
예전(2021.02)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
이미지 feature 추출에서 놓치게 되는 효율성/속도, 그리고 표현력을 보완하기 위한 방법으로 Vision-and-Language Transformer (ViLT) 모델을 고안.
image에 patch 개념을 활용하여 연산량을 획기적으로 줄일 수 있었음
- 배경
현재 대중(?)에게 가장 많이 사용되는 멀티모달 모델 중 하나인 ViLT입니다.
인공지능 모델이 서로 다른 두 modality의 정보를 이해하기 위해서는 각각의 feature embedding을 합치는 과정이 필요합니다.
즉 이미지 feature와 텍스트 feature를 적절히 조합하는 것이 중요한 것이죠.
그런데 이미지 feature를 추출할 때 생각보다 많은 자원과 시간이 요구된다는 문제점이 있었습니다.
이때 사용되는 visual backbone을 freeze하고 region feature를 미리 caching하는 전략을 사용하는데, 사실 이것은 학습 때나 학습 시간을 줄일 수 있는 전략이지, real world 데이터에 대해 추론할 때는 동일한 방식을 적용할 수 없습니다.
따라서 다른 모델들과 달리 이미지의 patch 단위로 feature를 최소한으로 뽑아내고, 이를 text feature와 interaction하는 과정에 훨씬 더 많이 집중하는 모델인 ViLT를 제시하게 됩니다.
- 특징
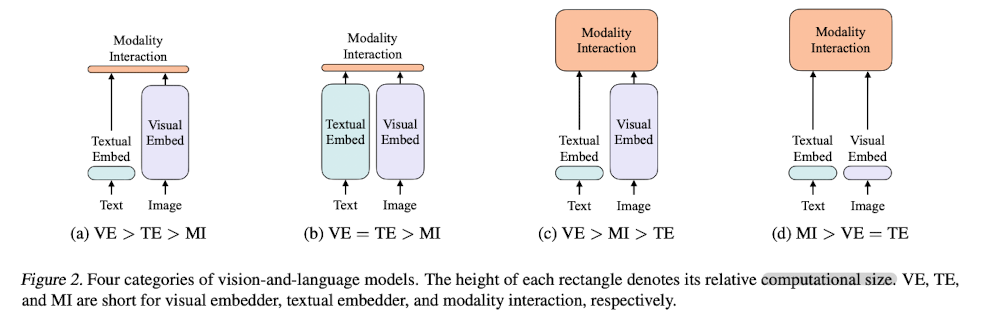
위 그림 중 가장 오른쪽에 해당합니다.(Figure 2 - d)
VE는 Visual Embedder, TE는 Text Embedder, MI는 Modality Interaction을 의미합니다.
ViLT는 interaction의 비중을 가장 크게 가져가고, 이미지와 텍스트로부터 feature를 추출하는 과정을 최소화하는 방식으로 학습되었다고 이해할 수 있습니다.
text로부터 feature를 추출할 때는 bert-base-uncased Tokenizer를 사용합니다.
사실 대부분의 multi-modal 모델이 이를 사용한다고 합니다.
(2021년도 기준이라서 현재도 유효한지는 모르겠습니다..!)
하지만 text 데이터에 대해서만 학습된 BERT 토크나이저가 image-text pair 데이터에 대해서도 동일한 성능을 낼 것이라는 보장이 없기 때문에, 사전학습된 BERT 모델을 fine-tuning하는 것 대신에 텍스트 임베딩과 관련된 파라미터인 t_class, T, T_pos를 scratch부터 학습시켰다고 합니다.
