
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
attention layer가 key, value 쌍으로 이루어진 외부 메모리에 접근.
이를 통해 훨씬 더 긴 입력을 받을 수 있고, 여러 개의 문서에 대해 retrieval 할 수 있게 됨.
이 방식을 Focused Transforemr(FoT)라고 하며, OpenLLaMA(3B, 7B) 대상으로 tuning한 모델, LONGLLAMA를 공개.
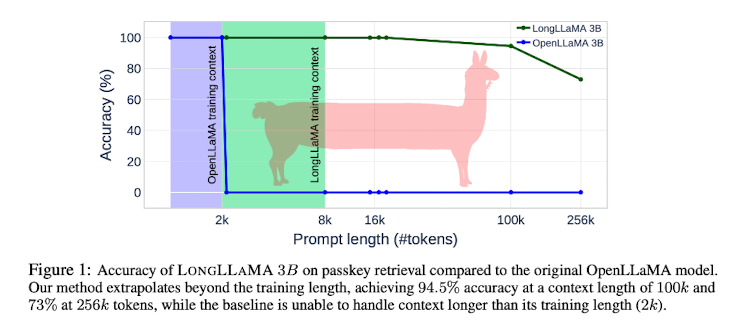
- 배경
LLM은 그 능력이 엄청나지만 의외로 특정 분야에 한정된다는 문제점을 안고 있습니다.
엄청난 양의 데이터와 자원으로 한 번 학습되면, 이를 확장하는 것이 쉽지 않다는 뜻입니다.
이를 해결할 수 있는 방식 중 하나가 외부 메모리에 접근하는 것인데, 이것조차도 사실은 LLM이 한 번에 처리할 수 있는 입력의 길이 제한이 있기 때문에 명쾌한 해답은 아닙니다.
본 논문에서는 이 문제의 가장 핵심적인 원인을 ‘distraction issue’ 로 보고 있습니다.
다른 문서나 자료를 참고할 때, 문서의 양이 많아지면서 query와 관련 없는 문서의 비중이 높아지게 되고, 결국 query와 관련 있는 것과 없는 것을 구분하는 능력이 사라지게 된다는 것이죠.
이를 극복하기 위해 제시된 방법이 Focused Transforemr(FoT)입니다.
- 두 가지 핵심 요소 : memory attention layers, crossbatch training procedure
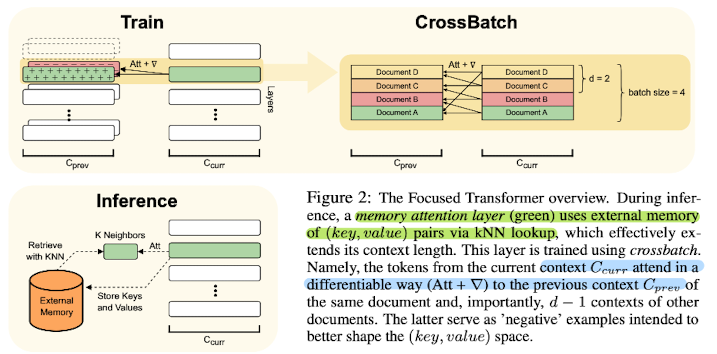
도식에서 초록색으로 표현되는 memory attention layer는 kNN 알고리즘을 통해 외부 메모리를 참조하게 됩니다.
이 layer는 crossbatch를 이용하여 학습됩니다.
이는 현재의 context의 토큰이 이전 context에 대해 미분가능한 방식으로 관여한다는 뜻입니다.
흥미로운 것은 위 아이디어에 contrastive learning 개념이 자리잡고 있다는 것입니다.
배경에서 설명한 것처럼 query와 관련이 있는지 없는지를 구분하는 것의 난이도가 높아지는 것이 문제의 핵심 원인이므로, 그 둘을 잘 구분할 수 있도록 하는 것이죠.
contrastive learning은 간단히 말하자면 positive, negative끼리 각각 가까운 embedding vector를 갖게 하는 학습 방식입니다.
따라서 key, value로 구성되는 외부 메모리의 key를 positive, negative로 각각 구성하고 crossbatch를 적용하는 focused attention으로 distraction issue를 극복 가능하다고 보는 것이 논문의 입장입니다.
또다른 특징으로는 이전의 연구들과 달리 positional encoding을 사용하지 않고 학습 단계에서는 토큰 제한을 두었음에도 불구하고, 256K 토큰까지 처리가 가능한 모델로 tuning이 가능하다는 것을 확인했습니다.
정확히는 positional encoding을 local context로서 저장은 해두는데, 이는 기존 LLaMA의 방식과 호환될 수 있도록 한 것이라고 합니다.
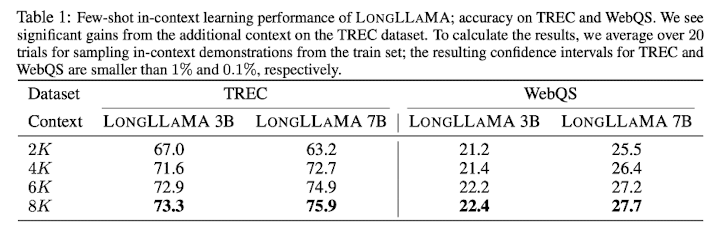
모델의 long context 처리 성능을 확인하는 것은 TREC, WebQA 두 데이터셋을 이용해 이뤄졌습니다.
- 개인적 감상
최근 LLM 관련 연구 중 가장 핫한 것은 입력 길이 제한을 극복하는 것 같습니다.
