
-
1. Introduction
-
2. Related Work
-
2.3.1. Pre-trained Language Models for 2D Text Blocks
-
2.3.2. Parsers for Document Key Information Extraction
-
3. BERT Relying on Spatiality (BROS)
-
3.1. Encoding Spatial Information into BERT
-
3.2. Area-masked Language Model
-
4. Key Information Extraction Tasks
-
5. Experiments
-
5.1. With the Order Information of Text Blocks
-
5.2. Without the Order Information of Text Blocks
-
5.3. Learning from Few Training Examples
-
5.4. Ablation Study
-
6. Conclusion
관심 있는 고전(?) 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Naver Clova, KAIST, LBox, Upstage]
- Key information extraction (KIE) 태스크를 잘 처리하기 위해 text와 layout을 효과적으로 결합하는 방식을 고안
- BROS (BERT Relying On Spatiality): text를 2D 공간에서 relative position encoding 하고 area-masking strategy를 적용
- 현실 세계에서 다루기 어려운 두 가지의 문제(incorrect text ordering, fewer downstream examples)에도 강건함을 보임
출처 : https://arxiv.org/abs/2108.04539
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combin
arxiv.org
1. Introduction
영수증과같은 문서 이미지에서 특정 정보를 추출해내는, KIE 태스크를 처리하기 위한 다양한 시도들이 존재했습니다.
여기서는 문서 이미지의 특성을 고려하여 다양한 'layout'을 모델이 이해할 수 있도록 만드는 것이 중요하게 여겨집니다.
흐름을 간단히 도식화한 이미지는 다음과 같습니다.

문서 이미지에 대해 OCR을 적용하고, 인식한 글자를 serializer로 읽어줍니다.
보통 좌상단 → 우하단 순서로 읽습니다.
그 결과를 Parsing Model에 입력하여 key information을 획득합니다.
여기서 문제가 되는 것 중 하나는 Serializer입니다.
정확도가 높으면서도 가져다 쓰기 쉬운 tool이 많은 OCR과 달리, 형태가 수도 없이 다양하게 존재하는 문서들의 읽는 순서를 결정해줄 수 있는 범용성 좋은 Serializer는 존재하지 않기 때문입니다.
(지금도 이것이 큰 문제로 여겨집니다)
또한 어떻게 잘 텍스트를 읽어냈다고 하더라도, 문서라는 2D 공간에 존재하는 텍스트를 1D로 처리하는 것 자체가 곧 정보의 손실이라고 볼 수 있습니다.
그래서 이와 같은 방식으로 KIE를 처리하던 BERT 대신에 (BERT는 1D positional encoding을 사용)
layout 정보를 다룰 수 있도록 만든 LayoutLM이 히트를 치게 됩니다.
LayoutLM의 등장 이후로는 text, layout 정보에 더해 visual feature를 얹어 모델의 성능을 높이고자 하는 시도가 많았습니다.
그러나 visual feature가 더해져 추가적인 연산 비용이 요구된다는 것은 자명한 사실이죠.
이러한 배경에서 본 논문은 BROS라는 모델을 제시하는데 다음 두 가지가 중요한 특징입니다.
- visual feature에 의존하지 않는다. 오직 text와 layout으로 승부를 본다.
- 여기에 정교한 spatial encoding 기법을 활용한다.
- area-masked language model을 제시한다.
- MLM과 동시에 사용한다. AMLM은 SpanBERT에서 영감을 받았다.
2. Related Work
2.3.1. Pre-trained Language Models for 2D Text Blocks
- 위에서 언급했던 것처럼 BERT 대신 LayoutLM 모델이 KIE에서 선풍적인 인기를 끌게 됩니다.
- 여기서는 layout 정보를 반영하기 위해 absolute position을 사용합니다.
- 이후에는 visual feature를 통합하기 위한 노력이 이어집니다.
- 그러나 raw document image를 처리하기 위한 추가적인 연산이 필요하게 되었습니다.
- StructuralLM 모델은 cell information(a group of ordered text blocks)을 사용했습니다.
- 그러나 KIE 태스크를 위해 OCR을 적용하게 되면 text block 간의 local order는 획득할 수 없어 일반적으로 적용 가능한 방법론이 아닙니다.
2.3.2. Parsers for Document Key Information Extraction
- entity extraction의 대표 중 하나는 BIO tagger입니다.
- 그러나 정보를 추출하기 위해서는 text block 간의 정확한 순서 정보가 요구된다는 것이 문제입니다.
- 또한 token들 간의 관계 정보가 요구된다는 점도 문제로 볼 수 있습니다.
- 이를 해결하기 위해 graph-based parser, SPADE decoder를 사용합니다.
- 본 논문에서 실험하는 task 중에 'Entity Linking'에 적용합니다.
- SpaDE 논문 링크: https://arxiv.org/abs/2209.05917
3. BERT Relying on Spatiality (BROS)
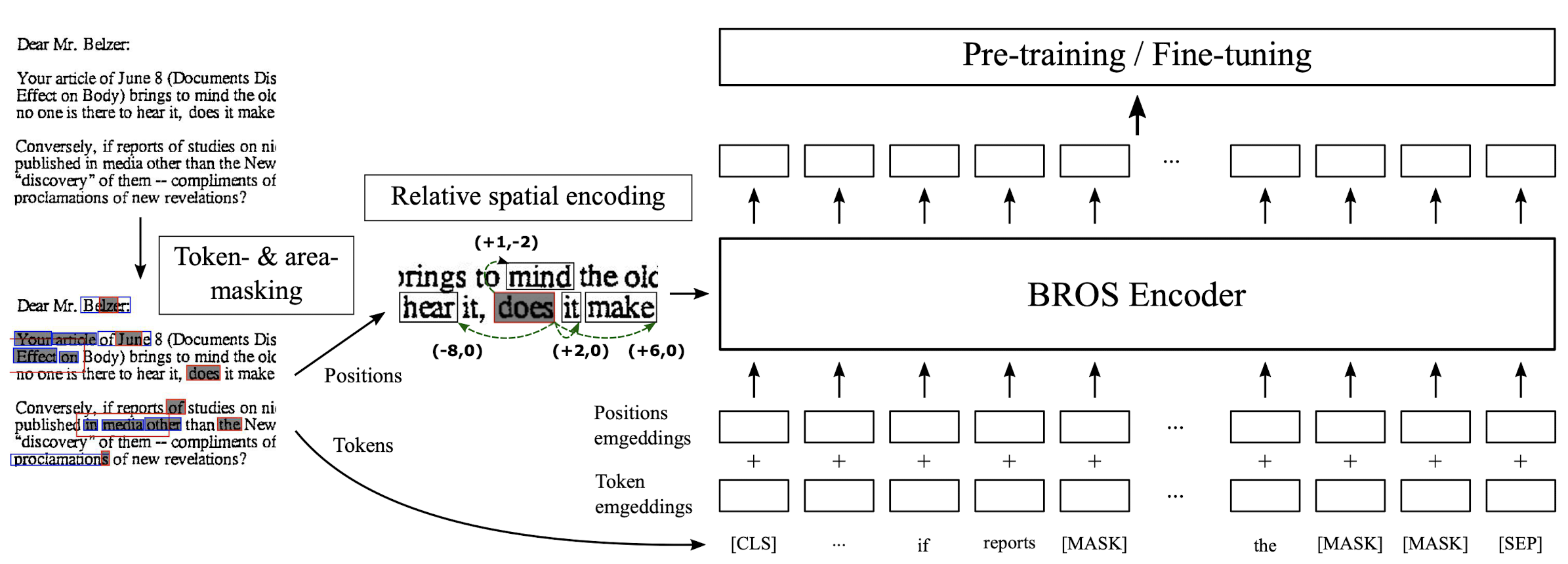
BROS는 LayoutLM의 main structure를 따릅니다.
