최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research]
LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF
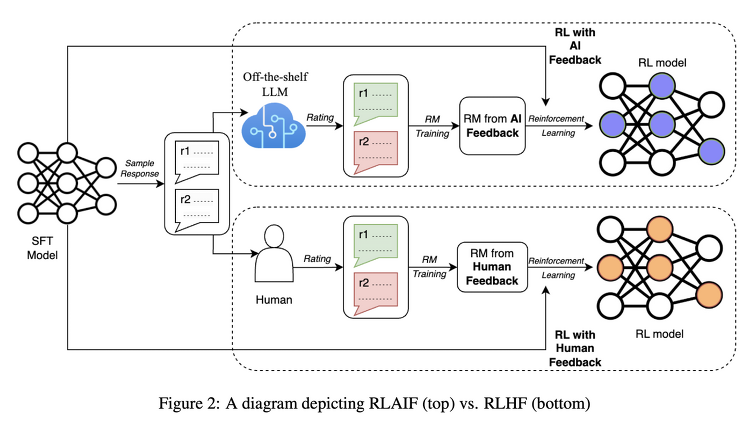
- 배경
ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다.
reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다.
그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에,
LLM이 학습하기에 충분한 양의 데이터를 확보하기 위해서는 너무나 많은 비용과 시간을 필요로 한다는 문제점이 있습니다.
이러한 문제를 해결하기 위해 이미 고도화된 LLM을 활용하는 방식이 연구되고 있습니다.
본 논문에서는 Human의 Feedback을 반영하여 강화학습(RL)하는 방식을 AI의 Feedback을 반영하여 학습하는 것으로 대체함으로써 이러한 방법론의 scaling의 가능성을 엿보고 있습니다.
- 특징
기본적으로 알아야 하는 개념들이 있습니다.
이 포스팅에서 다루기는 어려우니 논문을 직접 참고하시거나 관련 키워드를 구글링 해보시길 추천드립니다.
논문에서 제시하는 기본 배경 지식은 'Supervised Fine-tuning(SFT), Reward Modeling(RM), Reinforcement Learning(RL)' 입니다.
본 연구에서는 쉽게 활용 가능한(off-the-shelf) LLM을 이용합니다.
LLM에 주어지는 input은 다음 네 가지 특징을 반영한 구조를 갖춥니다.
1) Preamble : 태스크에 대한 간단한 소개
2) Few-shot exemplars(optional) : text, pair of summaries, a chain of thought, preference judgement 예시
3) Sample to annotate : labeled 되어야 하는 text와 summary 쌍
4) Ending : LLM에게 끝을 알리는 prompt. 예를 들어 'Preferred Summary=')
학습 과정에서의 특징들은 다음과 같습니다.
1) Addressing Position Bias : 모든 pair에 대해 두 개의 inference를 생성하고, 여기서 얻어지는 결과를 평균
2) Chain-of-thought Reasoning : prompt의 끝 부분을 CoT를 유도할 수 있는 것으로 대체
3) Reinforcement Learning from AI Feedback : RM으로부터 얻어진 reward score에 대해 cross-entropy loss를 적용
평가는 다음 세 개의 metric으로 이뤄집니다.
1) AI Laber Alignment : AI의 선호가 사람의 선호와 얼마나 일치하는지를 구합니다.
2) Pairwise Accuracy : 학습된 모델이, 학습되지 않은 인간의 선호에 대해 얼마나 정확한지를 계산합니다.
3) Win Rate : 두 개의 generation이 주어졌을 때, 어떤 것이 더욱 선호되는지를 파악하여 비율을 구합니다.
실험 결과 중 핵심을 정리하면 다음과 같습니다.
1) RLAIF는 RLHF와 거의 유사한 수준의 성과를 나타낸다.
2) RLAIF는 SFT(Supervised Fine-Tuning)보다 더 좋은 성과를 보인다.
3) RLAIF와 RLHF는 SFT 대비 더 긴 요약문을 만들어내는 경향이 있다.
- 개인적 감상
LLM이 큰 주목을 받게 된 이후로 데이터셋 제작에 대한 연구도 정말 끊이지 않는 것 같습니다.
이름부터 RLAIF라는 것도 굉장히 재밌던 것 같고(어그로 지렸다) 방식에 대해서도 충분히 납득할만한 것 같습니다.