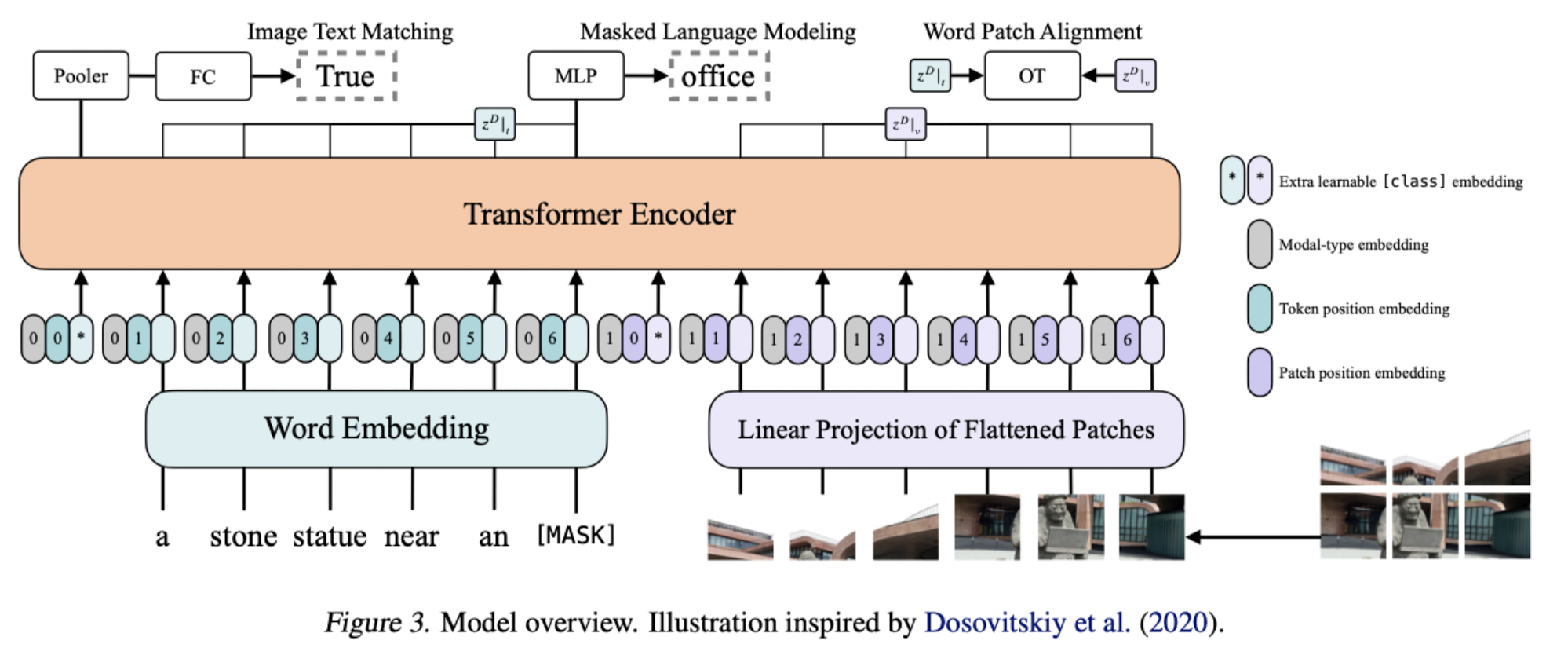
전체 모델의 아키텍쳐는 위와 같습니다.
두 modality 데이터에서 embedding을 추출합니다.
위에서 언급한 것처럼 이미지에서 feature를 추출할 때는 patch 단위로 추출하고, 이를 flatten합니다.
그리고 각 modality에 맞는 modal-type embedding vector와 sum하여 transformer encoder에 넣습니다.
한편 세 개의 Pretraining Objectives가 Image Text Matching, Masked Language Modeling, Word Patch Alignment인 것을 알 수 있습니다.
- 개인적 감상
확실히 멀티모달 분야의 논문은 읽을 땐 쉽고 막상 쓰려고 하면 어려운 것 같습니다.
개념 자체는 어렵지 않은 것 같은데, 의외로 각 modality 처리하는 것도 어렵고 둘을 이어주는게 코드상으로는 굉장히 어렵다는 걸 최근 경험을 통해서 다시 한 번 느끼게 됐거든요..
이 모델을 특정 태스크에 fine-tuning한 weight가 여럿 공개되어 있고 많이 사용되는 것으로 알고 있는데, 다른 모델들과의 차이점도 공부할 필요가 있는 것 같습니다.
