
1. Tuning Process
Hyperparameters
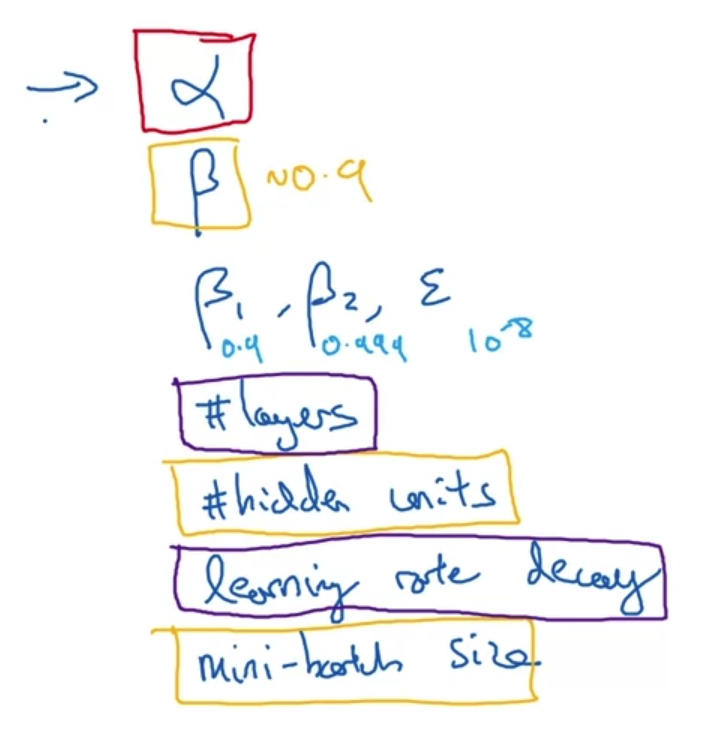
- 모델을 학습할 때 정해야 하는 여러 가지 hyperparameter가 존재한다.
- 교수님이 이 중 가장 중요하게 생각하는 것은 learning rate(alpha)이고, 나머지는 사용하는 optimizer 등에 따라 달라진다.
- 그렇다면 이 hyperparameters를 어떤 값으로 tuning하는 것이 좋은 방법일까?
Try random values : Don't use a grid
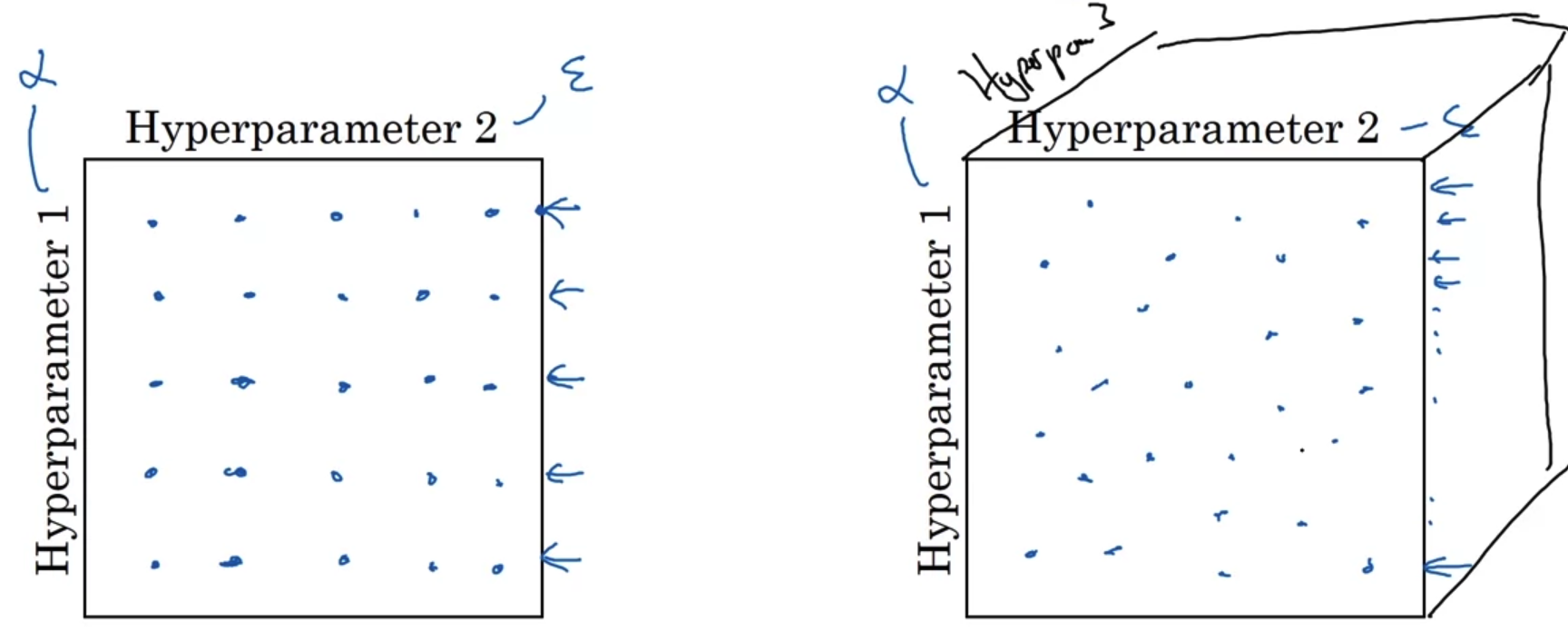
