
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Standford University]
multi-document QA와 key-value retireval에서, query와 관련된 정보가 context의 시작, 또는 끝에 위치하는 것이 유리하다.
이 경향은 context가 길어질수록 명확해지기 때문에, context의 길이를 x축으로 삼고 모델 성능을 y축으로 삼는 그래프는 U자 curve로 그려진다.
- 배경
최근 LLM을 언급하면 빠질 수 없는 이야기는 처리 가능한 입력 길이입니다.
이를 늘리기 위해서 다양한 연구가 이뤄지고 있는데, 실제로 참조해야 할 문서가 많아질수록 모델의 성능이 떨어진다는 연구가 등장했습니다.
결국 엄청나게 긴 입력을 모델에게 주기 위해서는 입력의 배치나 순서 또한 중요한 고려 대상이 된다는 것이 객관적으로 입증되는 듯합니다.
모델 성능 자체에 치명적인 영향을 준다는 것이 밝혀지긴 했었지만, 구체적으로 핵심 정보가 중간에 배치될 경우 그러한 경향이 심화된다는 것, 또한 이런 경향성이 일관적이라는 것을 밝힌 것에 의의가 있는 논문으로 보입니다.
- 분서 결과 및 특징
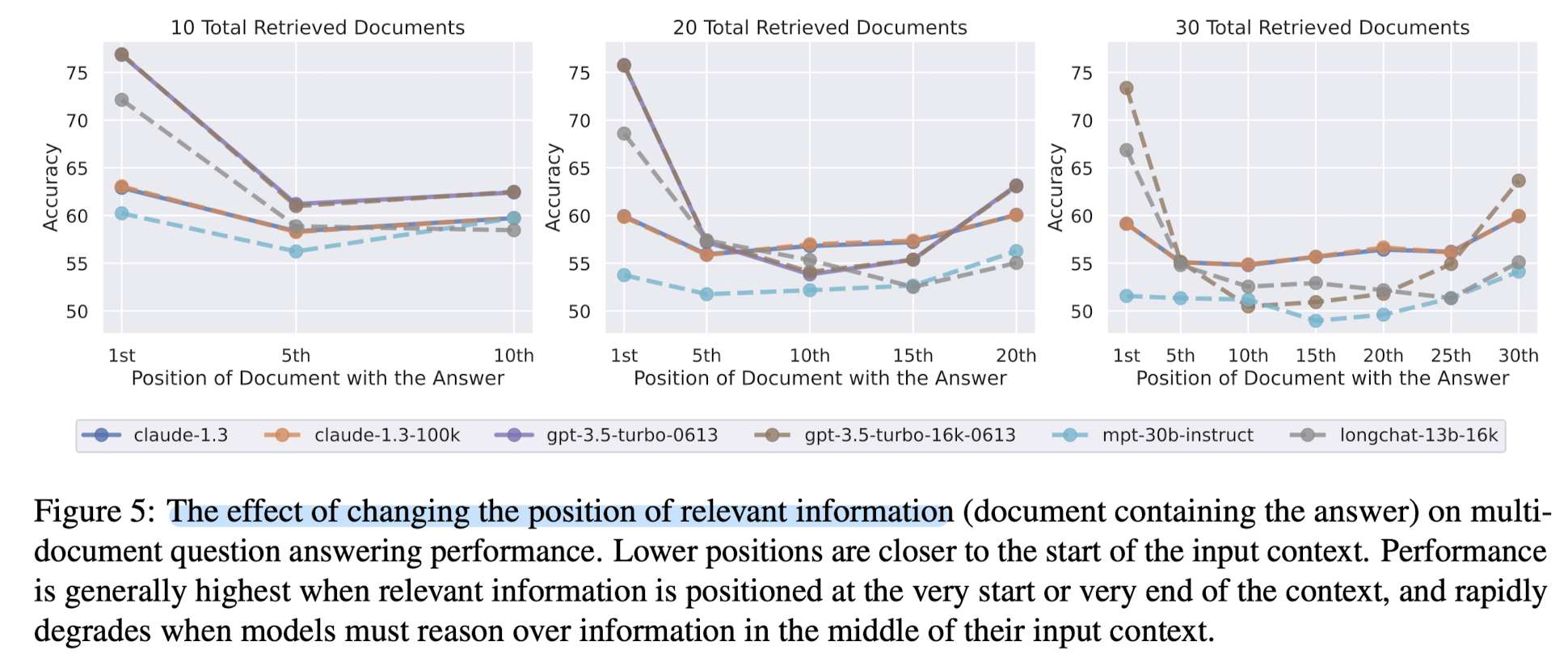
그래프를 참고하면 훨씬 이해가 쉬울 것 같습니다.