그러나 위에서 언급한 것처럼 텍스트와 관련된 2D 정보를 유지하기 위한 Encoding 기법,
그리고 사전학습 시 Area-masking 전략을 활용한 것을 차별점으로 두고 있습니다.
3.1. Encoding Spatial Information into BERT
Text와 함께 공간 정보를 encoding 하는 방법은 LayoutLM에서 이미 제시했다고 했습니다.
그러나 여기서는 텍스트 블록 간의 "relative position"을 이용합니다.
(LayoutLMv2도 relative position encoding을 사용한 것으로 알고 있으나 이는 언급되지 않았습니다)
기존 방식과 비교한 이미지는 다음과 같습니다.

저자는 (b) 방식을 이용하면 위치 정보를 표현하기 위해 필요한 co-modality를 유지할 수 있다고 주장합니다.
어쨌든 realtive position을 encoding하는 과정은 이렇습니다.
1) 비교하고자 하는 두 텍스트 블록 $i$와 $j$를 정한다.
2) 각 텍스트 블록의 $x$, $y$ 좌표값을 '좌상단, 우상단, 우하단, 좌하단' 순으로 구한다.
: 이때 좌표값은 이미지 사이즈를 기준으로 noramlized 된 값을 사용합니다.
: $p^{\text{tl}}, p^{\text{tr}}, p^{\text{br}}, p^{\text{bl}}$
3) 두 블록 간의 $x$, $y$ 차이값을 $f^{\text{sinu}}$에 입력하여 얻은 $D^s$ 차원의 벡터를 concat 한다.
(좌상단, 우상단, 우하단, 좌하단, 총 네 개의 벡터가 생김)
: $\bar{p}_{i,j} = \left [ f^{\text{sinu}}(x_i - x_j);f^{\text{sinu}}(y_i - y_j) \right ]$
: $f^{\text{sinu}}:\mathbb{R} \rightarrow \mathbb{R}^{D^S}$
4) 각 벡터에 linear transition matrix를 곱하고 그 결과를 더한다.
: $\overline{bb}_{i,j} = W^{\text{tl}}\bar{p}^{\text{tl}}_{i,j} + W^{\text{tr}}\bar{p}^{\text{tr}}_{i,j} + W^{\text{br}}\bar{p}^{\text{br}}_{i,j} + W^{\text{bl}}\bar{p}^{\text{bl}}_{i,j}$
: $W^{\text{tl}}, W^{\text{tr}}, W^{\text{br}}, W^{\text{bl}} \in \mathbb{R}^{(H/A)\times2D^s}$
: attention head별로 구한 embedding은 공유됩니다. $A$가 attention head의 개수입니다.
5) 이렇게 얻은 poistion embedding을 더하여 attention을 수행한다.
: $a^h_{i,j} = \left ( W^q_ht_i \right )^{\top}\left ( W^k_ht_j \right ) + \left ( W^q_ht_i \right )^{\top} \overline{bb}_{i,j}$
: 기존 self-attention은 position encoding을 더한 input vector를 사용한 것과 달리, BROS에서는 attention 시 positional embedding을 추가해주는 것으로 이해할 수 있습니다.
3.2. Area-masked Language Model

BROS는 두 개의 pre-training objective를 갖고 있습니다.
하나는 BERT에서 사용되었던 token-masked LM (TMLM)이고, 나머지는 여기서 새롭게 제시하는 area-masked LM (AMLM)입니다.
위 이미지에서는 (a)가 TMLM, (b)가 AMLM에 해당합니다.
TMLM에 해당하는 내용은 BERT 논문에 자세히 설명되어 있으니 크게 언급하지 않겠습니다.
원래 MLM(Masked Language Modeling)이라고 칭할텐데 왜 TMLM인지는 모르겠습니다.
(BERT 논문 링크: https://arxiv.org/abs/1810.04805)
AMLM은 TMLM과 달리 텍스트 블록을 무작위로 고른뒤 이를 기준으로 영역을 확장하여 영역 내 존재하는 모든 text block에 대해 masking 합니다.
이미지의 빨간색 표시가 (a)에서는 token, (b)에서는 area 임을 알 수 있습니다.
(b)에서는 area가 먼저 선택되고, 그 영역 내에 존재하는 text block 전체를 masking 해버립니다.
파란색 박스는 mask 토큰을 포함하는 text block을 의미합니다.
(a)는 token 단위로 masking을 했기 때문에 text block(파란색) 내에 masking 되지 않은 토큰이 존재하는 반면,
(b)는 block 단위로 masking을 하기 때문에 text block(파란색)과 masked token(회색)이 정확히 일치하는 것을 알 수 있습니다.
논문에서 제시하는 AMLM의 정확한 과정은 다음과 같습니다.
1) text block을 random하게 고른다.
2) text block의 영역을 확장하여 area를 정한다.
: 영역을 확장하는 정도는 exponential distribution으로부터 sampling한 값으로 결정된다고 합니다. 이 내용이 SpanBERT에 착안한 것이라고 하니 관심있는 분들은 논문(https://arxiv.org/abs/1907.10529)을 참고해보셔도 좋을 것 같습니다.
3) area 내의 text blocks를 확인한다.
4) text blocks의 모든 토큰을 masking하고 그것이 원래 무엇이었는지 예측한다.
4. Key Information Extraction Tasks
KIE tasks 중에서 entity extraction (EE), entity linking (EL), 두 개의 task를 다룹니다.
EE는 아래 그림에서 (a)에 해당하고, EL은 (b)에 해당합니다.

EE는 header, question, answer의 entity를 식별하는 것이라면, EL은 hierarchical 또는 semantic 관계를 예측하는 태스크입니다.
위 예시에서는 메뉴와 관련된 이름, unit당 가격, 개수, 총가격 등을 묶어주고 있습니다.
이와 관련된 KIE 벤치마크로 사용하는 것은 FUNSD, SROIE, CORD, SciTSR, 네 가지입니다.
흥미로운 것은 serializer의 한계(문서 종류가 다양해서 제대로 된 걸 쓰기가 어렵다)를 극복했는지 확인하기 위해, 사전에 제공된 텍스트 순서 정보를 제외한 실험 결과도 본 논문에서 제시한다는 점입니다.
5. Experiments
실험 세팅에 관해서는 자세한 내용이 논문에 제시되어 있으니 참고바랍니다.
핵심 내용만 간단히 정리하면 다음과 같습니다.