개인적으로는 지금 모델이 받는 입력의 크기도 작지 않다고 생각하고, 이를 처리하는 속도도 사실 굉장히 빠르다고 느끼는데, 도대체 어디까지 발전할지 모르겠습니다.
어느정도 수준에 이르면 사실 문서를 읽는 작업들이 굉장히 간단, 수월해지고 엄청 효율적으로 작업할 수 있을텐데요..
‘생성’ 모델로 ‘이해’를 해야하는 상황이 흥미롭게 느껴집니다.
한편 이렇게 외부 문서를 참조하는 방식은 외부 API를 활용하는 방식과 결이 비슷하다는 생각도 듭니다.
오히려 적절한 외부 API를 사용할 수 있도록 알고리즘을 설계하거나 모델이 학습하게 된다면 본 논문의 방식보다 더 효율적일수도 있지 않을까 생각합니다.
그리고 어떤 방식이든지간에 이렇게 long context/sequence를 처리하는 것이라면 이에 대한 평가가 지금보다 더 엄격하고 철저하게 이뤄져야 할 것으로 보입니다.
Focused Transformer: Contrastive Training for Context Scaling
Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
attention layer가 key, value 쌍으로 이루어진 외부 메모리에 접근.
이를 통해 훨씬 더 긴 입력을 받을 수 있고, 여러 개의 문서에 대해 retrieval 할 수 있게 됨.
이 방식을 Focused Transforemr(FoT)라고 하며, OpenLLaMA(3B, 7B) 대상으로 tuning한 모델, LONGLLAMA를 공개.
- 배경
LLM은 그 능력이 엄청나지만 의외로 특정 분야에 한정된다는 문제점을 안고 있습니다.
엄청난 양의 데이터와 자원으로 한 번 학습되면, 이를 확장하는 것이 쉽지 않다는 뜻입니다.
이를 해결할 수 있는 방식 중 하나가 외부 메모리에 접근하는 것인데, 이것조차도 사실은 LLM이 한 번에 처리할 수 있는 입력의 길이 제한이 있기 때문에 명쾌한 해답은 아닙니다.
본 논문에서는 이 문제의 가장 핵심적인 원인을 ‘distraction issue’ 로 보고 있습니다.
다른 문서나 자료를 참고할 때, 문서의 양이 많아지면서 query와 관련 없는 문서의 비중이 높아지게 되고, 결국 query와 관련 있는 것과 없는 것을 구분하는 능력이 사라지게 된다는 것이죠.
이를 극복하기 위해 제시된 방법이 Focused Transforemr(FoT)입니다.
- 두 가지 핵심 요소 : memory attention layers, crossbatch training procedure
도식에서 초록색으로 표현되는 memory attention layer는 kNN 알고리즘을 통해 외부 메모리를 참조하게 됩니다.
이 layer는 crossbatch를 이용하여 학습됩니다.
이는 현재의 context의 토큰이 이전 context에 대해 미분가능한 방식으로 관여한다는 뜻입니다.
흥미로운 것은 위 아이디어에 contrastive learning 개념이 자리잡고 있다는 것입니다.
배경에서 설명한 것처럼 query와 관련이 있는지 없는지를 구분하는 것의 난이도가 높아지는 것이 문제의 핵심 원인이므로, 그 둘을 잘 구분할 수 있도록 하는 것이죠.
contrastive learning은 간단히 말하자면 positive, negative끼리 각각 가까운 embedding vector를 갖게 하는 학습 방식입니다.
따라서 key, value로 구성되는 외부 메모리의 key를 positive, negative로 각각 구성하고 crossbatch를 적용하는 focused attention으로 distraction issue를 극복 가능하다고 보는 것이 논문의 입장입니다.
또다른 특징으로는 이전의 연구들과 달리 positional encoding을 사용하지 않고 학습 단계에서는 토큰 제한을 두었음에도 불구하고, 256K 토큰까지 처리가 가능한 모델로 tuning이 가능하다는 것을 확인했습니다.
정확히는 positional encoding을 local context로서 저장은 해두는데, 이는 기존 LLaMA의 방식과 호환될 수 있도록 한 것이라고 합니다.
모델의 long context 처리 성능을 확인하는 것은 TREC, WebQA 두 데이터셋을 이용해 이뤄졌습니다.
- 개인적 감상
최근 LLM 관련 연구 중 가장 핫한 것은 입력 길이 제한을 극복하는 것 같습니다.
개인적으로는 지금 모델이 받는 입력의 크기도 작지 않다고 생각하고, 이를 처리하는 속도도 사실 굉장히 빠르다고 느끼는데, 도대체 어디까지 발전할지 모르겠습니다.
어느정도 수준에 이르면 사실 문서를 읽는 작업들이 굉장히 간단, 수월해지고 엄청 효율적으로 작업할 수 있을텐데요..
‘생성’ 모델로 ‘이해’를 해야하는 상황이 흥미롭게 느껴집니다.
한편 이렇게 외부 문서를 참조하는 방식은 외부 API를 활용하는 방식과 결이 비슷하다는 생각도 듭니다.
오히려 적절한 외부 API를 사용할 수 있도록 알고리즘을 설계하거나 모델이 학습하게 된다면 본 논문의 방식보다 더 효율적일수도 있지 않을까 생각합니다.
그리고 어떤 방식이든지간에 이렇게 long context/sequence를 처리하는 것이라면 이에 대한 평가가 지금보다 더 엄격하고 철저하게 이뤄져야 할 것으로 보입니다.
Focused Transformer: Contrastive Training for Context Scaling
Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue
arxiv.org