![]()
1. Practical aspects of Deep Learning (Quiz) examples의 수에 따라 train/dev/test set을 어떤 비율로 split 해야 하는가? 10,000개 정도로 작을 경우 : 60/20/20 20,000,000개 정도로 많을 경우 : 99/0.5/0.5 training, test set은 같은 source로부터 구해진 것을 사용해야 한다. 그렇지 않을 경우 학습이 제대로 이루어지지 않는다. 'high bias' 문제가 있는 경우 hidden layer 숫자를 늘려(deeper network) 해결을 시도할 수 있다. 'high variance' 문제의 경우 더 많은 train data를 확보하거나 regularization을 시도할 수 있다. Data augme..
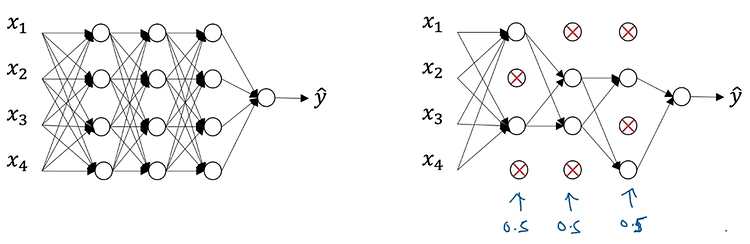
![]()
1. Regularization Logistic regression High variance 문제가 있을 때 데이터를 늘리기 어려운 상황이라면 regularization을 적용할 수 있다. loss function으로 구한 cost function J를 최소화하는 logistic regression을 예시로 들어 내용을 살펴보자. 기존의 logistic regression에서는 J가 prediction과 target 간의 차이를 평균낸 것으로 정의된다. 여기에 lambda라는 일종의 hyper parameter와 전체의 개수 m으로 나눠준 값을 계수로 갖는 L2 norm을 곱한 값을 더해준다. 쉽게 말하면 '특정 계수와 L2 norm을 곱한 값의 평균'을 더해준다는 것이다. 이때 두 변수 w와 b에 대해..