해석 가능합니다.
모델의 안정성과 관련해서는 내부팀의 피드백을 받았다고 합니다.
이를 바탕으로 추가적인 데이터셋을 구축하여 post-training을 적용한 결과가 주황색 그래프로 나타납니다.
이전 대비 harmful response를 생성할 가능성이 확연히 낮아지게 된 것을 알 수 있습니다.
5. Weakness
레포트에서는 이 모델의 약점을 크게 두 가지로 들고 있습니다.
1. 특정 태스크에서 모델 사이즈로 인한 한계를 극복하지 못했다.
이를테면 'factual knowledge'를 많이 저장하고 있지는 못한 것으로 확인되었습니다.
이것은 TriviaQA와 같은 벤치마크의 성적이 유독 낮다는 것을 토대로 알 수 있던 정보입니다.
이를 해결하기 위한 방식으로 search engine을 제시하는데, 체리피킹의 결과일수도 있겠지만 레포트에 포함된 것만 보면 꽤 괜찮습니다.
2. 언어가 영어로 제한된다.
Small Language Models의 향후 발전 과제로 multilingual capabilities를 들고 있습니다.
당연한 이야기지만.. 한 개의 언어에 대해서도 좋은 퍼포먼스를 보이지 못하는 모델이 다른 언어까지 함께 잘 처리하길 기대하는 건 무리겠죠.
다른 언어를 입력으로 주지 못하진 않겠지만 결과가 어떨지는 뻔한 것 같습니다 😅