특히 patch 개념이 최근에 문서 관련 멀티모달 분야에도 자주 활용되는 것으로 들었는데 알아볼 가치가 충분한 것 같습니다.
출처 : https://arxiv.org/abs/2102.03334
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object dete
arxiv.org
'Paper Review' 카테고리의 다른 글
예전(2021.02)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
이미지 feature 추출에서 놓치게 되는 효율성/속도, 그리고 표현력을 보완하기 위한 방법으로 Vision-and-Language Transformer (ViLT) 모델을 고안.
image에 patch 개념을 활용하여 연산량을 획기적으로 줄일 수 있었음
- 배경
현재 대중(?)에게 가장 많이 사용되는 멀티모달 모델 중 하나인 ViLT입니다.
인공지능 모델이 서로 다른 두 modality의 정보를 이해하기 위해서는 각각의 feature embedding을 합치는 과정이 필요합니다.
즉 이미지 feature와 텍스트 feature를 적절히 조합하는 것이 중요한 것이죠.
그런데 이미지 feature를 추출할 때 생각보다 많은 자원과 시간이 요구된다는 문제점이 있었습니다.
이때 사용되는 visual backbone을 freeze하고 region feature를 미리 caching하는 전략을 사용하는데, 사실 이것은 학습 때나 학습 시간을 줄일 수 있는 전략이지, real world 데이터에 대해 추론할 때는 동일한 방식을 적용할 수 없습니다.
따라서 다른 모델들과 달리 이미지의 patch 단위로 feature를 최소한으로 뽑아내고, 이를 text feature와 interaction하는 과정에 훨씬 더 많이 집중하는 모델인 ViLT를 제시하게 됩니다.
- 특징
위 그림 중 가장 오른쪽에 해당합니다.(Figure 2 - d)
VE는 Visual Embedder, TE는 Text Embedder, MI는 Modality Interaction을 의미합니다.
ViLT는 interaction의 비중을 가장 크게 가져가고, 이미지와 텍스트로부터 feature를 추출하는 과정을 최소화하는 방식으로 학습되었다고 이해할 수 있습니다.
text로부터 feature를 추출할 때는 bert-base-uncased Tokenizer를 사용합니다.
사실 대부분의 multi-modal 모델이 이를 사용한다고 합니다.
(2021년도 기준이라서 현재도 유효한지는 모르겠습니다..!)
하지만 text 데이터에 대해서만 학습된 BERT 토크나이저가 image-text pair 데이터에 대해서도 동일한 성능을 낼 것이라는 보장이 없기 때문에, 사전학습된 BERT 모델을 fine-tuning하는 것 대신에 텍스트 임베딩과 관련된 파라미터인 t_class, T, T_pos를 scratch부터 학습시켰다고 합니다.
전체 모델의 아키텍쳐는 위와 같습니다.
두 modality 데이터에서 embedding을 추출합니다.
위에서 언급한 것처럼 이미지에서 feature를 추출할 때는 patch 단위로 추출하고, 이를 flatten합니다.
그리고 각 modality에 맞는 modal-type embedding vector와 sum하여 transformer encoder에 넣습니다.
한편 세 개의 Pretraining Objectives가 Image Text Matching, Masked Language Modeling, Word Patch Alignment인 것을 알 수 있습니다.
- 개인적 감상
확실히 멀티모달 분야의 논문은 읽을 땐 쉽고 막상 쓰려고 하면 어려운 것 같습니다.
개념 자체는 어렵지 않은 것 같은데, 의외로 각 modality 처리하는 것도 어렵고 둘을 이어주는게 코드상으로는 굉장히 어렵다는 걸 최근 경험을 통해서 다시 한 번 느끼게 됐거든요..
이 모델을 특정 태스크에 fine-tuning한 weight가 여럿 공개되어 있고 많이 사용되는 것으로 알고 있는데, 다른 모델들과의 차이점도 공부할 필요가 있는 것 같습니다.
특히 patch 개념이 최근에 문서 관련 멀티모달 분야에도 자주 활용되는 것으로 들었는데 알아볼 가치가 충분한 것 같습니다.
출처 : https://arxiv.org/abs/2102.03334
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object dete
arxiv.org