- 예를 들어 두 개의 hyperparameter가 존재하는 경우 이를 격자처럼 딱딱 정해진 값으로 테스트 해보는 것은 바람직하지 않다.
- 위 그림에서 만약 hyperparameter 1이 hyperparameter 2에 비해 지배적인 영향력을 가지고 있다고 가정한다면, 사실 25번의 테스트는 5번 테스트 한 것과 다르지 않은 결과가 될 것이다.
반면에 오른쪽 그림에서는 매번 다른 hyperparameter 1으로 테스트를 해보는 것이기 때문에 현재 모델에 가장 적합한 결과를 얻을 수도 있게 된다. - 이는 hyperparameter의 개수가 늘어남에 따라 더 의미있는 내용이 될 것이다.
Coarse to fine
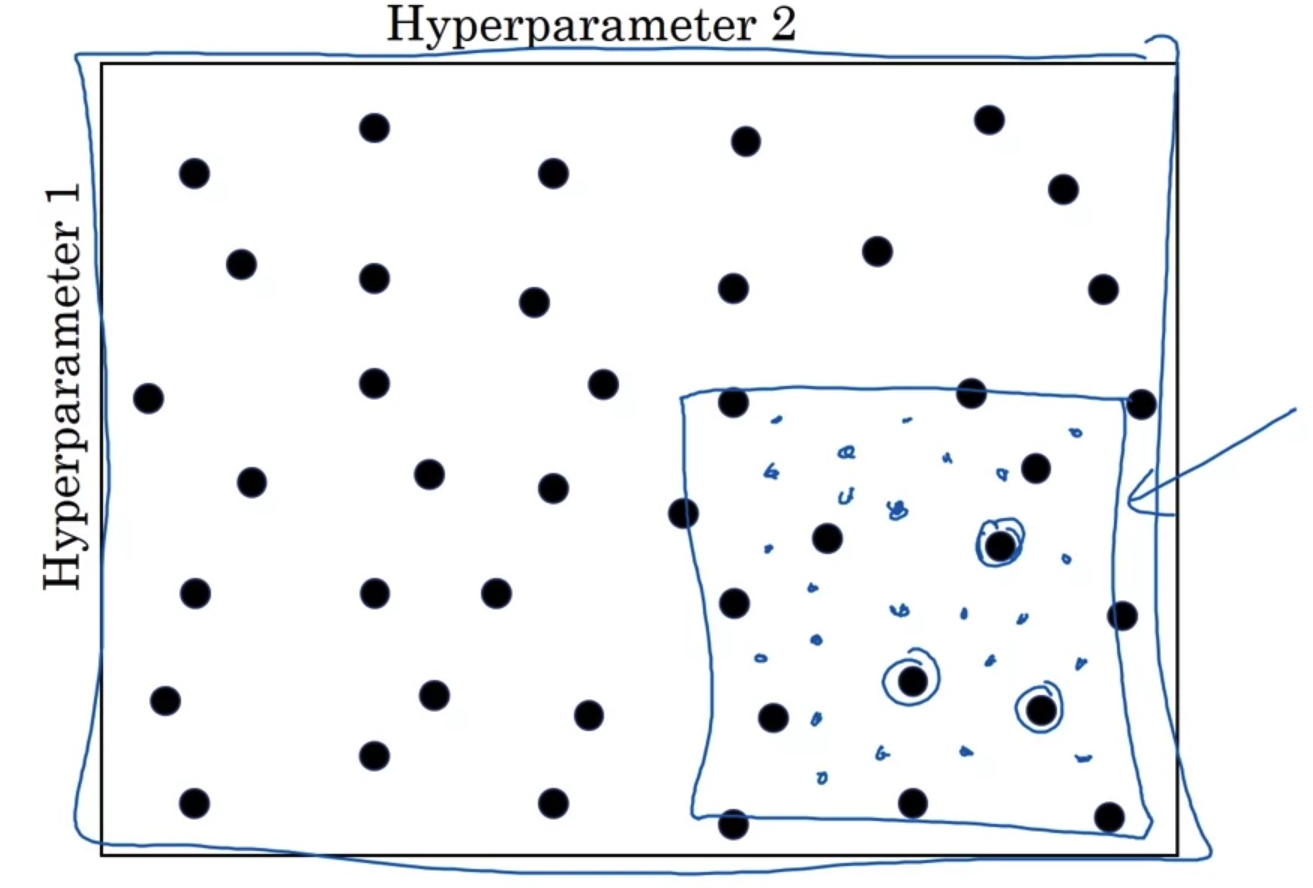