- OCR은 CLOVA OCR API를 이용
- positional encoding을 위한 sinusoid 함수의 embedding $D^S$는 24(base)/32(large) 차원
- BROS에 존재하는 transformer 아키텍쳐는 BERT를 그대로 따라 self-attention head 개수, hidden dimension 등을 유지
5.1. With the Order Information of Text Blocks
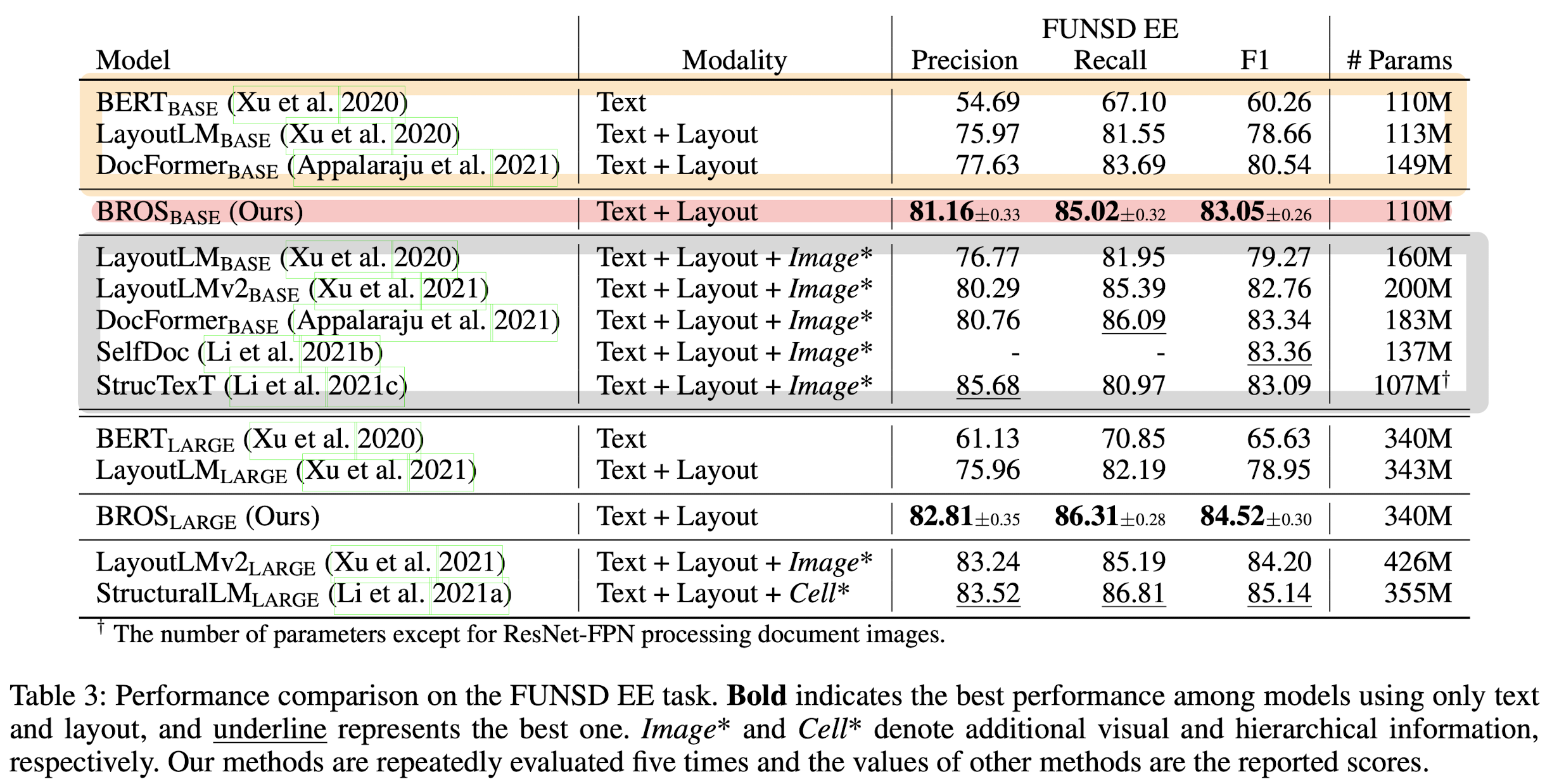
위 실험 결과(FUNSD 벤치마크의 EE 태스크)에서 저자가 강조하고 싶은 내용이 잘 드러나는 것 같습니다.
Text + Layout 만을 활용한 모델 중에서는 단연 압도적인 성능을 보입니다.
그런데 이 성능은 visual feature까지 활용하는 모델들과 비교했을 때도 꿀리지 않는 수준입니다.
실제로 회색 박스 안에 표시된 모델들의 사이즈보다 (상대적으로) 꽤 작다는 것을 알 수 있습니다.
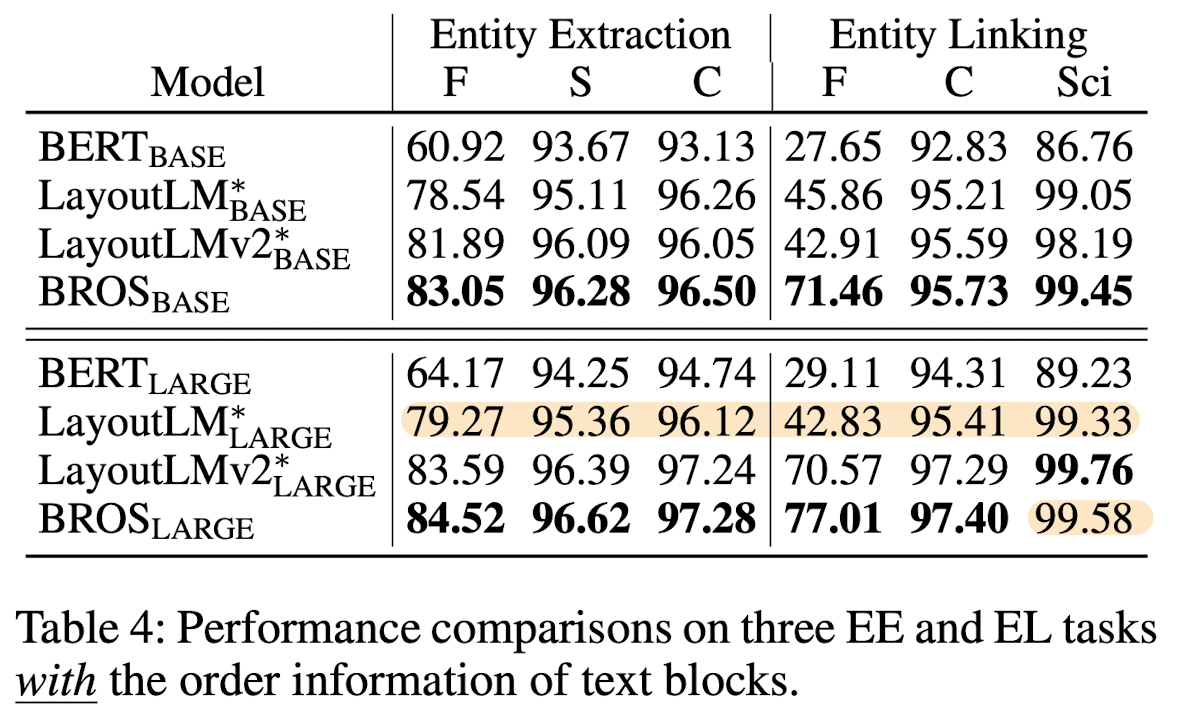
F, S, C, Sci는 차례로 FUNSD, SROIE, CORD, SciTSR 벤치마크를 의미합니다.
BROS 모델이 SciTSR을 제외하고는 최고의 성능을 보인다는 것이 쉽게 확인됩니다.
1D space에서의 텍스트를 다룬 BERT에 비해서는 말할 것도 없고,
2D space에서의 텍스트를 다루었으나 absolution position 정보를 사용한 LayoutLM보다도 뛰어납니다.
저자가 강조한 포인트 중 하나는 BROS large 모델의 사이즈가 LayoutLM large보다 3배 정도 작다는 것입니다.
5.2. Without the Order Information of Text Blocks
실제 사람이 읽는 것처럼 좌상단 → 우하단 순서로 텍스트 블록을 읽어준 정보가 없다면 어떻게 될지에 대한 실험입니다.
serializer 성능에 얼마나 independent한지를 입증하는 실험으로 이해할 수 있습니다.
