
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Published as a main conference paper at EMNLP 2023. Code available at this URL
[University of Washington, AI2, Meta AI]
- long-form text generation의 factuality를 평가할 때, binary judgments(supported/unsupported) & huge cost of human evaluatoin 이슈가 존재
- 생성 결과를 일련의 atomic facts로 쪼갠 뒤 각 fact를 평가한 결과를 합쳐 score를 구하는 방식인 FActScore를 제안 (fine-grained score)
- InstructGPT, ChatGPT, PerplexityAI (retrieval augmented)와 오픈 소스 모델의 실험 결과를 비교
출처 : https://arxiv.org/abs/2305.14251
1. Introduction
LLM이 활발히 사용됨에 따라 모델의 생성 결과를 평가하는 것도 자연스레 중요한 연구 분야가 되었습니다.
그러나 언어 모델이 생성한 결과의 factuality(hallucination이 아니라 사실인가?)를 확인하는 데는 두 가지 주요한 challenges가 있습니다.
1) 언어 모델의 생성물에 너무 많은 정보가 담겨 있을 수 있습니다.
LLM 챗봇 서비스를 이용해보신 분들은 잘 아시겠지만.. 보통의 LLM들은 굉장한 수다쟁이입니다.
최소 한 문단 이상의 출력을 뿜어내는 것이 일반적인데, 여기에 특정 fact/information만 담고 있을 가능성은 거의 없습니다.
출력 문장 길이에 비례하는 정보가 포함되어 있을 것이며 이들 각각 사실인지 아닌지 검증해야 되는 것이죠.
2) 검증해야 하는 정보의 양이 많으므로.. 자연스럽게 많은 시간과 비용이 발생합니다.
모델의 생성 결과를 여러 개의 작은 정보로 쪼개고 이를 검증하는 과정은 당연히 큰 비용을 초래하게 됩니다.
지금까지는 이런 과정을 사람이 할 수밖에 없는 구조였습니다.
그래서 본 논문에서는 "언어 모델의 생성 결과를 LLM(InstructGPT)을 활용하여 여러 개의 atomic facts로 분할하고,
각각에 대한 factuality를 검증한 결과를 Fact Score로 반환하는 데 언어 모델을 활용하는 방법"을 제안합니다.
(factuality 검증은 binary하게 이뤄집니다)
누구나 잘 아는 사실이긴 하지만..
이런 작업도 오픈소스 모델보다는 기업들의 proprietary 모델들이 훨씬 잘합니다 😅 (그저 GPT-4..)
2. Related Work
관련 연구는 논문에서 여러가지를 확인할 수 있습니다.
본 포스팅에서는 저자가 기존의 연구와 다르게 가져간 특징들을 간단히 정리하겠습니다.
Factual precision in text generation
- 기존보다 훨씬 긴 길이의 text generation을 다룸
- human experts & automated evaluator 의 평가 결과를 둘 다 다룸
- 여러 개의 언어 모델에 적용
Fact Verification
- long-form model-generated text (rather than sentence-level human-written claims)
Model-based Evaluation
- 각 정보가 large text corpus에 의해 support 되는지 아닌지를 판단하는 방식을 채택
3. FActScore
Key idea 1: Atomic fact as a unit
이전에는 '한 문장'을 한 개의 단위로 파악했습니다.
그러나 한 개의 문장은 여러 정보를 담고 있을 수 있는데, 일례로 ChatGPT로 생성한 문장의 40%는 이러한 경우에 속합니다.
따라서 이러한 문제를 해결하기 위해 반드시 '한 개의 정보를 담고 있는 경우'만 한 개의 단위로 파악합니다.
Key idea 2: Factual precision as a function of a given knowledge source
atomic fact가 주어진 knowledge source에 의해 supported 되는지를 파악합니다.
이때 supported / unsupported 두 개의 선택지만 존재합니다.