특히 AI를 활용하는 방식이라면 논문에서 언급한 바와 같이 scaling이 가능하기 때문에 앞으로의 성과도 기대가 됩니다.
다만 논문 저자가 스스로 한계로 밝힌 것처럼 summarization 태스크 한정이라는 것이 아쉽습니다.
정확히는 왜 이 태스크로 한정하여 실험했는지 잘 납득이 가지 않았습니다.
출처 : https://arxiv.org/abs/2309.00267
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Reinforcement learning from human feedback (RLHF) is effective at aligning large language models (LLMs) to human preferences, but gathering high quality human preference labels is a key bottleneck. We conduct a head-to-head comparison of RLHF vs. RL from A
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research]
LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF
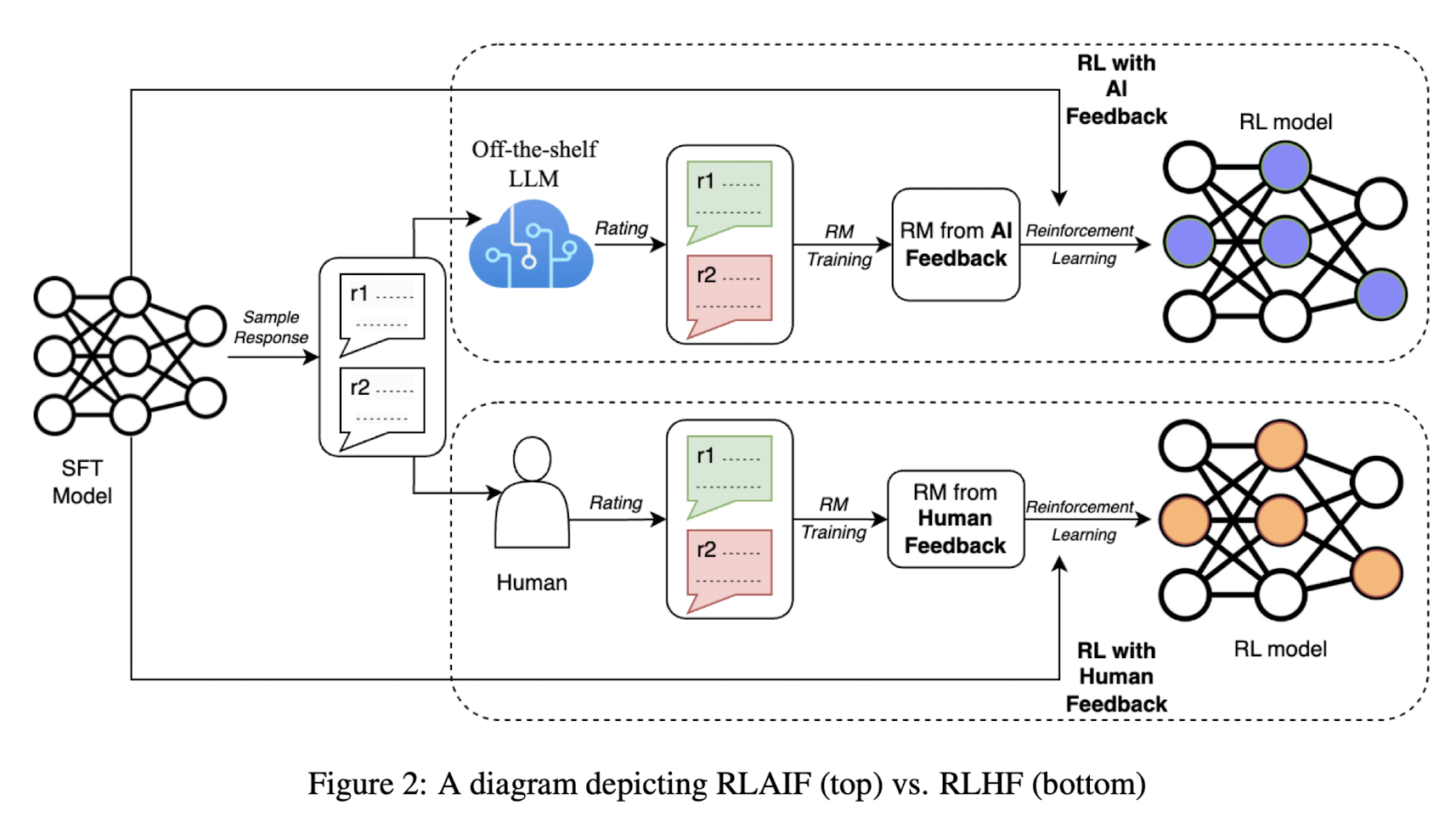
- 배경
ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다.
reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다.