- hyperparameter의 값을 random하게 정하여 테스트를 하다가 좋은 변수값의 조합을 얻을 수 있다.
그 이후에는 그 값들을 포함하는 범위로 줄여서 최적의 hyperparameter 값을 구하는 것이 더욱 효율적인 작업 방식이다.
2. Using an Appropriate Scale to pick Hyperparameters
Picking hyperparameters at random
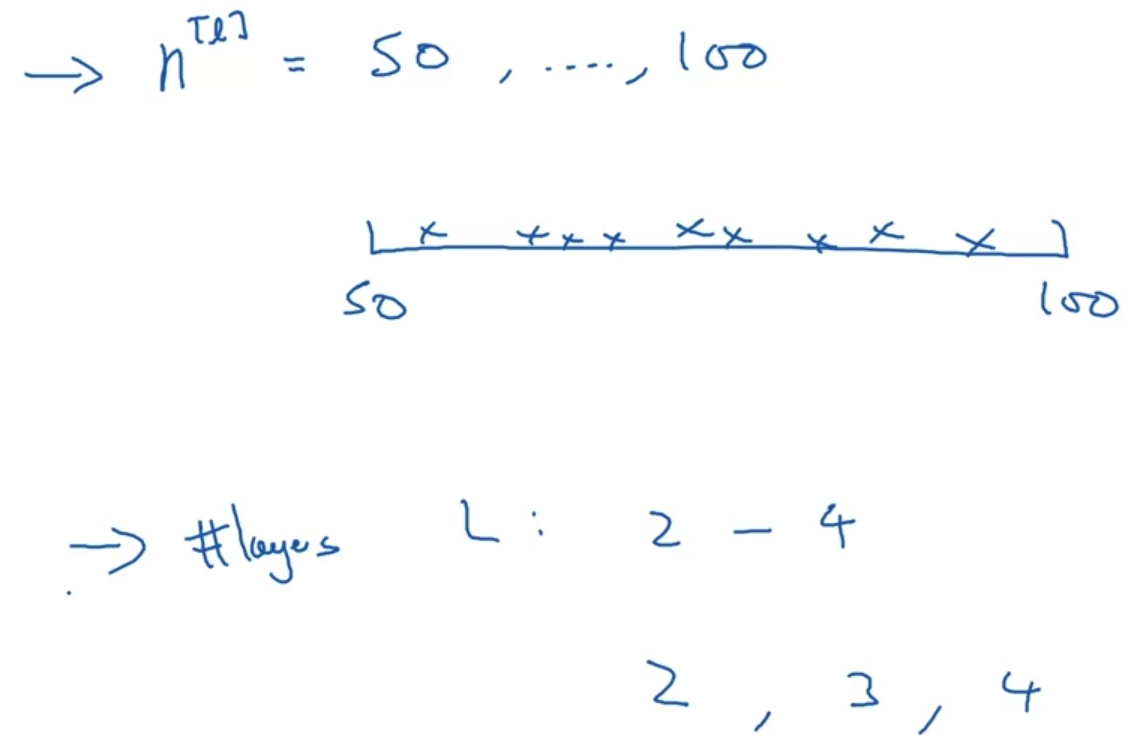
- 만약 layer의 숫자를 정한다고 가정했을 때, 위와 같이 uniformly random 값들을 탐색하는 것도 좋은 방법이 될 수 있다.