Definition
FActScore를 구하는 식은 다음과 같이 정의됩니다.
$$f(y)= \frac{1}{\left | A_y\right |}\sum_{a\in A_y}\mathbb{I} \left [ a\; \text{is supported by }C\right ]$$
$$\text{FActScore}(M)= \mathbb{E}_{x\in \chi}\left[ f(M_x)|M_x\; \text{responds}\right ]$$
첫 번째 식의 해석은 이렇습니다.
우선 대괄호 [ ] 내부를 보면, 각 atomic fact $a$가 knowledge source (Wikipedia) $C$에 의해 supported 되는지 파악합니다.
$\mathbb{I}$에 의해 참이면 1, 아니면 0이 됩니다.
이를 response $y$에 대한 모든 atomic facts 를 담은 리스트 $A_y$에 대해 수행합니다.
그리고 그 값들을 모두 더한 뒤 리스트의 길이, 즉 atomic fact의 개수로 나눠줍니다.
이를 통해 $f(y)$는 모든 atomic facts가 supported 인 경우 1, 그렇지 않은 경우 0의 값을 갖게 됩니다.
두 번째 식은 위 과정을 각 프롬프트 $x$에 대해 적용한 기댓값을 구하는 것입니다.
프롬프트 $x$는 입력 프롬프트(biographies)를 모아 놓은 $\chi$의 원소입니다.
각 입력 $x$를 모델 $M$에 입력하여 얻는 response는 $y$가 됩니다.
결국 첫 번째 식에서 얻을 수 있는 0~1 사이의 값을 프롬프트별로 구하여 평균을 취한다는 뜻이 됩니다.
단, 전제는 $M_x$가 responds 했을 때, 즉 답변을 반환했을 때만을 고려한다는 점입니다.
논문에서 밝힌 이 정의의 주요한 전제들은 아래와 같이 정리됩니다.
1) atomic fact가 C에 의해 supported 되는지 아닌지에 대한 이견은 존재하지 않는다.
2) 하나의 response $y$에 대한 각 atomic fact는 동등한 비중을 차지한다. (중요도가 동일하다)
3) $C$의 각 정보는 상충하거나 중복되지 않는다.
4. Set-up
Studied LMs
세 개의 LM을 subject로서의 $\text{LM}_{\text{SUBJ}}$로 사용합니다.
- InstructGPT (text-davinci-003), ChatGPT, PerplexityAI (with search engine)
Data
$\text{LM}_{\text{SUBJ}}$가 people biographies를 생성하도록 프롬프팅하고 이를 Wikipedia를 근거로 평가합니다.
people biographies를 사용하는 이유는 다음과 같습니다.
- 객관적이고 구체적인 정보를 포함하고 있다.
- 다양한 특징(국적, 직업 등)을 기준으로 평가가 가능하다.
- Wikipedia는 충분한 양과 범위의 정보를 포함하고 있다.
데이터를 수집한 절차도 간단히 소개되어 있습니다.