위의 그래프에서는 문서 내 정답의 위치에 따른 정확도를 나타내고 있습니다.
문서의 개수가 각각 10, 20, 30개일 때, 20개 이상의 문서가 존재하면 확실히 정답이 중간에 위치할수록 모델의 정확도가 낮아지는 경향이 나타납니다.
즉, 정답이 처음이나 마지막에 위치하는 것이 모델의 입장에서 유리하다는 뜻입니다.
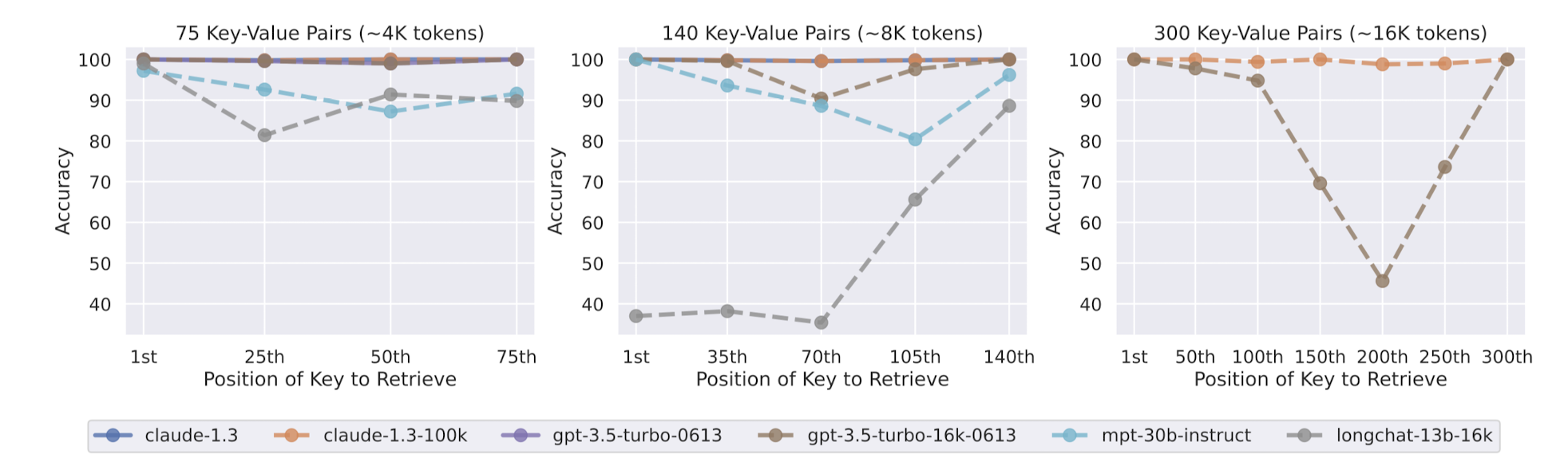
이러한 경향은 태스크를 key-value retireval로 치환해도 동일하게 나타납니다.
확실하게 알 수 있는 것은 어쨌든 모델이 찾아봐야 하는 정보의 양이 늘어날수록 정확도가 낮을 가능성이 높다는 것이죠.
다시 말하자면, 모델에게 더 많은 context를 제공하는 것이 더 좋을까?
라는 질문에, 반드시 yes라고 대답할 수는 없다는 것입니다.
이러한 관점에서는 검색 엔진을 대체할 LLM이 몇 개의 문서를 대상으로, 몇 개의 후보를 뽑을지를 정하는데 영향을 줄 결과라고도 볼 수 있겠습니다.
또한 논문에서는 instruction 모델과 base모델(mpt-30b-instruct vs mpt-30b)을 비교한 내용, 그리고 encoder-decoder 모델과 decoder-only 모델(Flan-T5 vs GPT-3.5)을 비교한 내용들을 다루고 있습니다.