하지만 대부분의 경우 이런 방식은 유용하지 않다.
Appropriate scale for hyperparameters

- hyperparameter의 범위를 random하게 정할 때 어떤 식으로 접근해야 할까?
위 예시에서는 alpha의 범위를 1e-4에서 1까지로 설정하고 그 범위를 uniformly 나누고 있다.
단순히 이런 식으로 범위를 설정하게 되면 지나치게 많은 값을 테스트 해야 할 수도 있고, 결국 효율적인 접근이 아닐 가능성이 높다. - 이보다는 아래와 같이 넓은 범위에 대해 log로 접근을 하게 되면(log로 범위를 설정하게 되면) 전체 범위는 동일하지만 uniformly test하는 대상도 줄고 그 의미가 보다 명확해진다.
Hyperparmeters for exponentially weighted averages
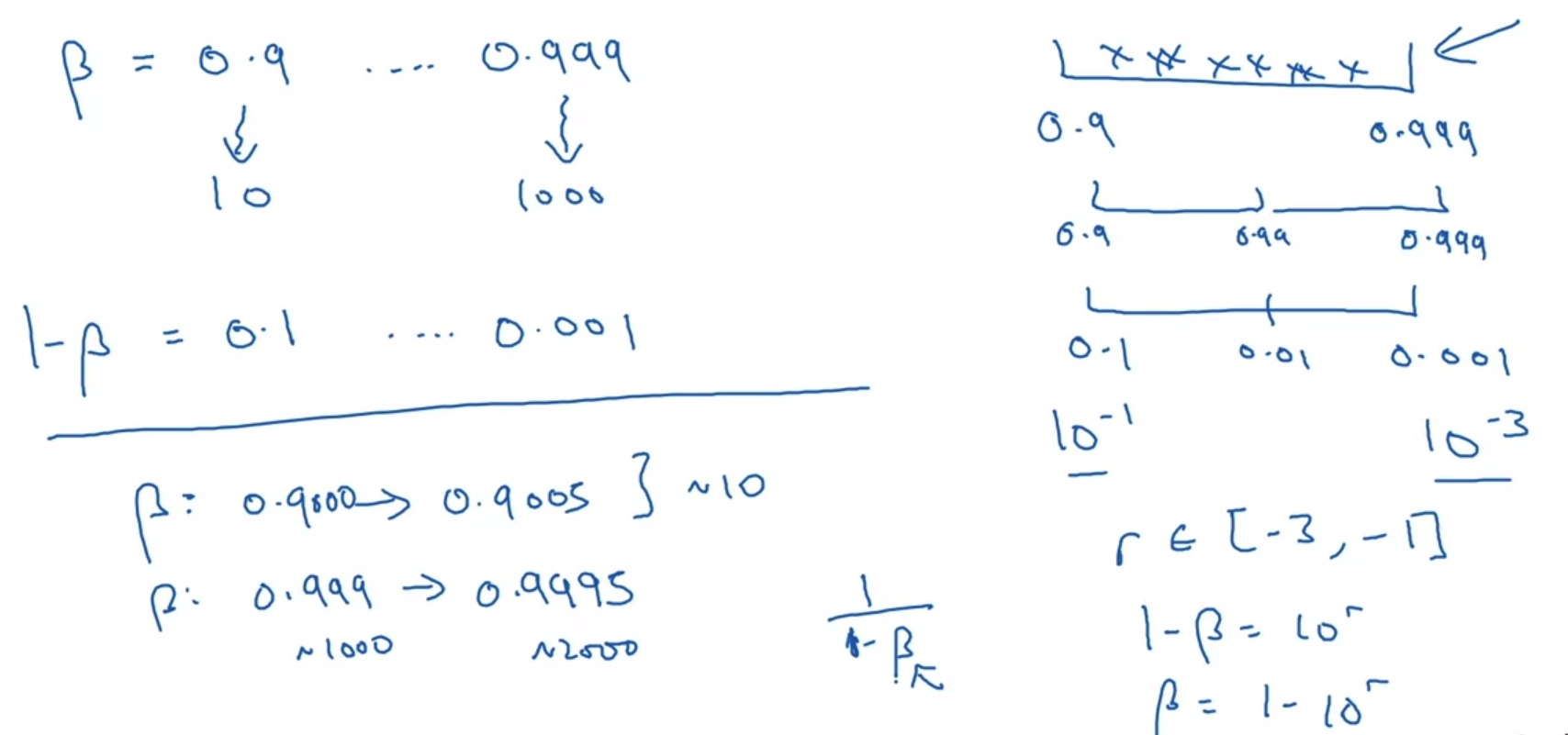
- exponentially weighted average를 구하는 경우에서는 hyperparmeter의 scale을 어떻게 정하는 것이 좋을까?
위 예시를 보면 beta의 범위를 정하게 되는 순간 1-beta의 범위가 자동적으로 정해진다.
즉, beta의 범위가 1-beta의 scale에 영향을 주는 것이다. - 이전과 동일한 논리를 적용한다면 log scale을 정해야 하는데, 문제점은 특정 구간에서 값이 변하는 정도가 크다는 것이다.
예를 들어 beta를 0.9000에서 0.9005로 바꾸는 경우에는 전체 결과에 큰 영향을 미치지 못할 것이다.
하지만 beta를 0.999에서 0.9995로 바꾸는 경우에는 전체 결과에 큰 영향을 주게 된다. - 왜냐하면 가중 평균을 구하는 과정에서 1-beta가 분모로 가게 되는데, beta가 1에 근접한 경우 분모의 값이 매우 작아지게 되므로 전체 결과값이 크게 변경되기 때문이다.