텍스트 순서를 섞었다(permuate)는 것을 표현하기 위해 p- 로 표시했습니다.
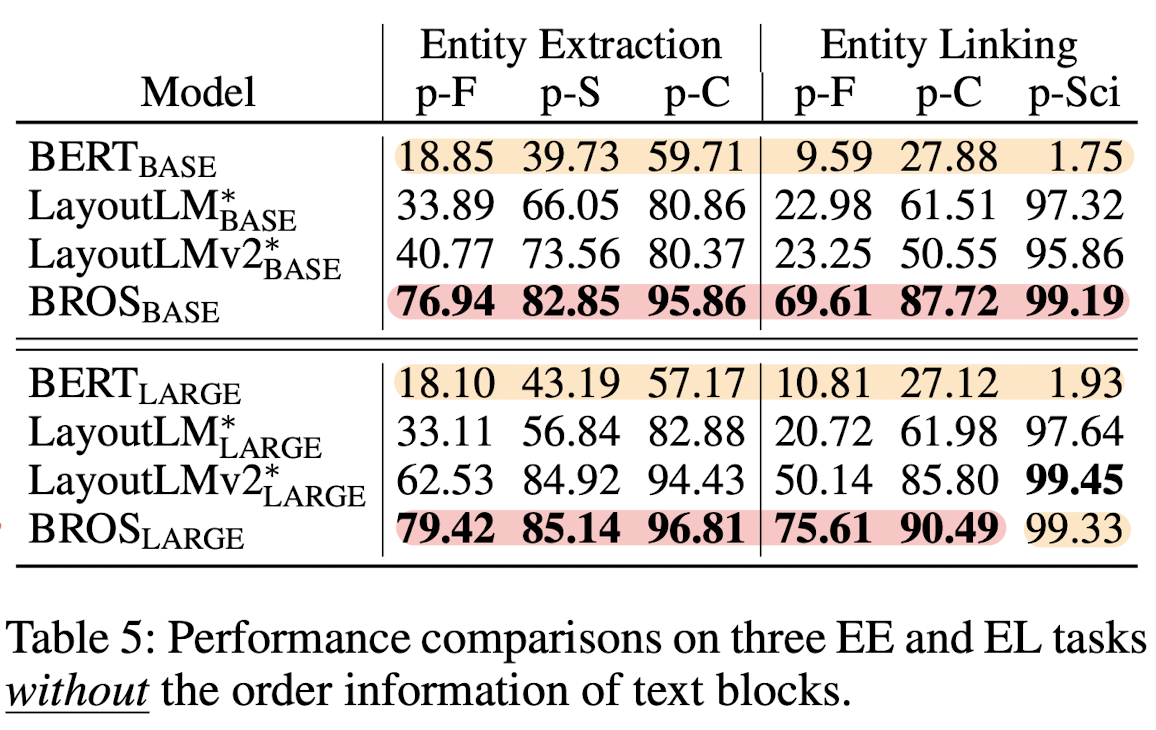
BROS가 뛰어난 성능을 보이고 있습니다.
그러나 주목할만한 포인트는 텍스트의 순서를 섞더라도 BERT, LayoutLM, LayoutLMv2 대비 성능 하락폭이 크지 않다는 점입니다.
텍스트 블록 간의 순서를 섞지 않았을 때와 비교하면 영향을 정말 적게 받았다는 걸 알 수 있습니다.
하지만 여기서도 SciTSR에서는 best 성능을 기록하지 못하고 있습니다.
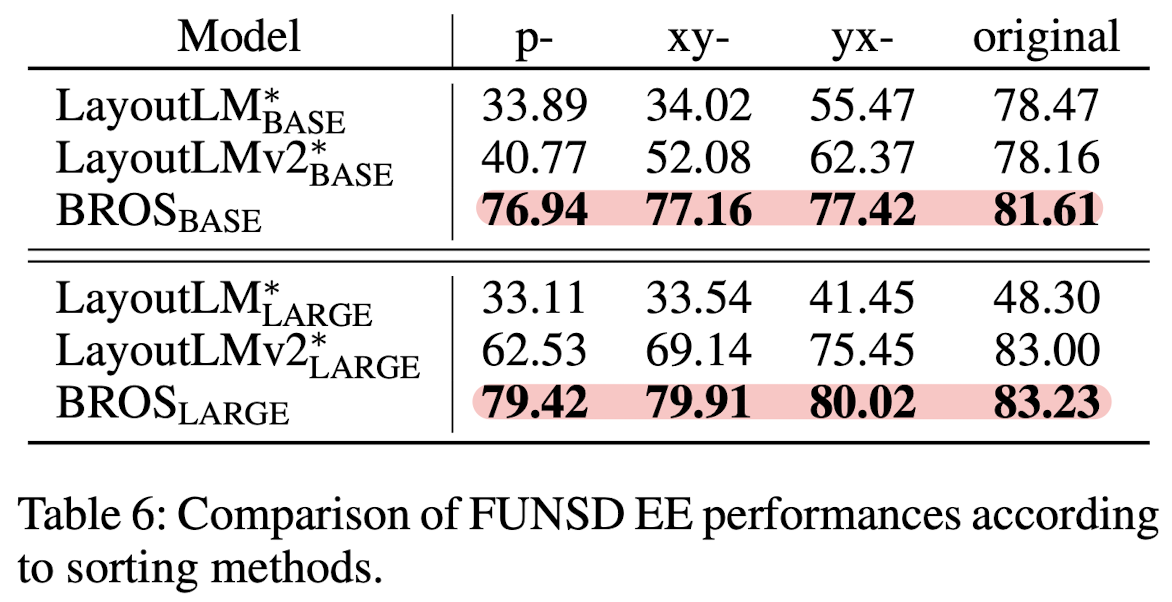
텍스트 순서에 관한 추가 실험 결과입니다.
단순히 permuate 했을 때, 그리고 xy축 순서, yx축 순서로 정렬했을 때의 결과를 순서가 올바를 때(original)과 비교했습니다.
확실히 타 모델 대비 텍스트 순서에 대해 robust 하다는 점이 눈에 띕니다.
5.3. Learning from Few Training Examples
결국 BROS도 사전학습 모델이므로 이를 downstream task에 적용할 때는 fine-tuning을 해야합니다.