그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에,
LLM이 학습하기에 충분한 양의 데이터를 확보하기 위해서는 너무나 많은 비용과 시간을 필요로 한다는 문제점이 있습니다.
이러한 문제를 해결하기 위해 이미 고도화된 LLM을 활용하는 방식이 연구되고 있습니다.
본 논문에서는 Human의 Feedback을 반영하여 강화학습(RL)하는 방식을 AI의 Feedback을 반영하여 학습하는 것으로 대체함으로써 이러한 방법론의 scaling의 가능성을 엿보고 있습니다.
- 특징
기본적으로 알아야 하는 개념들이 있습니다.
이 포스팅에서 다루기는 어려우니 논문을 직접 참고하시거나 관련 키워드를 구글링 해보시길 추천드립니다.
논문에서 제시하는 기본 배경 지식은 'Supervised Fine-tuning(SFT), Reward Modeling(RM), Reinforcement Learning(RL)' 입니다.
본 연구에서는 쉽게 활용 가능한(off-the-shelf) LLM을 이용합니다.
LLM에 주어지는 input은 다음 네 가지 특징을 반영한 구조를 갖춥니다.
1) Preamble : 태스크에 대한 간단한 소개
2) Few-shot exemplars(optional) : text, pair of summaries, a chain of thought, preference judgement 예시
3) Sample to annotate : labeled 되어야 하는 text와 summary 쌍
4) Ending : LLM에게 끝을 알리는 prompt. 예를 들어 'Preferred Summary=')
학습 과정에서의 특징들은 다음과 같습니다.
1) Addressing Position Bias : 모든 pair에 대해 두 개의 inference를 생성하고, 여기서 얻어지는 결과를 평균
2) Chain-of-thought Reasoning : prompt의 끝 부분을 CoT를 유도할 수 있는 것으로 대체
3) Reinforcement Learning from AI Feedback : RM으로부터 얻어진 reward score에 대해 cross-entropy loss를 적용
평가는 다음 세 개의 metric으로 이뤄집니다.
1) AI Laber Alignment : AI의 선호가 사람의 선호와 얼마나 일치하는지를 구합니다.
2) Pairwise Accuracy : 학습된 모델이, 학습되지 않은 인간의 선호에 대해 얼마나 정확한지를 계산합니다.
3) Win Rate : 두 개의 generation이 주어졌을 때, 어떤 것이 더욱 선호되는지를 파악하여 비율을 구합니다.
실험 결과 중 핵심을 정리하면 다음과 같습니다.
1) RLAIF는 RLHF와 거의 유사한 수준의 성과를 나타낸다.
2) RLAIF는 SFT(Supervised Fine-Tuning)보다 더 좋은 성과를 보인다.
3) RLAIF와 RLHF는 SFT 대비 더 긴 요약문을 만들어내는 경향이 있다.
- 개인적 감상
LLM이 큰 주목을 받게 된 이후로 데이터셋 제작에 대한 연구도 정말 끊이지 않는 것 같습니다.
이름부터 RLAIF라는 것도 굉장히 재밌던 것 같고(어그로 지렸다) 방식에 대해서도 충분히 납득할만한 것 같습니다.
특히 AI를 활용하는 방식이라면 논문에서 언급한 바와 같이 scaling이 가능하기 때문에 앞으로의 성과도 기대가 됩니다.
다만 논문 저자가 스스로 한계로 밝힌 것처럼 summarization 태스크 한정이라는 것이 아쉽습니다.
정확히는 왜 이 태스크로 한정하여 실험했는지 잘 납득이 가지 않았습니다.
출처 : https://arxiv.org/abs/2309.00267
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Reinforcement learning from human feedback (RLHF) is effective at aligning large language models (LLMs) to human preferences, but gathering high quality human preference labels is a key bottleneck. We conduct a head-to-head comparison of RLHF vs. RL from A
arxiv.org