1) Sampling people entities: 183명의 인물을 선정
2) Obtaining generations: "Tell me a bio of <entity>"
3) Atomic facts generation: generation을 일련의 atomic facts로 break into
4) Labeling factual precision & editing: human annotator들을 작업에 동원
5. Experiment
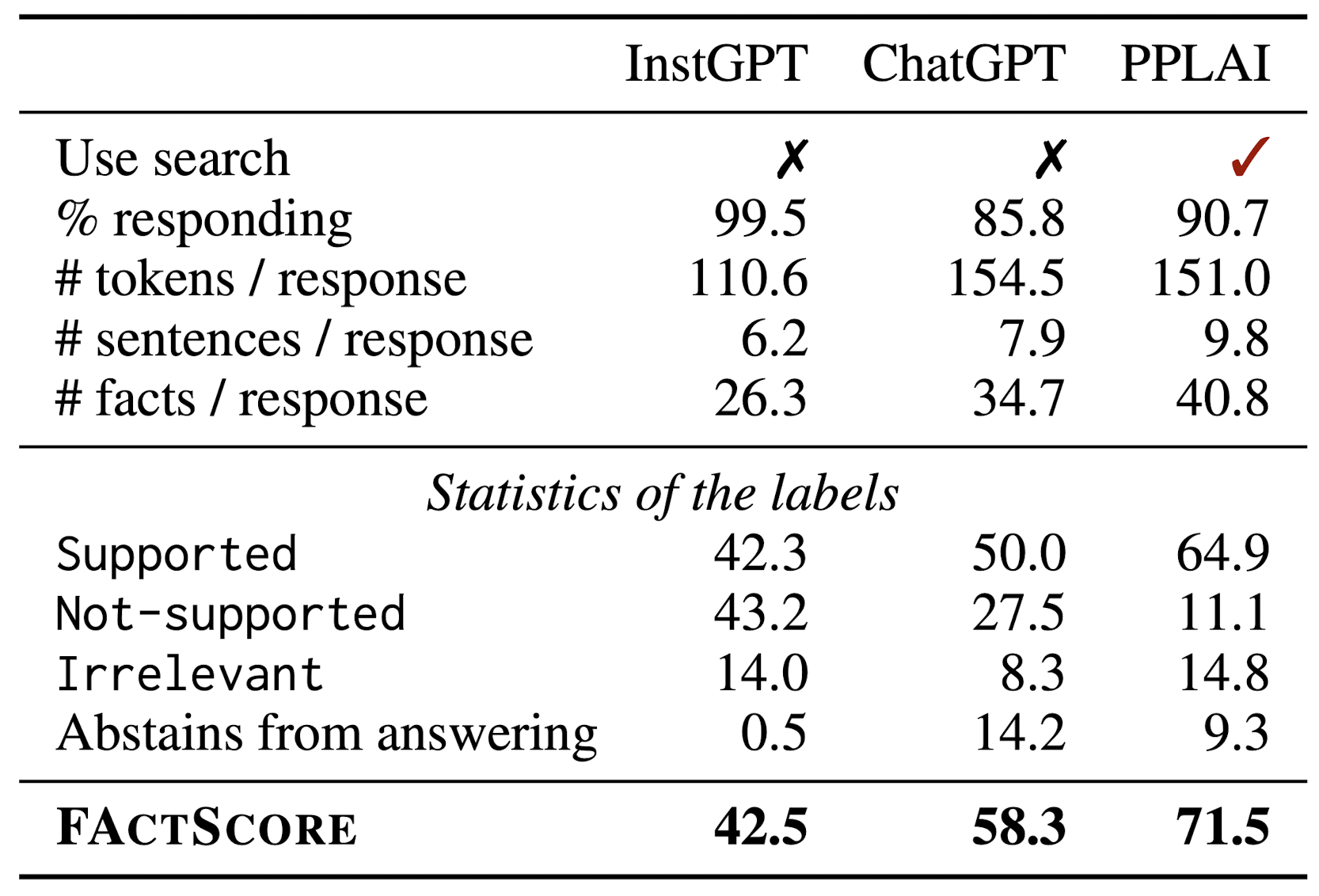
실험에 관한 내용들은 논문에 자세히 소개되어 있으니 저는 간단히 일부 내용만 짚고 넘어가겠습니다.