이때 사용되는 데이터의 양이 적으면서도 뛰어난 성능을 보일 수 있다면 좋을 것입니다. (efficient)
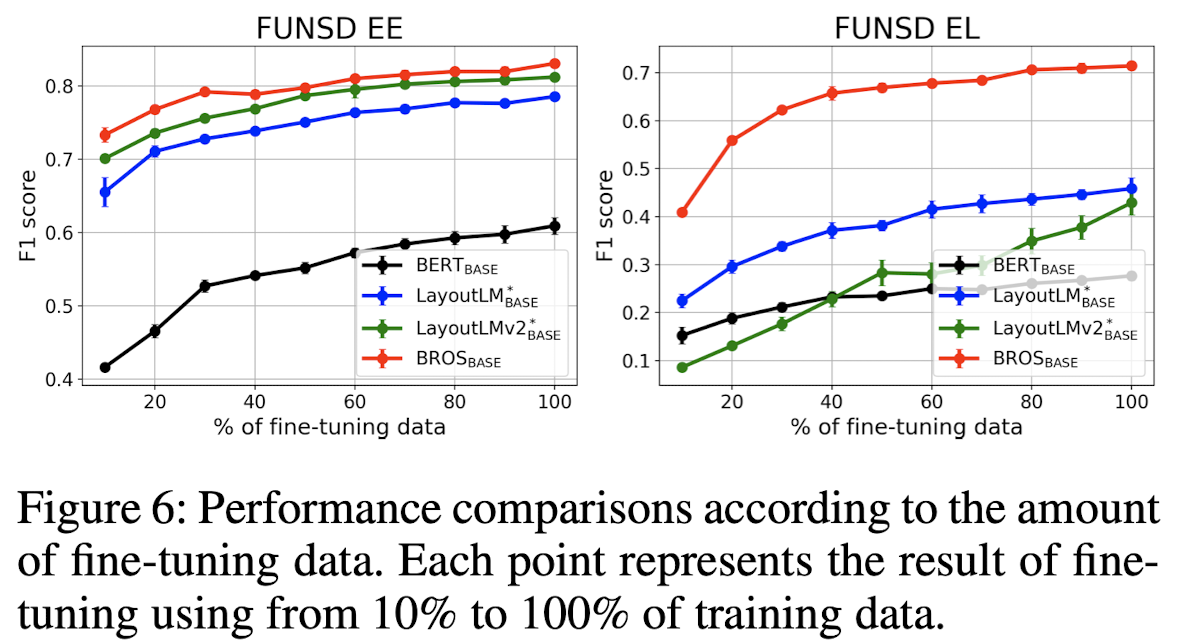
x축은 FUNSD 벤치마크를 기준으로 EE, EL 태스크를 수행할 때, 학습에 사용된 데이터의 양을 표시하고 있습니다.
둘 다 학습 데이터의 양이 증가할수록 성능이 향상되는 것을 볼 수 있습니다.
적은 데이터를 사용하더라도 높은 성능을 달성할 수 있다는 점이 눈에 띕니다.

아주 극단적인 상황을 제시한 결과입니다.
5개 또는 10개의 데이터를 가지고 100 epoch을 학습했을 때 결과를 보여주고 있습니다.
Figure 6과 비교하면 zero-shot(추가 학습을 전혀 진행하지 않았을 때, 0%) 성능과 다르지 않은 것 같은데,
뭘 보여주려고 한 것인지는 잘 모르겠습니다.
5.4. Ablation Study
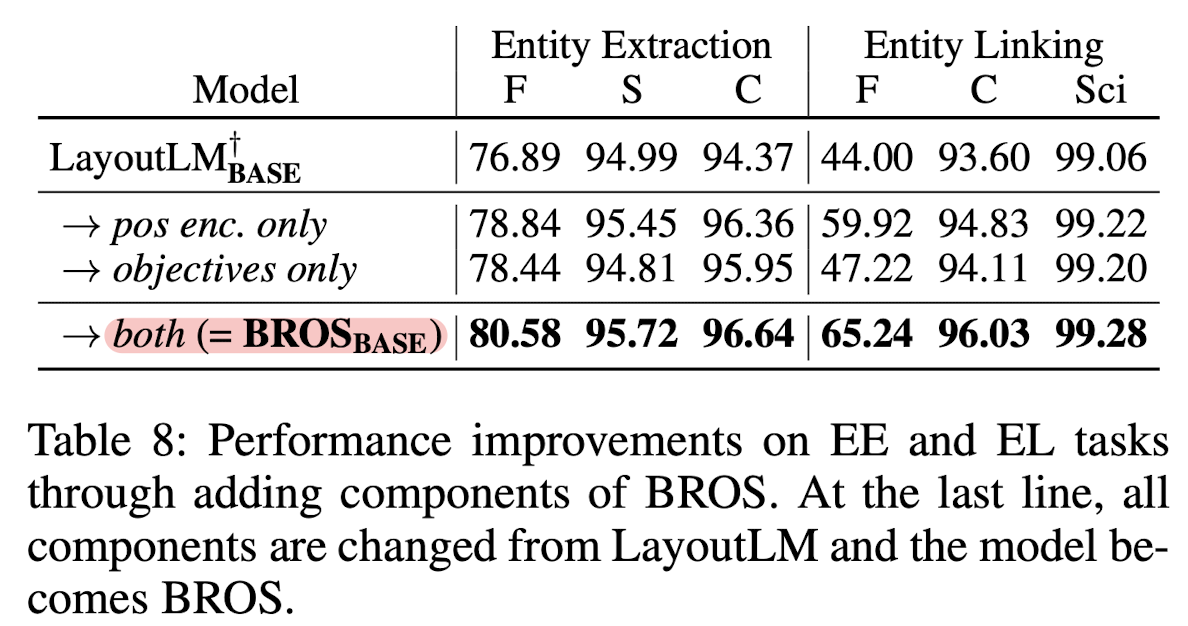
BROS에서 제시하는 두 가지 특징, positional encoding과 AMLM이 의미있는 방식인지를 검증하는 ablation study입니다.
LayoutLM 모델을 baseline으로 두고 각 방식을 적용했을 때 성능이 향상되는 것을 알 수 있습니다.
그리고 이를 개별적으로 적용했을 때보다 함께 적용하는 것이 더욱 효과적입니다.
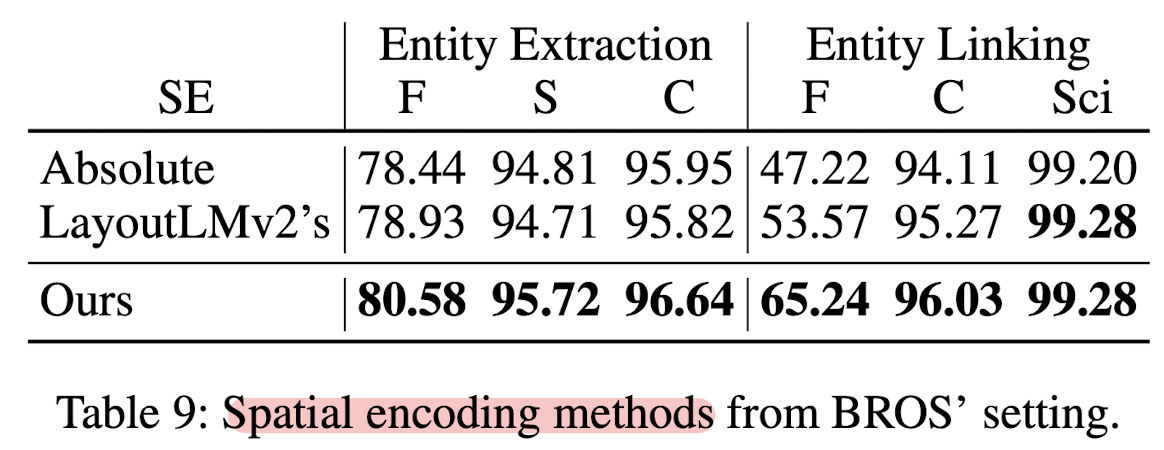
세 개의 positional encoding을 비교하고 있습니다.
LayoutLM에 나타난 absolute position, LayoutLMv2에 나타난 relative position, 그리고 BROS의 relative position입니다.
relative position을 사용하면 Entity Linking 성능이 abosute position 대비 크게 향상됩니다.
6. Conclusion
본 논문에서는 문서 이미지에 나타난 text와 layout 특징을 효과적으로 학습한 "언어 모델", BROS를 제시했습니다.
여기에 활용된 핵심 방법론은 두 가지입니다.
- 2D space 정보를 relative position 기반으로 encoding
- area-masking이라는 사전학습 기법을 사용
이를 적용한 BROS는 다음과 같은 장점이 있습니다.
