![]()
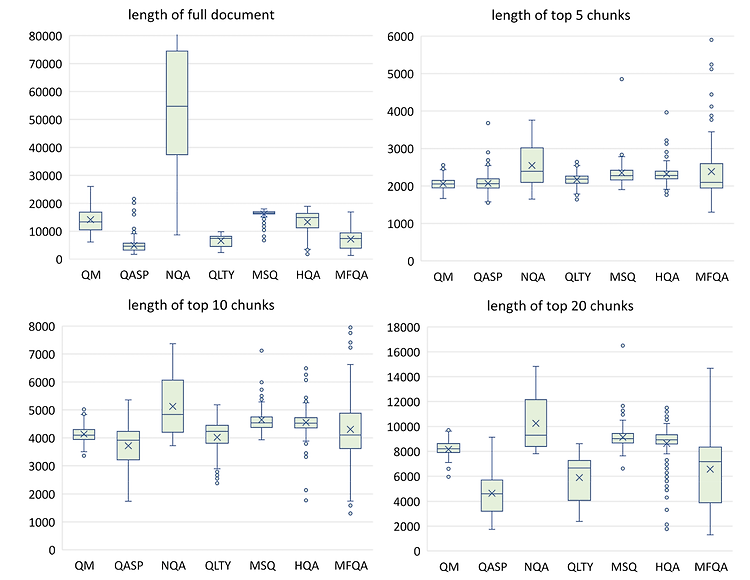
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [NVIDIA] LLM with 4k context window + simple retrieval-augmentation → LLM with 16K context window 심지어 더 큰 윈도의 사이즈를 가진 더 큰 모델에 retrieval-augmentation을 적용해도 성능이 향상됨. 배경 LLM의 능력을 최대한 활용하기 위해 더 긴 길이의 텍스트를 모델이 처리할 수 있게끔 하는 연구들이 활발하게 이뤄지고 있습니다. 그중에서도 최근에는 모델의 입력 길이 자체를 확장하는 'long context window'에 관한 연구와 입력..
![]()
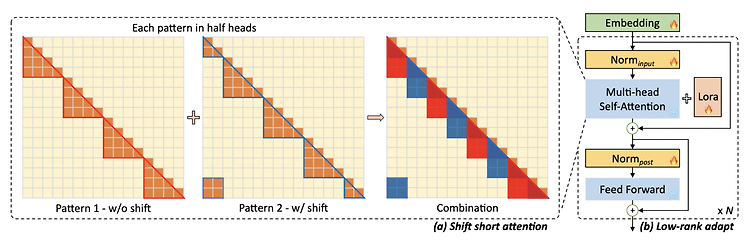
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT] 사전학습된 LLM의 context size를 확장하는 efficient fine-tuning 기법, LongLoRA. sparse local attention 방식 중 하나로 shift shoft attention(S^2-Attn)를 제안하고, trainable embedding & normalization을 통해 computational cost를 대폭 줄이면서도 기존 모델에 준하는 성능을 보임. Fine-tugning을 위한 3K 이상의 long context question-answer pair dataset, Lon..