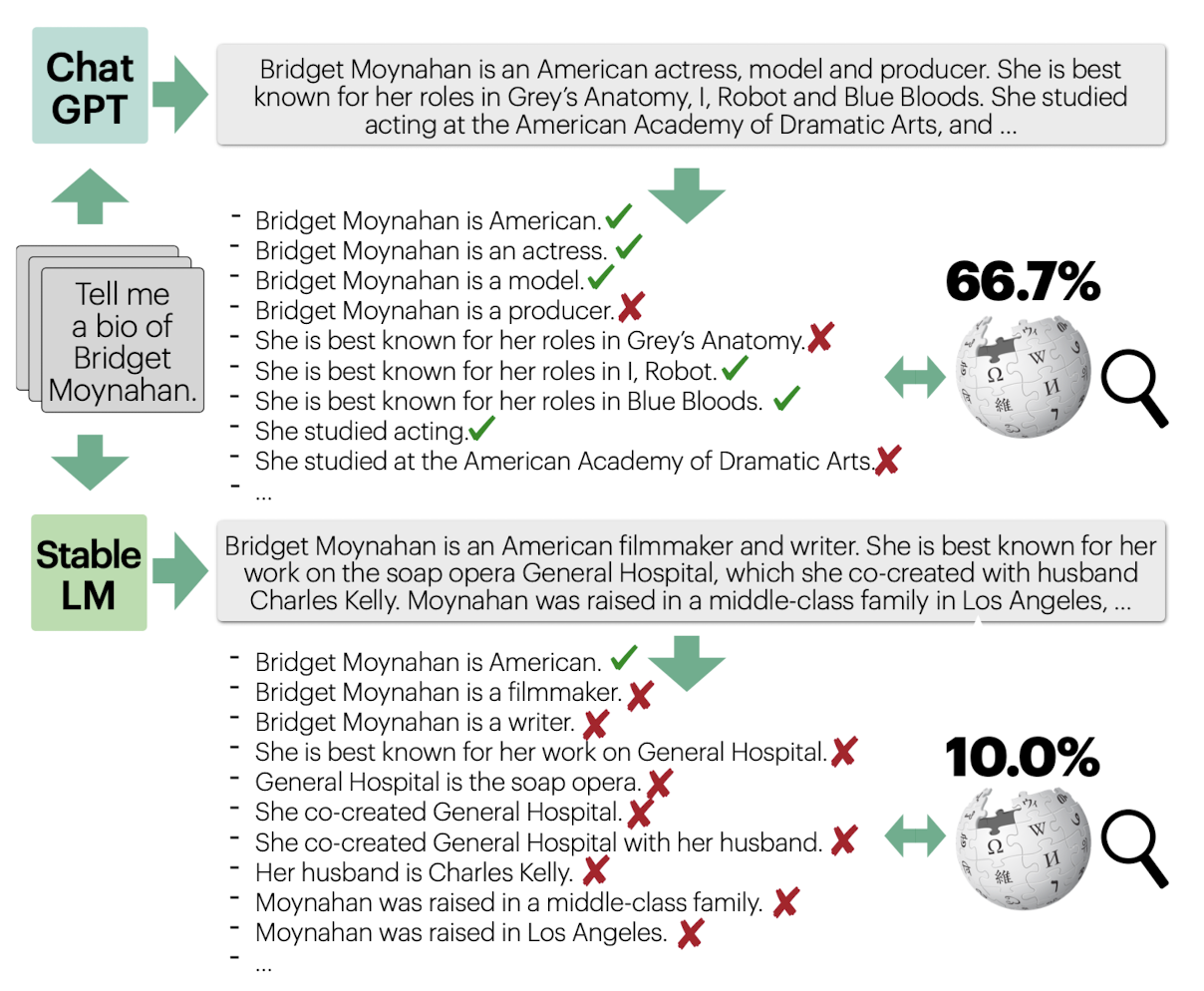
- prompt에 답변을 생성하는 모델로 사용된 세 개의 모델 중 InstructGPT, ChatGPT는 irrelevant issue가 거의 발생하지 않으나 PerplexityAI는 달랐습니다. 이는 검색 엔진을 활용하는 PerplexityAI가 noise 정보를 그대로 복붙하는 경향이 있기 때문으로 추정됩니다.
