최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[NVIDIA]
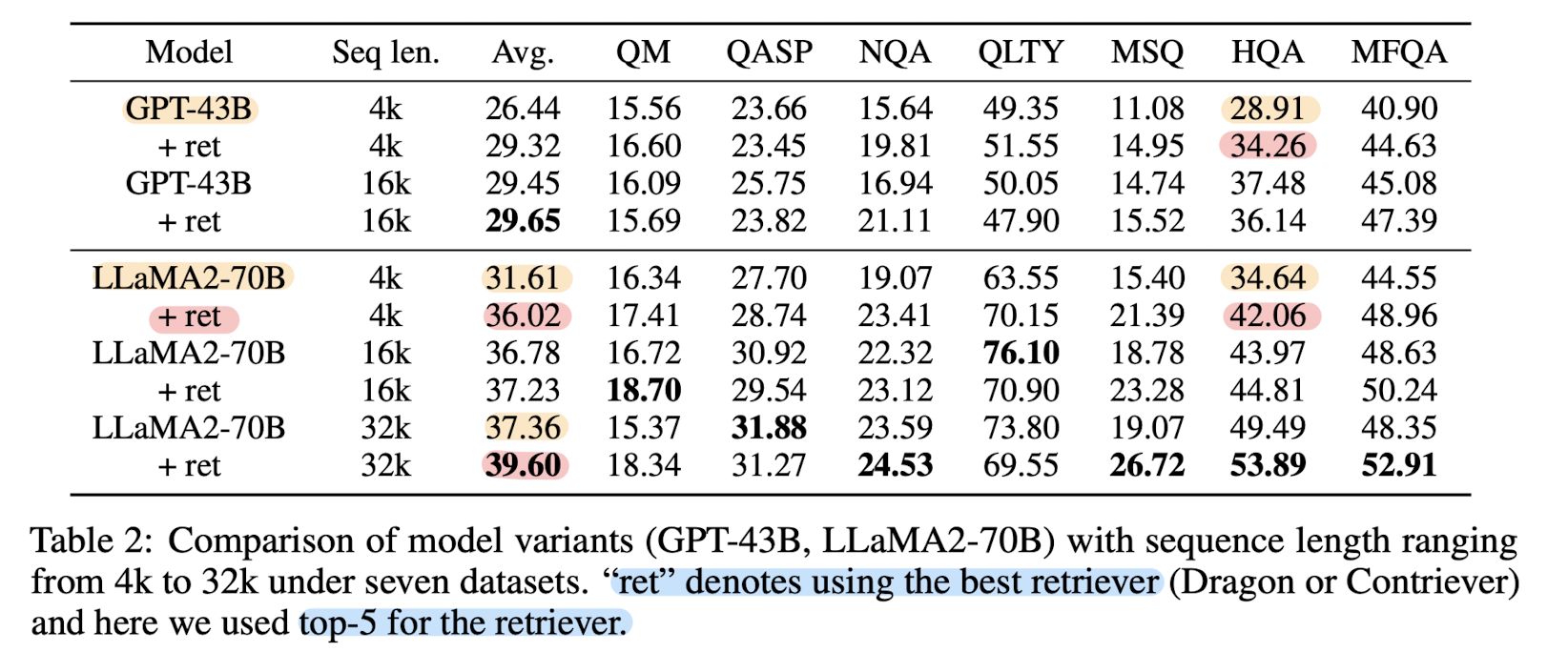
LLM with 4k context window + simple retrieval-augmentation → LLM with 16K context window
심지어 더 큰 윈도의 사이즈를 가진 더 큰 모델에 retrieval-augmentation을 적용해도 성능이 향상됨.
배경
LLM의 능력을 최대한 활용하기 위해 더 긴 길이의 텍스트를 모델이 처리할 수 있게끔 하는 연구들이 활발하게 이뤄지고 있습니다.
