
Self-Attention Intuition

RNN에서 사용했던 attention과 다른 attention을 도입합니다.
여기서 사용하는 self-attention은 각 단어에 대해 다른 단어와의 관계를 Q,K,V에 대한 식으로 수치화합니다.
Self-Attention
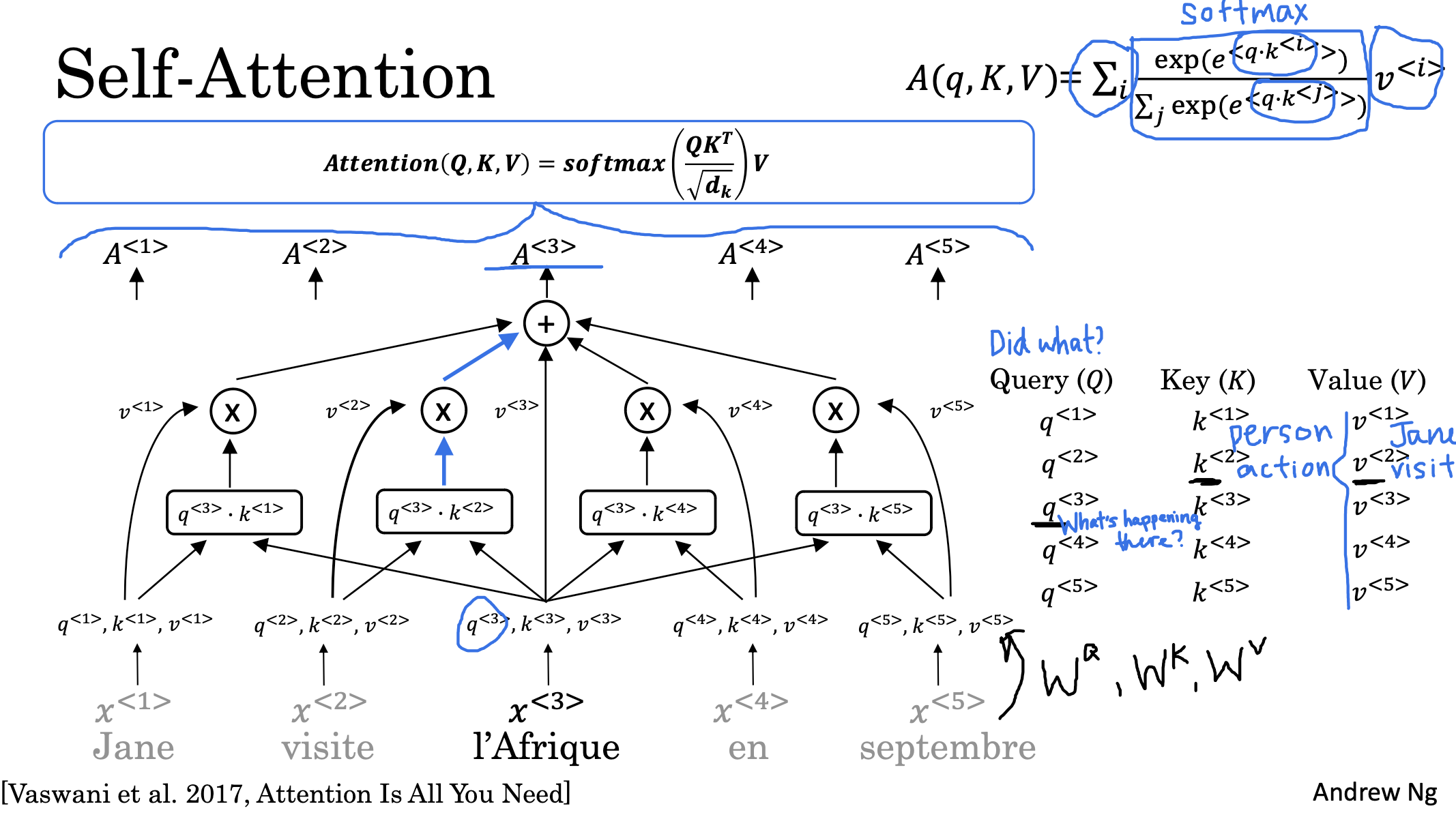
결론적으로 말하자면 Q와 K를 내적한 뒤 차원의 수로 normalize하고, 여기에 V를 곱하여 softmax를 취한 것이 attention score가 됩니다.
이때 Q, K, V는 각 입력에 대해 각각의 가중치를 가지게 됩니다.
이 수식은 Q가 일종의 질문을 의미하게 되고, 이 질문에 대한 답변 후보가 K, 그리고 이 답변이 어떤 식으로 표현되어야 하는지를 V로 정한다고 합니다.
사실 굉장히 추상적이라서 와닿지는 않아서 논문을 직접 읽어보는게 좋을 듯합니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 4주차' 카테고리의 다른 글
| Transforemrs(4) : Transformer Network (0) | 2023.04.30 |
|---|---|
| Transformers(3) : Multi-Head Attention (0) | 2023.04.30 |
| Transformers(1) : Transforemr Network Intuition (0) | 2023.04.30 |
Self-Attention Intuition
RNN에서 사용했던 attention과 다른 attention을 도입합니다.
여기서 사용하는 self-attention은 각 단어에 대해 다른 단어와의 관계를 Q,K,V에 대한 식으로 수치화합니다.
Self-Attention
결론적으로 말하자면 Q와 K를 내적한 뒤 차원의 수로 normalize하고, 여기에 V를 곱하여 softmax를 취한 것이 attention score가 됩니다.
이때 Q, K, V는 각 입력에 대해 각각의 가중치를 가지게 됩니다.
이 수식은 Q가 일종의 질문을 의미하게 되고, 이 질문에 대한 답변 후보가 K, 그리고 이 답변이 어떤 식으로 표현되어야 하는지를 V로 정한다고 합니다.
사실 굉장히 추상적이라서 와닿지는 않아서 논문을 직접 읽어보는게 좋을 듯합니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 4주차' 카테고리의 다른 글
| Transforemrs(4) : Transformer Network (0) | 2023.04.30 |
|---|---|
| Transformers(3) : Multi-Head Attention (0) | 2023.04.30 |
| Transformers(1) : Transforemr Network Intuition (0) | 2023.04.30 |