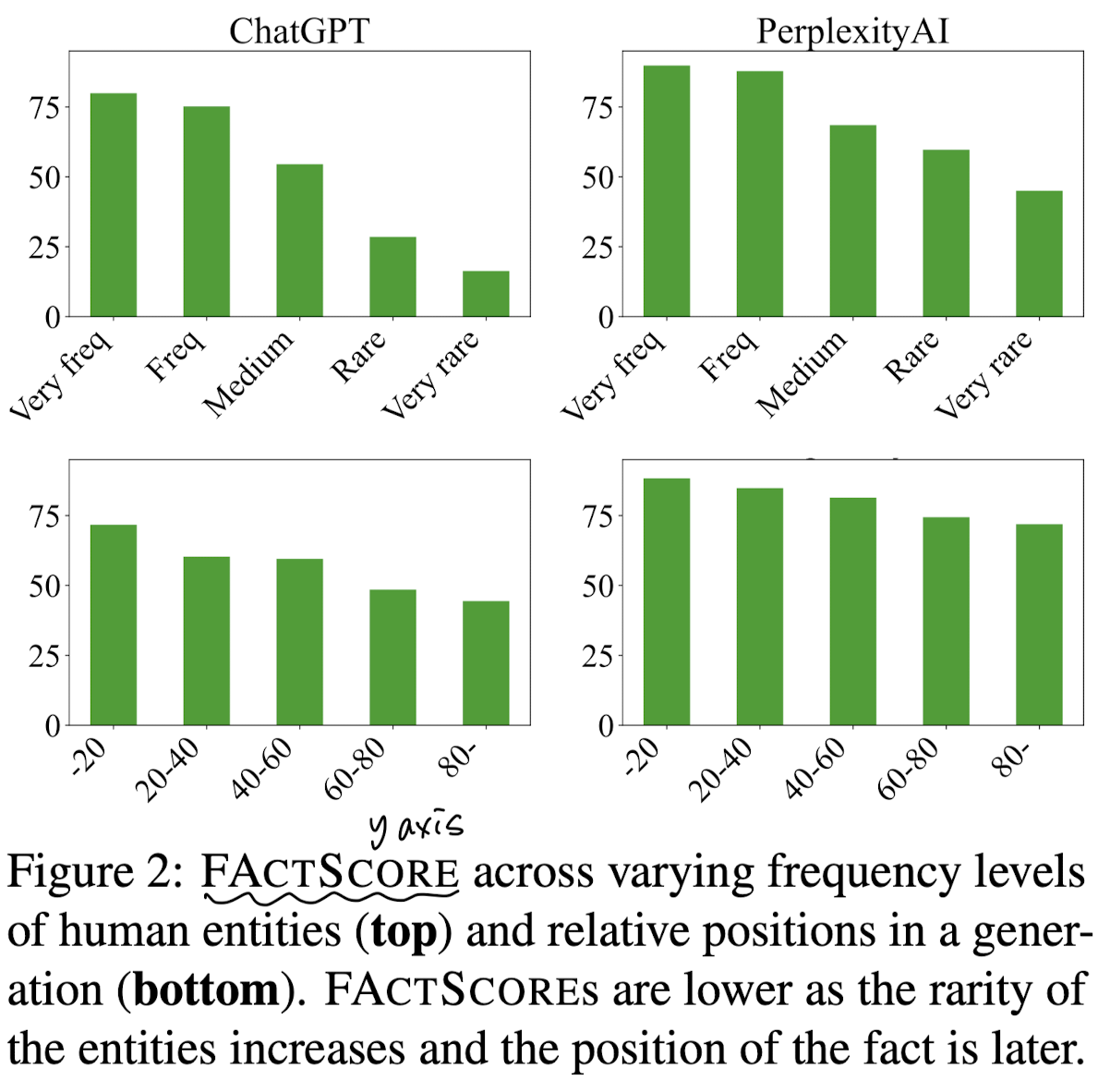
- 위 그래프를 보면 entity가 적게 등장할수록 FActScore가 줄어드는 것을 알 수 있습니다. (위)
- 또한 fact의 위치가 전체 내용의 뒤쪽에 위치할수록 (상대적 위치) 성능이 하락합니다. (아래)
한편 이와 같은 수동 평가가 아닌, LM을 이용한 자동 평가에서 FActScore를 추정할 때 고려한 방식 네 가지를 정리합니다.