- visual feature를 이용하지 않고도 이에 준하는 성능을 낼 수 있습니다.
- 이미지에 대해 추가적인 처리가 필요하지 않은 간단한 구조입니다.
- 현실에서 마주할 수 있는 두 가지 상황에 대응이 잘 됩니다.
- text serializer가 제대로 동작하기 어려운 경우
- 학습 sample의 수가 부족한 경우
이에 대해 개인적으로 들었던 의문이나 생각을 정리해보면 이렇습니다.
아직 관련 분야에 대한 이해와 지식이 부족해 잘못 생각한 것일 수 있으니 가감 없이 말씀해주시면 감사하겠습니다.
- 특정 시점에서 활용 가능한 자원을 고려하여 모델의 규모를 축소하는 것은 좋아 보입니다.
하지만 그것이 높은 정확도와 trade-off 가능한 요소인지는 판단하기 어려운 것 같습니다.- 물론 실제 서비스나 제품으로 판매되는 상황을 고려한다면 작을수록 좋은 것은 사실입니다.
그런데 100MB ~ 300MB 사이즈에서의 고민은 현재 기업들이 활용 가능한 컴퓨팅 자원을 감안했을 때 큰 문제가 되지 않는 것처럼 느껴졌습니다. - 이를 여러 개 활용해야 하는 상황에서는 약간의 차이가 있겠지만..
일반적으로는 "효율보다 성능"에 focus를 두고 있는 경우가 훨씬 많은 것 같다고 느껴집니다.
- 물론 실제 서비스나 제품으로 판매되는 상황을 고려한다면 작을수록 좋은 것은 사실입니다.
- scalable한 방식이 맞을까? & Serializer가 오히려 중요하지 않을까?
- 이어서 생각해보면 결국 visual feature를 활용하지 않는 것이 독이 되는 것 같습니다.
최근 인공지능 모델들의 발전 방향을 보더라도 multi-modal이 추세인 점을 떠올리면 더욱 그런 생각이 듭니다. - 물론 visual feature가 추가되는 경우 이미지 특성에 지나치게 민감하게 반응하여 성능이 저하되는 경우가 있을 수 있지만,
text-only 접근은 장기적인 관점에서 임시 방편.. 혹은 굉장히 한정적인 분야에만 활용 가능한 방식이 아닐까 싶었습니다. - 한편 serializer가 진짜 중요할 거라는 생각이 들었습니다. 텍스트의 순서에 상관 없이 모델이 예측할 수 있다는 것이 장점이기도 하지만 그런 접근으로는 '텍스트나 구조를 더 잘 이해'하게 만드는 아이디어가 딱히 떠오르는 것 같지는 않습니다.
대신 텍스트를 구조에 입각하여 기가 막히게 읽어주는 방식을 더 알아보는 게 의미가 있을 수도 있겠다 싶습니다. - 텍스트를 올바른 순서로 읽어주는 것은 visual feature를 고려하든 고려하지 않든 중요한 요소라는 생각이 오히려 더 들게 되었습니다. (특히 'text + layout'으로만 처리를 할 것이라면..)
- 이어서 생각해보면 결국 visual feature를 활용하지 않는 것이 독이 되는 것 같습니다.
- absolute position을 같이 활용하는 방식은 없을까?
- 우선 아쉬운 점을 생각해보면 LayoutLMv2에서의 relative position과 어떤 차이점이 있는지 밝히지 않았다는 것입니다.
텍스트(블록) 간의 어떤 관계를 파악하는 데 있어서 상대적 위치 개념이 유효할 것이라는 것은 직관적으로 납득이 되는 내용이긴 합니다만 LayoutLMv2와의 비교 설명이 불충분했던 것 같습니다. - 어쨌든 상대적 위치를 쓰게 된 이유가 문서 이미지의 크기가 다양할 수 있다는 문제점 때문인데, 오히려 그걸 특징으로 생각하고 절대적 위치와 상대적 위치를 함께 고려하도록 만드는 방식을 생각할 수도 있지 않을까 싶은 생각도 듭니다.
- 우선 아쉬운 점을 생각해보면 LayoutLMv2에서의 relative position과 어떤 차이점이 있는지 밝히지 않았다는 것입니다.
'Paper Review' 카테고리의 다른 글
관심 있는 고전(?) 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Naver Clova, KAIST, LBox, Upstage]
- Key information extraction (KIE) 태스크를 잘 처리하기 위해 text와 layout을 효과적으로 결합하는 방식을 고안
- BROS (BERT Relying On Spatiality): text를 2D 공간에서 relative position encoding 하고 area-masking strategy를 적용
- 현실 세계에서 다루기 어려운 두 가지의 문제(incorrect text ordering, fewer downstream examples)에도 강건함을 보임
출처 : https://arxiv.org/abs/2108.04539
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combin
arxiv.org
1. Introduction
영수증과같은 문서 이미지에서 특정 정보를 추출해내는, KIE 태스크를 처리하기 위한 다양한 시도들이 존재했습니다.
여기서는 문서 이미지의 특성을 고려하여 다양한 'layout'을 모델이 이해할 수 있도록 만드는 것이 중요하게 여겨집니다.
흐름을 간단히 도식화한 이미지는 다음과 같습니다.
문서 이미지에 대해 OCR을 적용하고, 인식한 글자를 serializer로 읽어줍니다.
보통 좌상단 → 우하단 순서로 읽습니다.
그 결과를 Parsing Model에 입력하여 key information을 획득합니다.
여기서 문제가 되는 것 중 하나는 Serializer입니다.
정확도가 높으면서도 가져다 쓰기 쉬운 tool이 많은 OCR과 달리, 형태가 수도 없이 다양하게 존재하는 문서들의 읽는 순서를 결정해줄 수 있는 범용성 좋은 Serializer는 존재하지 않기 때문입니다.
(지금도 이것이 큰 문제로 여겨집니다)
또한 어떻게 잘 텍스트를 읽어냈다고 하더라도, 문서라는 2D 공간에 존재하는 텍스트를 1D로 처리하는 것 자체가 곧 정보의 손실이라고 볼 수 있습니다.
그래서 이와 같은 방식으로 KIE를 처리하던 BERT 대신에 (BERT는 1D positional encoding을 사용)
layout 정보를 다룰 수 있도록 만든 LayoutLM이 히트를 치게 됩니다.
LayoutLM의 등장 이후로는 text, layout 정보에 더해 visual feature를 얹어 모델의 성능을 높이고자 하는 시도가 많았습니다.
그러나 visual feature가 더해져 추가적인 연산 비용이 요구된다는 것은 자명한 사실이죠.
이러한 배경에서 본 논문은 BROS라는 모델을 제시하는데 다음 두 가지가 중요한 특징입니다.
- visual feature에 의존하지 않는다. 오직 text와 layout으로 승부를 본다.
- 여기에 정교한 spatial encoding 기법을 활용한다.
- area-masked language model을 제시한다.
- MLM과 동시에 사용한다. AMLM은 SpanBERT에서 영감을 받았다.
2. Related Work
2.3.1. Pre-trained Language Models for 2D Text Blocks
- 위에서 언급했던 것처럼 BERT 대신 LayoutLM 모델이 KIE에서 선풍적인 인기를 끌게 됩니다.
- 여기서는 layout 정보를 반영하기 위해 absolute position을 사용합니다.
- 이후에는 visual feature를 통합하기 위한 노력이 이어집니다.
- 그러나 raw document image를 처리하기 위한 추가적인 연산이 필요하게 되었습니다.