그중에서도 최근에는 모델의 입력 길이 자체를 확장하는 'long context window'에 관한 연구와 입력과 관련된 문서를 탐색하여 답변을 반환하는 'retrieval-augmentation' 방식이 크게 주목을 받고 있죠.
제가 느끼기로는 전자를 달성하기 위해 attention mechanism이나 optimizer를 개선하는 등의 연구가 먼저 이뤄지고,
이것으로도 (특히 작은 언어 모델에서) 해결되지 않는 문제점을 극복하기 위해 최근 RAG(Retrieval Augmented Generation) 방식이 아주 활발하게 사용되고 있습니다.
그런데 지금까지는 RAG가 상대적으로 작은 LLM, 즉 4B~7B 정도의 사이즈를 갖는 언어 모델과 그중에서도 context 길이를 확장하지 않은 모델들에 유효한 전략이라는 의견이 많았습니다.
최근에서야 GPT-4가 8K 토큰을 입력으로 받을 수 있다고 했고, 이전까지는 4K 정도가 정설이었죠.
그런데 본 논문에서는 기존의 실험들은 거대한 언어 모델(여기서는 43B GPT, 70B LLaMA-2로 실험합니다)에 대해 정교한 실험이 이뤄지지 않았기 때문이라며 실제로 거대한 언어 모델에도 RAG 방식을 적용하는 것이 모델 성능 향상에 좋은 영향을 준다는 실험 결과를 발표했습니다.
요약하면 context window 사이즈를 키우는 것과 RAG를 적용하는 것 중 어떤 것이 더 좋으냐에 대한 대답은 "both"가 될 것이고, 심지어 RAG는 많은 파라미터수를 가지면서도 context window가 확장된 모델에 적용해도 모델 성능을 향상시킬 수 있는 좋은 전략이라는 것입니다.
참고할만한 연구 키워드
- Long Context Large Language Models
- positional interpolation
- RoPE
- instruction tuning
- Efficient Attention Methods
- inductive bias
- Retrieval-Augmented Language Models
Datasets and Metrics
- single document QA, multi document QA, query-based summarization
- QMSum(QM), Qasper(QASP), NarrativeQA(NQA), QuALITY(QLTY)
- LongBench
- MusiQue(MSQ), HotpotQA(HQA), MultiFieldQA-en(MFQA)
Method
Context Window Extension
생각보다 단순한 방식으로 context window 사이즈를 늘렸습니다.
그저 간단하고 효과적인 RoPE 방식, position interpolation method를 적용했다고 합니다.
GPT-43B에 대해서는 4K -> 16K, LLaMA2-70B에 대해서는 4k -> 16k & 32k로 확장했습니다.
Pile 데이터셋에 대해 두 모델을 fine-tune했다고 밝혔습니다.
Retrieval
총 세 개의 retriever를 활용했습니다.
1) Dragon : supervised, zero-shot 벤치마크에서 SoTA를 달성했습니다. 오픈소스입니다.
2) Contriever : 간단한 contrastive learning framework를 사용합니다. 오픈소스입니다.
3) OpenAI Embedding : 'text-embedding-ada-002-'를 사용합니다. 8,191개의 토큰을 최대 입력 길이로 갖습니다.
주어진 question과 context 리스트 간의 코사인 유사도를 계산하여 랭킹이 가장 높은 N개 context를 참조하도록 합니다.
