
Transformer Details
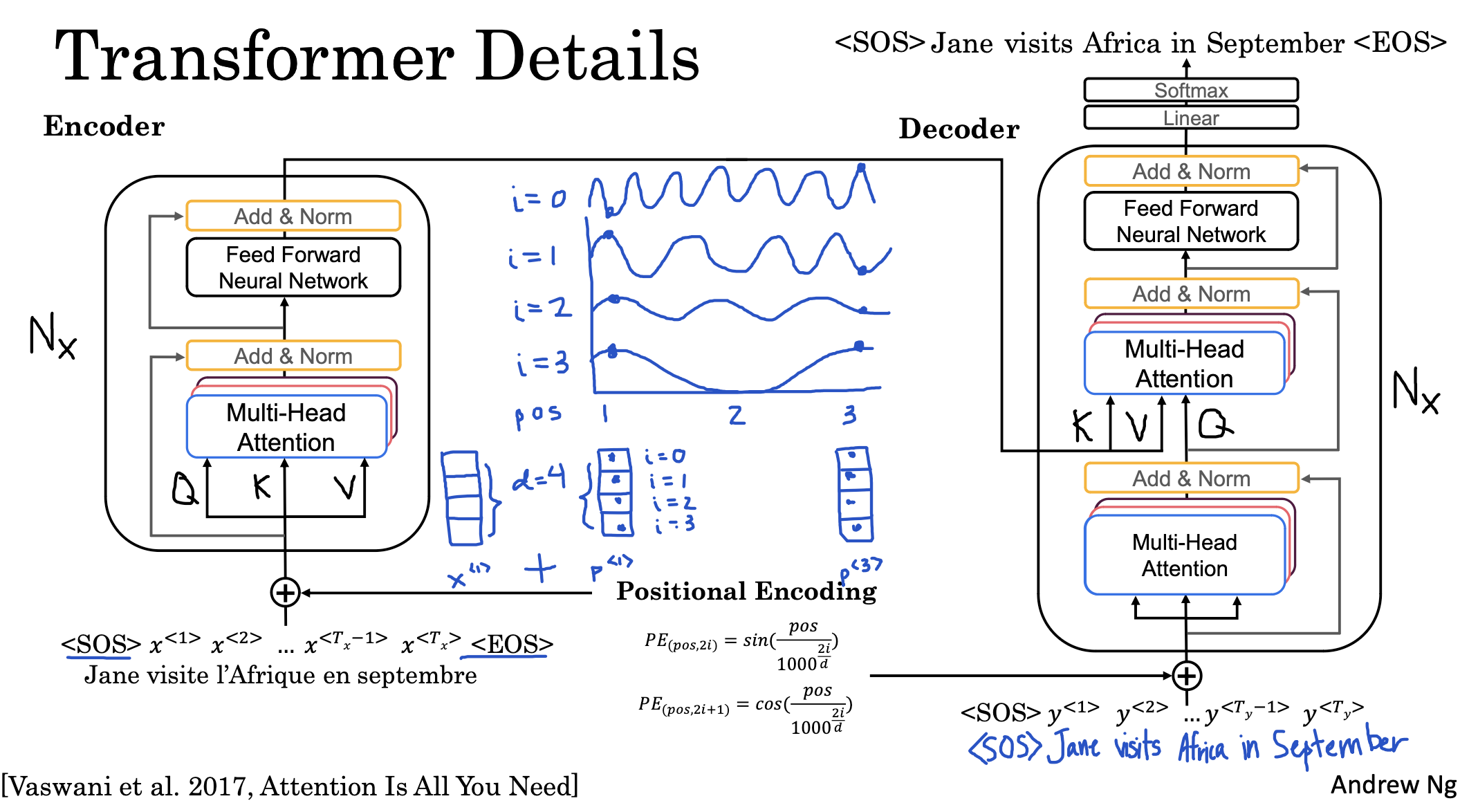
self-attention을 여러 번 중첩한 multi-head attention은 encoder / decoder 둘 다에서 쓰입니다.
encoder부터 살펴보면, 주어진 입력 문장에 대해 multi-head attention을 수행하고 이를 feed forward합니다.
이 과정을 n번 반복합니다.
(논문에서는 n=6으로 세팅했습니다)
즉, attention head를 8번 중첩해서 concat하고 forward하는 것을 6번 반복합니다.
이를 통해 입력 문장에 대해 각 단어(token) 간의 관계를 바탕으로 이해를 마칩니다.
decoder는 문장의 시작을 알리는 <SOS> 토큰으로 시작합니다.
이를 시작으로 multi-head attention을 적용하여 구한 것을 다음 multi-head attention의 Q(Query)로 사용합니다.
나머지 Key, Value는 encoder에서 가져옵니다.
따라서 생성하고자 하는 토큰 현황을 Query로 두고, 지금까지 이해한 encoder의 Key, Value를 이용하여 다음 생성할 단어를 예측하게 되는 것입니다.
이러한 transformer의 구조를 공고히 하는 몇 개의 스킬이 있습니다.
첫째로 입력 문장을 embedding 할 때 같이 주어지는 positional encoding 정보입니다.
이는 문장(차원)의 길이를 기준으로 sin, cos 함수를 그려 인덱스별로 다른 값을 갖도록 유도한 것입니다.
이를 통해 문장 내의 상대적 위치를 반영한 이해를 할 수 있도록 합니다.
또한 각 attention과 feed-forward 이후에 add & norm을 추가합니다.
강의에서는 이 부분에 대해 자세히 다루지 않고 넘어갔습니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 4주차' 카테고리의 다른 글
| Transformers(3) : Multi-Head Attention (0) | 2023.04.30 |
|---|---|
| Transformers(2) : Self-Attention (0) | 2023.04.30 |
| Transformers(1) : Transforemr Network Intuition (0) | 2023.04.30 |