- StructuralLM 모델은 cell information(a group of ordered text blocks)을 사용했습니다.
- 그러나 KIE 태스크를 위해 OCR을 적용하게 되면 text block 간의 local order는 획득할 수 없어 일반적으로 적용 가능한 방법론이 아닙니다.
2.3.2. Parsers for Document Key Information Extraction
- entity extraction의 대표 중 하나는 BIO tagger입니다.
- 그러나 정보를 추출하기 위해서는 text block 간의 정확한 순서 정보가 요구된다는 것이 문제입니다.
- 또한 token들 간의 관계 정보가 요구된다는 점도 문제로 볼 수 있습니다.
- 이를 해결하기 위해 graph-based parser, SPADE decoder를 사용합니다.
- 본 논문에서 실험하는 task 중에 'Entity Linking'에 적용합니다.
- SpaDE 논문 링크: https://arxiv.org/abs/2209.05917
3. BERT Relying on Spatiality (BROS)
BROS는 LayoutLM의 main structure를 따릅니다.
그러나 위에서 언급한 것처럼 텍스트와 관련된 2D 정보를 유지하기 위한 Encoding 기법,
그리고 사전학습 시 Area-masking 전략을 활용한 것을 차별점으로 두고 있습니다.
3.1. Encoding Spatial Information into BERT
Text와 함께 공간 정보를 encoding 하는 방법은 LayoutLM에서 이미 제시했다고 했습니다.
그러나 여기서는 텍스트 블록 간의 "relative position"을 이용합니다.
(LayoutLMv2도 relative position encoding을 사용한 것으로 알고 있으나 이는 언급되지 않았습니다)
기존 방식과 비교한 이미지는 다음과 같습니다.
저자는 (b) 방식을 이용하면 위치 정보를 표현하기 위해 필요한 co-modality를 유지할 수 있다고 주장합니다.
어쨌든 realtive position을 encoding하는 과정은 이렇습니다.
1) 비교하고자 하는 두 텍스트 블록
2) 각 텍스트 블록의
: 이때 좌표값은 이미지 사이즈를 기준으로 noramlized 된 값을 사용합니다.
:
3) 두 블록 간의
(좌상단, 우상단, 우하단, 좌하단, 총 네 개의 벡터가 생김)
:
:
4) 각 벡터에 linear transition matrix를 곱하고 그 결과를 더한다.
:
:
: attention head별로 구한 embedding은 공유됩니다.
5) 이렇게 얻은 poistion embedding을 더하여 attention을 수행한다.
:
: 기존 self-attention은 position encoding을 더한 input vector를 사용한 것과 달리, BROS에서는 attention 시 positional embedding을 추가해주는 것으로 이해할 수 있습니다.
3.2. Area-masked Language Model
BROS는 두 개의 pre-training objective를 갖고 있습니다.
하나는 BERT에서 사용되었던 token-masked LM (TMLM)이고, 나머지는 여기서 새롭게 제시하는 area-masked LM (AMLM)입니다.
위 이미지에서는 (a)가 TMLM, (b)가 AMLM에 해당합니다.
TMLM에 해당하는 내용은 BERT 논문에 자세히 설명되어 있으니 크게 언급하지 않겠습니다.
원래 MLM(Masked Language Modeling)이라고 칭할텐데 왜 TMLM인지는 모르겠습니다.
(BERT 논문 링크: https://arxiv.org/abs/1810.04805)
AMLM은 TMLM과 달리 텍스트 블록을 무작위로 고른뒤 이를 기준으로 영역을 확장하여 영역 내 존재하는 모든 text block에 대해 masking 합니다.
이미지의 빨간색 표시가 (a)에서는 token, (b)에서는 area 임을 알 수 있습니다.
(b)에서는 area가 먼저 선택되고, 그 영역 내에 존재하는 text block 전체를 masking 해버립니다.
파란색 박스는 mask 토큰을 포함하는 text block을 의미합니다.
(a)는 token 단위로 masking을 했기 때문에 text block(파란색) 내에 masking 되지 않은 토큰이 존재하는 반면,
(b)는 block 단위로 masking을 하기 때문에 text block(파란색)과 masked token(회색)이 정확히 일치하는 것을 알 수 있습니다.
논문에서 제시하는 AMLM의 정확한 과정은 다음과 같습니다.
1) text block을 random하게 고른다.
2) text block의 영역을 확장하여 area를 정한다.
: 영역을 확장하는 정도는 exponential distribution으로부터 sampling한 값으로 결정된다고 합니다. 이 내용이 SpanBERT에 착안한 것이라고 하니 관심있는 분들은 논문(https://arxiv.org/abs/1907.10529)을 참고해보셔도 좋을 것 같습니다.
3) area 내의 text blocks를 확인한다.
4) text blocks의 모든 토큰을 masking하고 그것이 원래 무엇이었는지 예측한다.
4. Key Information Extraction Tasks
KIE tasks 중에서 entity extraction (EE), entity linking (EL), 두 개의 task를 다룹니다.
EE는 아래 그림에서 (a)에 해당하고, EL은 (b)에 해당합니다.
EE는 header, question, answer의 entity를 식별하는 것이라면, EL은 hierarchical 또는 semantic 관계를 예측하는 태스크입니다.
위 예시에서는 메뉴와 관련된 이름, unit당 가격, 개수, 총가격 등을 묶어주고 있습니다.
이와 관련된 KIE 벤치마크로 사용하는 것은 FUNSD, SROIE, CORD, SciTSR, 네 가지입니다.
흥미로운 것은 serializer의 한계(문서 종류가 다양해서 제대로 된 걸 쓰기가 어렵다)를 극복했는지 확인하기 위해, 사전에 제공된 텍스트 순서 정보를 제외한 실험 결과도 본 논문에서 제시한다는 점입니다.
5. Experiments
실험 세팅에 관해서는 자세한 내용이 논문에 제시되어 있으니 참고바랍니다.
핵심 내용만 간단히 정리하면 다음과 같습니다.
- OCR은 CLOVA OCR API를 이용
- positional encoding을 위한 sinusoid 함수의 embedding
- BROS에 존재하는 transformer 아키텍쳐는 BERT를 그대로 따라 self-attention head 개수, hidden dimension 등을 유지
5.1. With the Order Information of Text Blocks
위 실험 결과(FUNSD 벤치마크의 EE 태스크)에서 저자가 강조하고 싶은 내용이 잘 드러나는 것 같습니다.
Text + Layout 만을 활용한 모델 중에서는 단연 압도적인 성능을 보입니다.
그런데 이 성능은 visual feature까지 활용하는 모델들과 비교했을 때도 꿀리지 않는 수준입니다.
실제로 회색 박스 안에 표시된 모델들의 사이즈보다 (상대적으로) 꽤 작다는 것을 알 수 있습니다.
F, S, C, Sci는 차례로 FUNSD, SROIE, CORD, SciTSR 벤치마크를 의미합니다.
BROS 모델이 SciTSR을 제외하고는 최고의 성능을 보인다는 것이 쉽게 확인됩니다.
1D space에서의 텍스트를 다룬 BERT에 비해서는 말할 것도 없고,
2D space에서의 텍스트를 다루었으나 absolution position 정보를 사용한 LayoutLM보다도 뛰어납니다.
저자가 강조한 포인트 중 하나는 BROS large 모델의 사이즈가 LayoutLM large보다 3배 정도 작다는 것입니다.