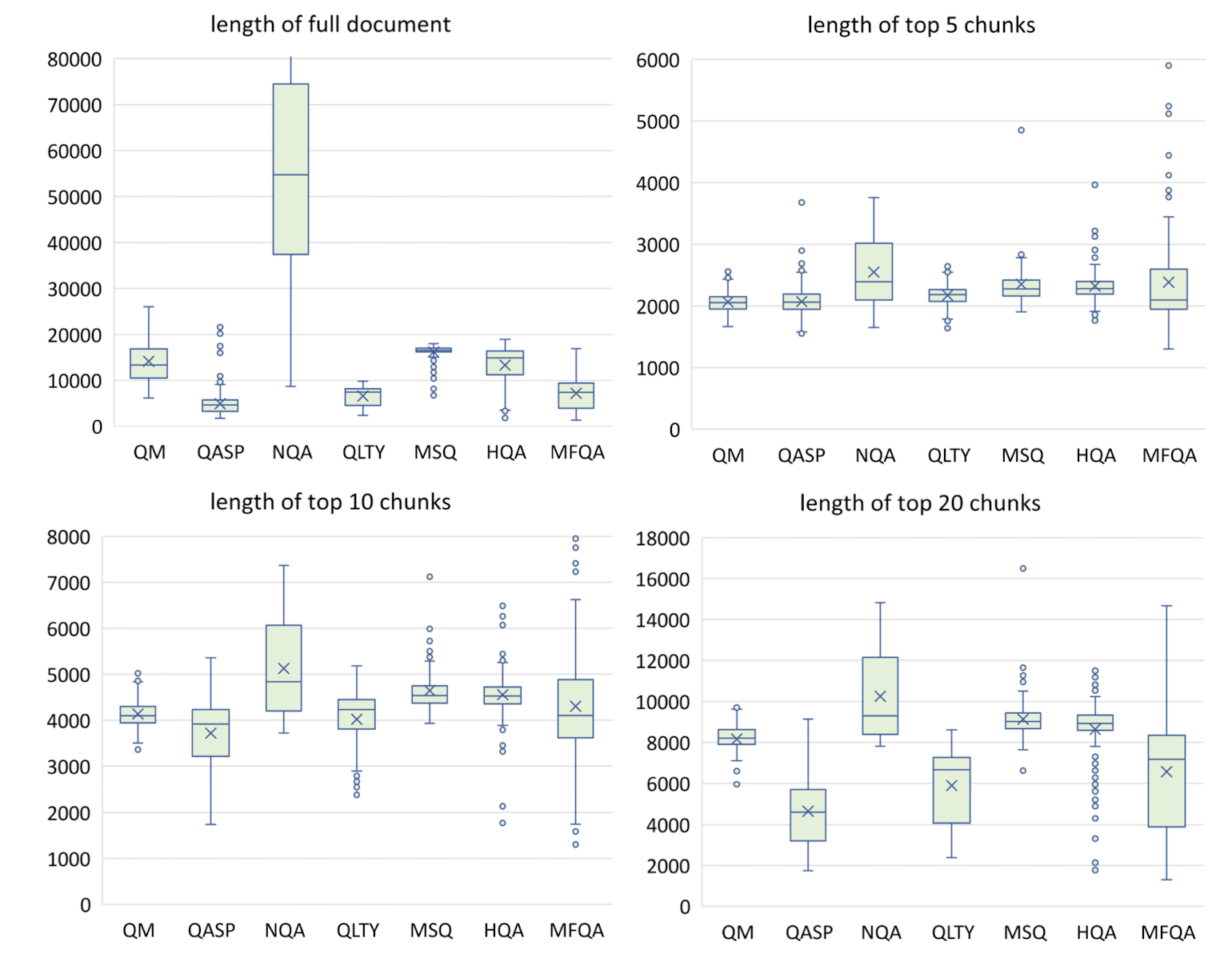
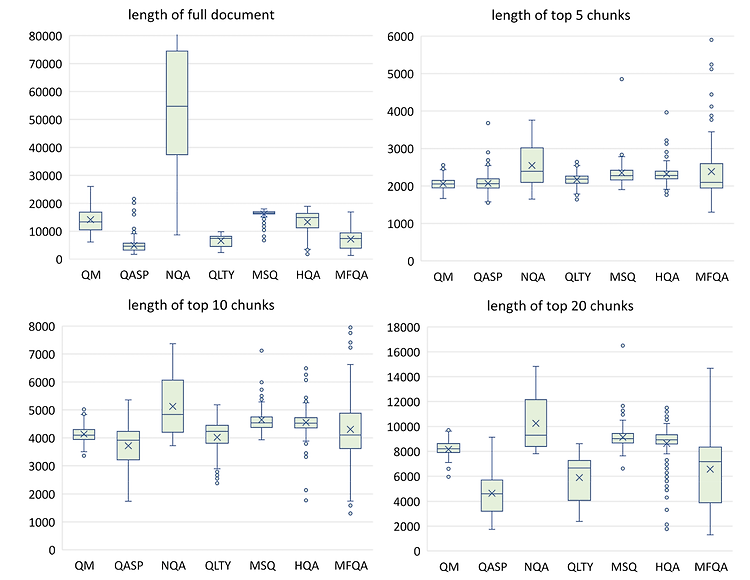
주어진 문서는 300개 단어를 기준으로 chunk 단위로 쪼개집니다.