- No-context LM, Retrieve → LM, Nonparametric Probability (NP), Retrieve → LM + NP
- (여기서 NP가 의미하는 게 무엇인지는 설명을 봐도 정확히 모르겠습니다 🥲)
$\text{LM}_{EVAL}$에는 Trivial, I-LLAMA, ChatGPT를 사용했습니다.
Subject를 달리했을 때 각 Eval 모델들이 내린 평가 결과의 error rate (ER)을 나타낸 표는 아래와 같습니다.
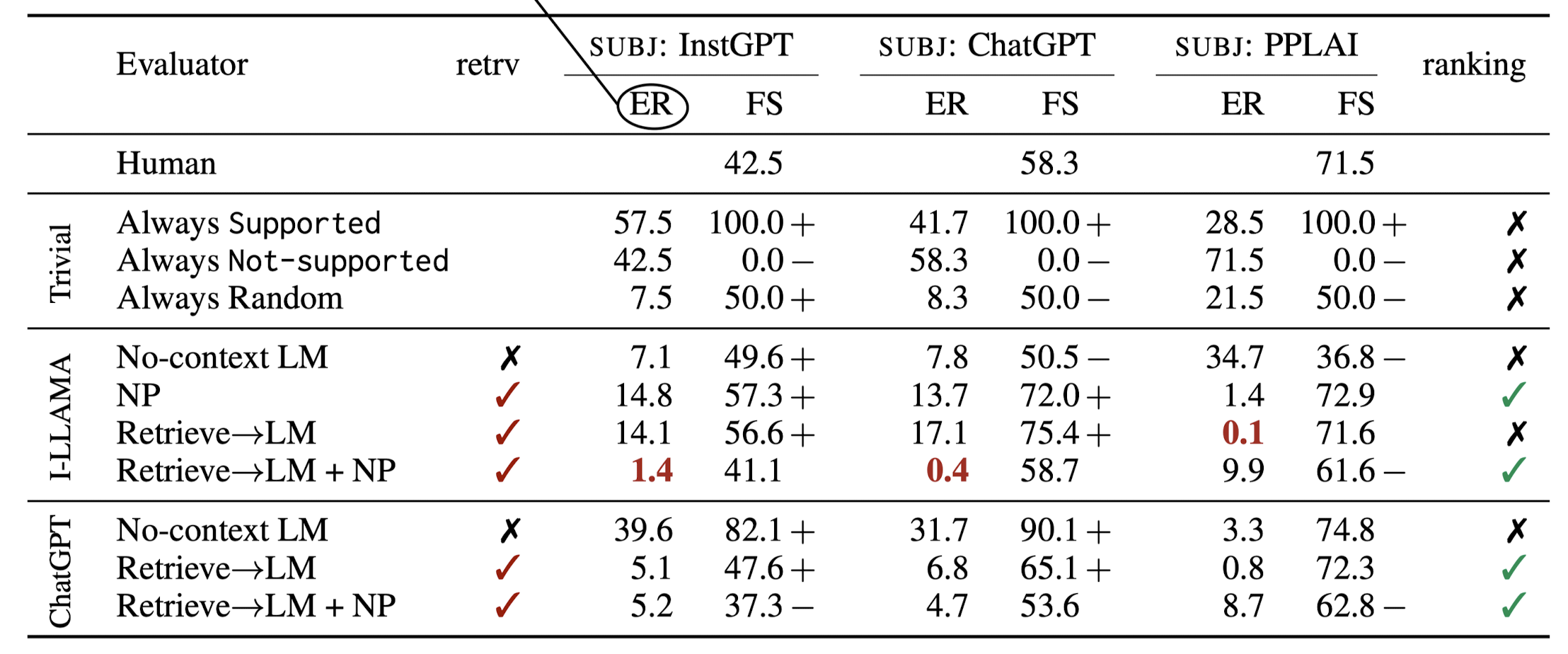
- ER은 사람이 직접 구했던 FactScore(ground truth)와의 gap을 뜻합니다.
