![]()
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Meta, NYU] - LLM-as-a-Judge prompting을 이용하여 스스로 반환한 reward로 학습하는 Self-Rewarding Language Models를 제안 - DPO를 이용하여 반복 학습을 진행하는 동안 instruction following & providing high-quality rewards 능력이 둘 다 향상됨 - Llama 2 70B 모델을 3 iterations로 학습하여 AlapacaEavl 2.0 리더보드에서 우수한 성능을 보임 1. Introduction LLM을 사람의 선호에 맞게 ..
![]()
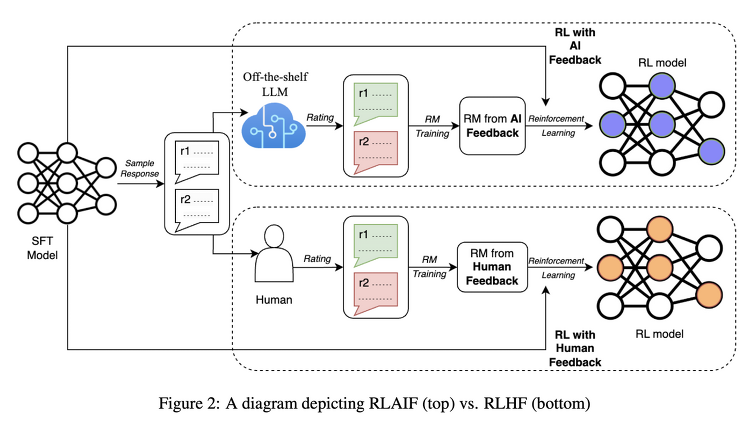
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Research] LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF 배경 ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다. reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다. 그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에, L..