- 따라서 hyperparameter의 scale을 정하는 과정에서 어떤 수식을 사용하고 있는지에 따라 적절한 방법론을 이용해야 한다.
3. Hyperparameters Tuning in Practice : Pandas vs. Caviar
Re-test hyperparameters occasionally
- 인공지능 분야가 고도화됨에 따라 다른 분야의 지식을 습득하여 insight를 얻는 경우가 점점 많아졌다.
- 이와 같은 복잡한 상황에서는 이따금씩 현재의 hyperparameter가 최적의 세팅이 된 것이 맞는지 확인할 필요가 있다.
Pandas vs. Caviar

- y축이 cost인 그래프를 기준으로 '단 하나의 모델의 성능을 tracking 하는 경우'와 '여러 개의 모델을 동시에 돌리며 성능을 비교하는 경우'로 구분해 볼 수 있다.
- 단 하나의 개체로 의미를 지닐 수 있는 전자의 경우를 Panda, 여러 개가 모여있을 때 그 의미가 있는 후자의 경우를 Caviar로 비유한 것이다.
- 자원이 충분하여 동시에 여러 개의 모델을 돌려보고 그 성능을 tracking 할 수 있다면 그렇게 하는 것이 더 바람직하다.
하지만 초기 단계에서 간단한 수준의 확인이 필요하거나, 여러 개의 모델을 검증하는 데 필요한 자원이 갖춰지지 않은 경우엔 전자를 선택할 수밖에 없다.
'Improving Deep Neural Networks > 3주차' 카테고리의 다른 글
| Quiz & Assignment (0) | 2022.12.30 |
|---|---|
| Introduction to Programming Frameworks (0) | 2022.12.30 |
| Multi-class Classification (0) | 2022.12.24 |
| Batch Normalization (0) | 2022.12.22 |