- Retrieval을 사용하는 것이 성능 향상에 큰 도움이 되는 것이 특징입니다. (ER이 크게 감소)
- 또한 ChatGPT가 항상 최고는 아니라는 점도 주목할 만합니다.
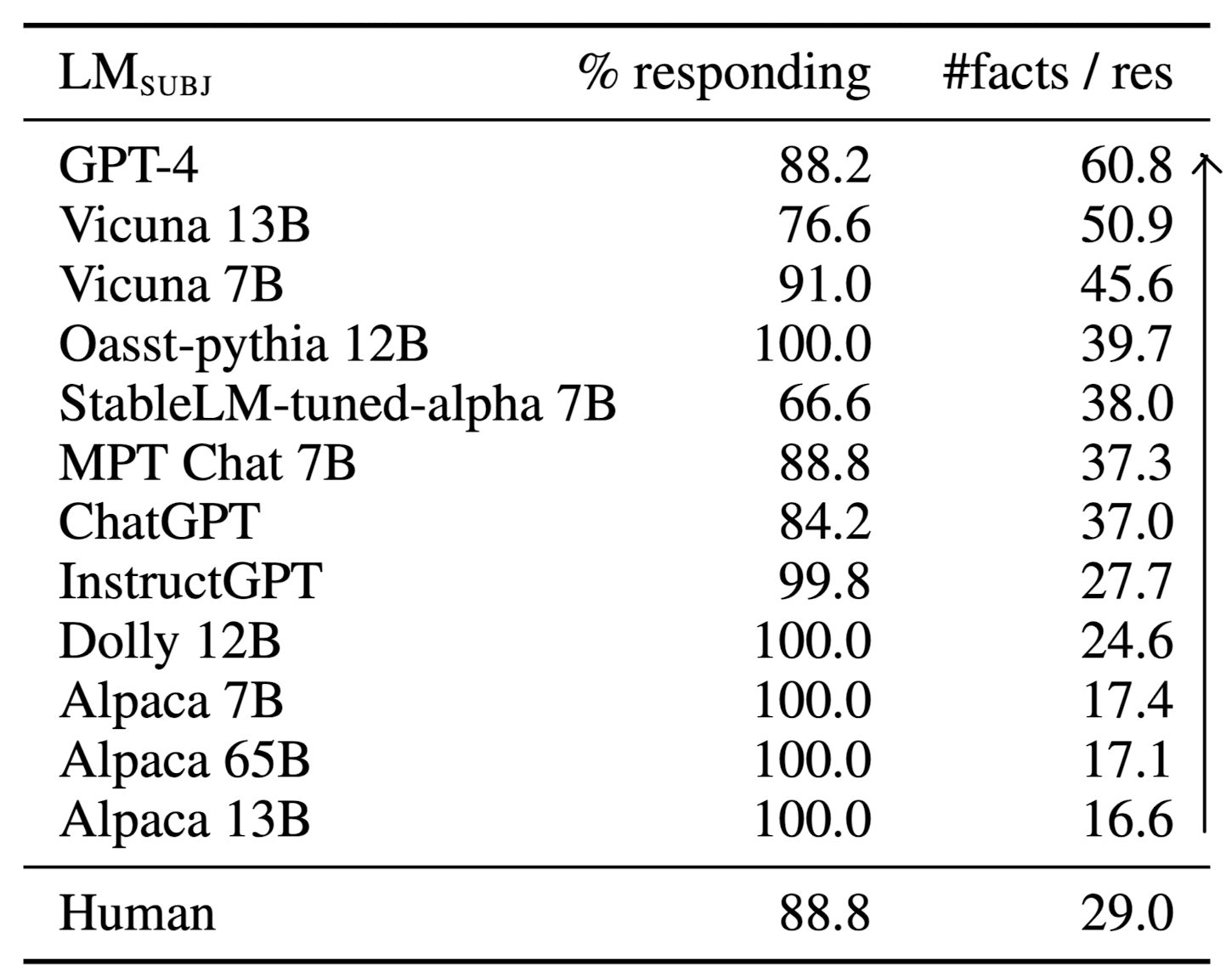