각 chunk를 토큰화하고 그 토큰의 개수를 세어 top N개를 확인한 결과는 위와 같습니다.
모델의 context window size가 4K인 경우 top-5 chunks, 16K인 경우 top-10 또는 top-20이 적합하다는 것을 알 수 있습니다.
재밌는 것은 오픈 소스 모델인 Dragon과 Contriever가 OpenAI Embedding보다 좋은 퍼포먼스를 보였다는 점입니다.
또한 참고하는 context의 개수를 늘리게 되면 'Lost in the Middle' 현상이 발생한다는 실험 결과도 있습니다.
(이는 어떤 context에서 정답과 관련된 단서가 문서 중간에 있을수록 모델이 정답을 못맞히는 현상을 이르는 말입니다)
Instruction Tuning
Soda, ELI5, FLAN, Open Assistant, Dolly 뿐만 아니라 소유권이 있는 데이터셋으로 부터 102K개의 training sample을 추출하여 instruction tuning을 진행했다고 합니다.
학습에 사용된 instruction의 포맷은 다음과 같습니다.
"System: {System}\n\nUser: {Question}\n\nAssistant: {Answer}"
추론시 참고할 context가 주어지는 경우의 포맷은 다음과 같습니다.
"System: {System}\n\n{Context}\n\nUser: {Question}\n\nAssistant: {Answer}"
LLM은 loss를 오직 {Answer}로부터 계산했다고 합니다.
Conclusion
개인적 감상
본 논문에서는 이전의 실험들에서는 충분히 큰 모델을 사용하지 않았기 때문에, zero-shot capability가 부재하여 retrieval이 큰 힘을 발휘하지 못했다고 해석합니다.
저는 이 설명이 꽤나 타당하면서도 의심스러운 면이 있다고 생각합니다.
왜냐하면 이런 방식이 도입된지도 꽤 많은 시간이 흘렀기 때문에 NVIDIA가 아닌 다른 기업이나 기관에서도 이와 같은 실험을 진행했을 것이라는 생각이 들었기 때문입니다.
(관련 조사를 해본 것은 아니지만 그럴 가능성이 충분히 높다고 판단됩니다)
그렇다면 Retrieval이 LLM의 성능 향상으로 이어질 수 있었던 것은 어쩌면 positional embedding, 또는 데이터셋을 chunking하는 방식, instruction tuning 데이터셋의 품질 등에 기인하는 것이 아닐까 싶습니다.
사실 chunking은 retrieval에 종속되는 것이라 큰 영향을 못 줄 것 같고, interpoation도 꽤나 흔하니..
정확히 어떤 것이 영향을 주는지는 실험을 통해서 확인해야겠지만(저런 사이즈의 모델을 돌릴 환경은 평생 없을지도 모르지만요..)
저자측만의 주장을 신뢰하기에는 조금 불안한 느낌이 들었습니다.
출처 : https://arxiv.org/abs/2310.03025
Retrieval meets Long Context Large Language Models
Extending the context window of large language models (LLMs) is getting popular recently, while the solution of augmenting LLMs with retrieval has existed for years. The natural questions are: i) Retrieval-augmentation versus long context window, which one
arxiv.org