본 논문에서 가장 흥미로웠던 점 중 하나는 바로 이러한 경향이 사람의 기억 패턴과 유사하다는 점입니다.
심리학 분야에 serial-position effect라는 것이 있는데 이는 사람이 어떤 목록의 첫 번째와 마지막 요소를 잘 기억할 가능성이 높다는 것을 연구한 결과라고 합니다.
한편으로는 transformer 기반의 모델들은 상대적 위치 정보를 기반으로 한꺼번에 연산을 수행하다보니 이런 경향성이 낮은데, 재밌는 경향성이라는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2307.03172
Lost in the Middle: How Language Models Use Long Contexts
While recent language models have the ability to take long contexts as input, relatively little is known about how well the language models use longer context. We analyze language model performance on two tasks that require identifying relevant information
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Standford University]
multi-document QA와 key-value retireval에서, query와 관련된 정보가 context의 시작, 또는 끝에 위치하는 것이 유리하다.
이 경향은 context가 길어질수록 명확해지기 때문에, context의 길이를 x축으로 삼고 모델 성능을 y축으로 삼는 그래프는 U자 curve로 그려진다.
- 배경
최근 LLM을 언급하면 빠질 수 없는 이야기는 처리 가능한 입력 길이입니다.
이를 늘리기 위해서 다양한 연구가 이뤄지고 있는데, 실제로 참조해야 할 문서가 많아질수록 모델의 성능이 떨어진다는 연구가 등장했습니다.
결국 엄청나게 긴 입력을 모델에게 주기 위해서는 입력의 배치나 순서 또한 중요한 고려 대상이 된다는 것이 객관적으로 입증되는 듯합니다.
모델 성능 자체에 치명적인 영향을 준다는 것이 밝혀지긴 했었지만, 구체적으로 핵심 정보가 중간에 배치될 경우 그러한 경향이 심화된다는 것, 또한 이런 경향성이 일관적이라는 것을 밝힌 것에 의의가 있는 논문으로 보입니다.
- 분서 결과 및 특징
그래프를 참고하면 훨씬 이해가 쉬울 것 같습니다.
위의 그래프에서는 문서 내 정답의 위치에 따른 정확도를 나타내고 있습니다.
문서의 개수가 각각 10, 20, 30개일 때, 20개 이상의 문서가 존재하면 확실히 정답이 중간에 위치할수록 모델의 정확도가 낮아지는 경향이 나타납니다.
즉, 정답이 처음이나 마지막에 위치하는 것이 모델의 입장에서 유리하다는 뜻입니다.
이러한 경향은 태스크를 key-value retireval로 치환해도 동일하게 나타납니다.
확실하게 알 수 있는 것은 어쨌든 모델이 찾아봐야 하는 정보의 양이 늘어날수록 정확도가 낮을 가능성이 높다는 것이죠.
다시 말하자면, 모델에게 더 많은 context를 제공하는 것이 더 좋을까?
라는 질문에, 반드시 yes라고 대답할 수는 없다는 것입니다.
이러한 관점에서는 검색 엔진을 대체할 LLM이 몇 개의 문서를 대상으로, 몇 개의 후보를 뽑을지를 정하는데 영향을 줄 결과라고도 볼 수 있겠습니다.
또한 논문에서는 instruction 모델과 base모델(mpt-30b-instruct vs mpt-30b)을 비교한 내용, 그리고 encoder-decoder 모델과 decoder-only 모델(Flan-T5 vs GPT-3.5)을 비교한 내용들을 다루고 있습니다.
본 논문에서 가장 흥미로웠던 점 중 하나는 바로 이러한 경향이 사람의 기억 패턴과 유사하다는 점입니다.
심리학 분야에 serial-position effect라는 것이 있는데 이는 사람이 어떤 목록의 첫 번째와 마지막 요소를 잘 기억할 가능성이 높다는 것을 연구한 결과라고 합니다.
한편으로는 transformer 기반의 모델들은 상대적 위치 정보를 기반으로 한꺼번에 연산을 수행하다보니 이런 경향성이 낮은데, 재밌는 경향성이라는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2307.03172
Lost in the Middle: How Language Models Use Long Contexts
While recent language models have the ability to take long contexts as input, relatively little is known about how well the language models use longer context. We analyze language model performance on two tasks that require identifying relevant information
arxiv.org