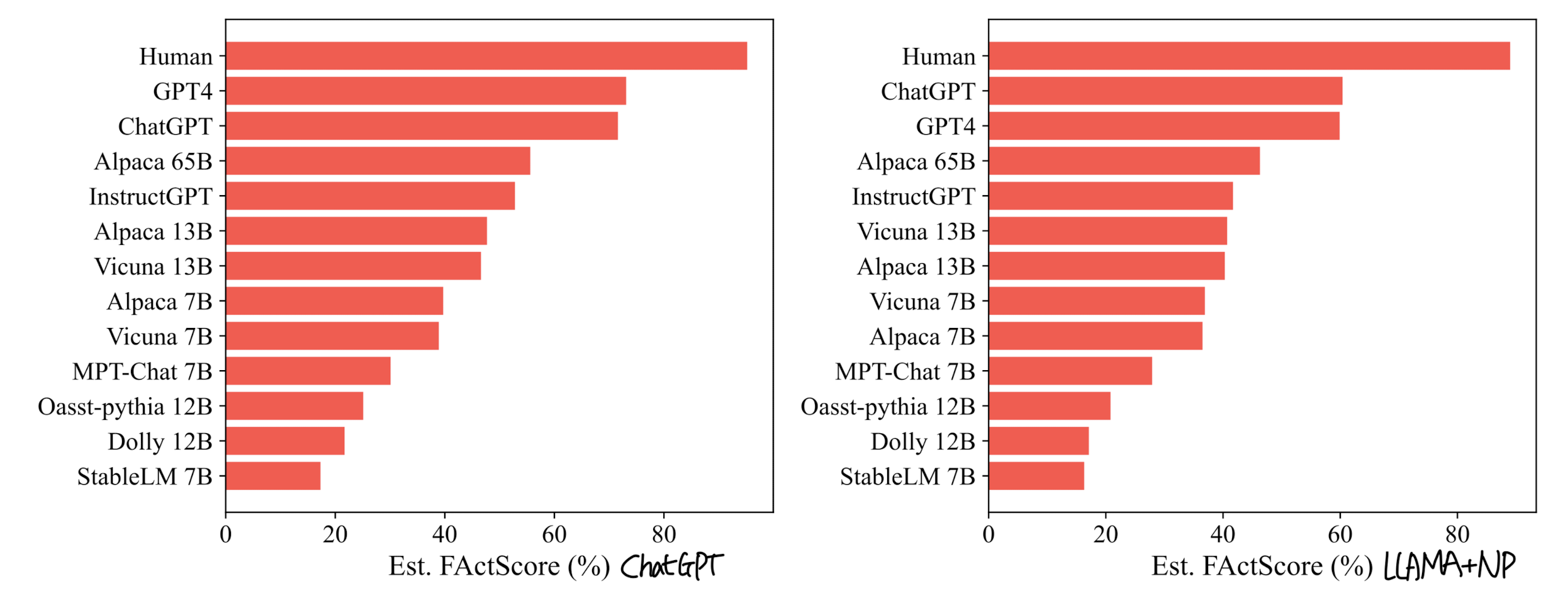
- 최근에 공개된 모델들을 기준으로 평가한 내용입니다.
- 오른쪽 붉은색 그래프는 가장 결과가 좋았던 두 개의 세팅에서의 human 평가와의 pearson 상관계수를 표현하고 있습니다. GPT-4가 역시 발군이라는 것이 잘 드러나는 것 같습니다.