5.2. Without the Order Information of Text Blocks
실제 사람이 읽는 것처럼 좌상단 → 우하단 순서로 텍스트 블록을 읽어준 정보가 없다면 어떻게 될지에 대한 실험입니다.
serializer 성능에 얼마나 independent한지를 입증하는 실험으로 이해할 수 있습니다.
텍스트 순서를 섞었다(permuate)는 것을 표현하기 위해 p- 로 표시했습니다.
BROS가 뛰어난 성능을 보이고 있습니다.
그러나 주목할만한 포인트는 텍스트의 순서를 섞더라도 BERT, LayoutLM, LayoutLMv2 대비 성능 하락폭이 크지 않다는 점입니다.
텍스트 블록 간의 순서를 섞지 않았을 때와 비교하면 영향을 정말 적게 받았다는 걸 알 수 있습니다.
하지만 여기서도 SciTSR에서는 best 성능을 기록하지 못하고 있습니다.
텍스트 순서에 관한 추가 실험 결과입니다.
단순히 permuate 했을 때, 그리고 xy축 순서, yx축 순서로 정렬했을 때의 결과를 순서가 올바를 때(original)과 비교했습니다.
확실히 타 모델 대비 텍스트 순서에 대해 robust 하다는 점이 눈에 띕니다.
5.3. Learning from Few Training Examples
결국 BROS도 사전학습 모델이므로 이를 downstream task에 적용할 때는 fine-tuning을 해야합니다.
이때 사용되는 데이터의 양이 적으면서도 뛰어난 성능을 보일 수 있다면 좋을 것입니다. (efficient)
x축은 FUNSD 벤치마크를 기준으로 EE, EL 태스크를 수행할 때, 학습에 사용된 데이터의 양을 표시하고 있습니다.
둘 다 학습 데이터의 양이 증가할수록 성능이 향상되는 것을 볼 수 있습니다.
적은 데이터를 사용하더라도 높은 성능을 달성할 수 있다는 점이 눈에 띕니다.
아주 극단적인 상황을 제시한 결과입니다.
5개 또는 10개의 데이터를 가지고 100 epoch을 학습했을 때 결과를 보여주고 있습니다.
Figure 6과 비교하면 zero-shot(추가 학습을 전혀 진행하지 않았을 때, 0%) 성능과 다르지 않은 것 같은데,
뭘 보여주려고 한 것인지는 잘 모르겠습니다.
5.4. Ablation Study
BROS에서 제시하는 두 가지 특징, positional encoding과 AMLM이 의미있는 방식인지를 검증하는 ablation study입니다.
LayoutLM 모델을 baseline으로 두고 각 방식을 적용했을 때 성능이 향상되는 것을 알 수 있습니다.
그리고 이를 개별적으로 적용했을 때보다 함께 적용하는 것이 더욱 효과적입니다.
세 개의 positional encoding을 비교하고 있습니다.
LayoutLM에 나타난 absolute position, LayoutLMv2에 나타난 relative position, 그리고 BROS의 relative position입니다.
relative position을 사용하면 Entity Linking 성능이 abosute position 대비 크게 향상됩니다.
6. Conclusion
본 논문에서는 문서 이미지에 나타난 text와 layout 특징을 효과적으로 학습한 "언어 모델", BROS를 제시했습니다.
여기에 활용된 핵심 방법론은 두 가지입니다.
- 2D space 정보를 relative position 기반으로 encoding
- area-masking이라는 사전학습 기법을 사용
이를 적용한 BROS는 다음과 같은 장점이 있습니다.
- visual feature를 이용하지 않고도 이에 준하는 성능을 낼 수 있습니다.
- 이미지에 대해 추가적인 처리가 필요하지 않은 간단한 구조입니다.
- 현실에서 마주할 수 있는 두 가지 상황에 대응이 잘 됩니다.
- text serializer가 제대로 동작하기 어려운 경우
- 학습 sample의 수가 부족한 경우
이에 대해 개인적으로 들었던 의문이나 생각을 정리해보면 이렇습니다.
아직 관련 분야에 대한 이해와 지식이 부족해 잘못 생각한 것일 수 있으니 가감 없이 말씀해주시면 감사하겠습니다.
- 특정 시점에서 활용 가능한 자원을 고려하여 모델의 규모를 축소하는 것은 좋아 보입니다.
하지만 그것이 높은 정확도와 trade-off 가능한 요소인지는 판단하기 어려운 것 같습니다.- 물론 실제 서비스나 제품으로 판매되는 상황을 고려한다면 작을수록 좋은 것은 사실입니다.
그런데 100MB ~ 300MB 사이즈에서의 고민은 현재 기업들이 활용 가능한 컴퓨팅 자원을 감안했을 때 큰 문제가 되지 않는 것처럼 느껴졌습니다. - 이를 여러 개 활용해야 하는 상황에서는 약간의 차이가 있겠지만..
일반적으로는 "효율보다 성능"에 focus를 두고 있는 경우가 훨씬 많은 것 같다고 느껴집니다.
- 물론 실제 서비스나 제품으로 판매되는 상황을 고려한다면 작을수록 좋은 것은 사실입니다.
- scalable한 방식이 맞을까? & Serializer가 오히려 중요하지 않을까?
- 이어서 생각해보면 결국 visual feature를 활용하지 않는 것이 독이 되는 것 같습니다.
최근 인공지능 모델들의 발전 방향을 보더라도 multi-modal이 추세인 점을 떠올리면 더욱 그런 생각이 듭니다. - 물론 visual feature가 추가되는 경우 이미지 특성에 지나치게 민감하게 반응하여 성능이 저하되는 경우가 있을 수 있지만,
text-only 접근은 장기적인 관점에서 임시 방편.. 혹은 굉장히 한정적인 분야에만 활용 가능한 방식이 아닐까 싶었습니다. - 한편 serializer가 진짜 중요할 거라는 생각이 들었습니다. 텍스트의 순서에 상관 없이 모델이 예측할 수 있다는 것이 장점이기도 하지만 그런 접근으로는 '텍스트나 구조를 더 잘 이해'하게 만드는 아이디어가 딱히 떠오르는 것 같지는 않습니다.
대신 텍스트를 구조에 입각하여 기가 막히게 읽어주는 방식을 더 알아보는 게 의미가 있을 수도 있겠다 싶습니다. - 텍스트를 올바른 순서로 읽어주는 것은 visual feature를 고려하든 고려하지 않든 중요한 요소라는 생각이 오히려 더 들게 되었습니다. (특히 'text + layout'으로만 처리를 할 것이라면..)
- 이어서 생각해보면 결국 visual feature를 활용하지 않는 것이 독이 되는 것 같습니다.
- absolute position을 같이 활용하는 방식은 없을까?
- 우선 아쉬운 점을 생각해보면 LayoutLMv2에서의 relative position과 어떤 차이점이 있는지 밝히지 않았다는 것입니다.
텍스트(블록) 간의 어떤 관계를 파악하는 데 있어서 상대적 위치 개념이 유효할 것이라는 것은 직관적으로 납득이 되는 내용이긴 합니다만 LayoutLMv2와의 비교 설명이 불충분했던 것 같습니다. - 어쨌든 상대적 위치를 쓰게 된 이유가 문서 이미지의 크기가 다양할 수 있다는 문제점 때문인데, 오히려 그걸 특징으로 생각하고 절대적 위치와 상대적 위치를 함께 고려하도록 만드는 방식을 생각할 수도 있지 않을까 싶은 생각도 듭니다.
- 우선 아쉬운 점을 생각해보면 LayoutLMv2에서의 relative position과 어떤 차이점이 있는지 밝히지 않았다는 것입니다.