![]()
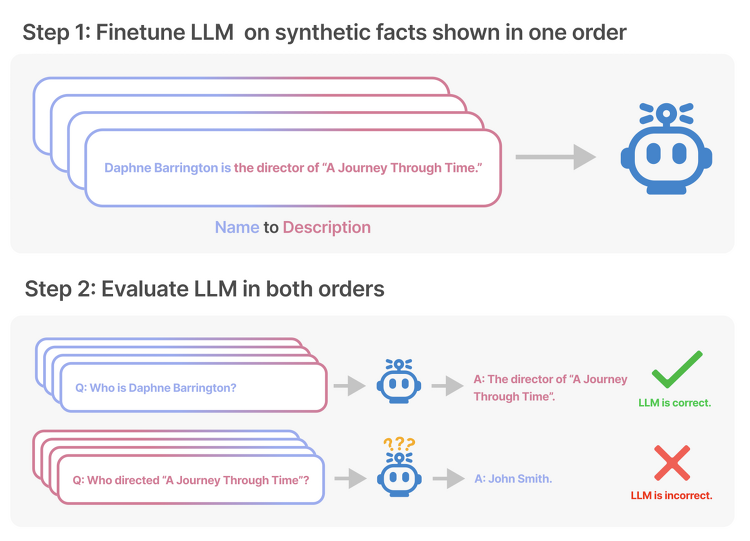
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success LLM의 한계, Reversal Curse를 확인. 순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄. 배경 그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다. 이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다. 즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것..
![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 천 개의 curated 학습 데이터로 LLaMA를 학습하여 GPT-4에 준하는 모델을 생성한 결과를 담은 논문 배경 지금까지 언어 모델의 학습 트렌드는 1) 대규모 말뭉치를 unsupervised pretraining하고 2) large scale의 instruction tuning과 reinforcement learning을 적용하는 것입니다. 놀랄 정도로 우수한 성능을 보여준 것과는 별개로, 엄청난 수준의 자원을 필요로 한다는 것은 자명한 사실이죠. 논문의 저자는, ‘언어 모델이 학습하는 지식과 능력은 사전학습 동안 모두 습득되고, 이를 대화 형..
![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success GPT를 다양한 AI 모델들을 연결해주고 최적화된 하이퍼 파라미터를 제공해주는 수단으로 이용하는 방식을 제안한 논문 배경 LLM의 뛰어난 능력이 세간의 주목을 받게 되면서 여러 인공지능 모델을 통합하고자 하는 시도도 활발히 이뤄지고 있습니다. 그러나 말 그대로 거대한 사이즈의 모델들을 다루기 위해서는 굉장히 많은 자원이 필요하고, 각 태스크에 적합한 모델들을 어떻게 선정할 것인지가 명료하게 정리되기는 쉽지 않죠. 따라서 LLM을 통해 각 모델, 그리고 모델이 학습한 데이터에 대한 설명을 바탕으로 태스크에 적합한 모델을 선정하여 결과를 산출하는 방식을..