
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[GenAI, Meta]
LLaMA 모델을 발전시킨 LLaMA 2 모델과, 이를 대화 형식으로 fine-tuning한 LLaMA 2-CHAT 모델을 공개.
모델의 파라미터 개수는 7B부터 70B까지 다양함.
배경
ChatGPT를 필두로 LLM이 큰 주목을 받게 되었지만, 요즘은 사실 이 Meta에서 개발한 LLaMA 모델의 영향이 더욱 크다고 생각합니다.
OpenAI는 회사의 이름과 다르게 자신들의 기술을 베일 속에 꽁꽁 감춰두었고, 이런 기업들과 달리 Meta는 자신들의 모델 LLaMA를 오픈소스로 공개했죠.
물론 출시 초반에 모델의 가중치가 토렌트를 통해 공유되었던 것은 본인들의 의도한 바는 아니겠지만요.
어쨌든 LLaMA 모델이 파라미터 사이즈에 비해서 엄청나게 좋은 성능을 보여주면서 이런 모델을 backbone으로 삼아 tuning하는 연구들이 굉장히 많이 이뤄졌습니다.
스탠포드 대학에서 개발한 Alpaca도 엄청난 화제였고, ShareGPT라는 사이트에서 ChatGPT 유저들의 채팅 기록을 학습 데이터로 사용해 개발한 Vicuna도 크게 주목 받았죠.
하나 아쉬운 점으로 지적되었던 것이 이 모델을 상업적으로 이용할 수 없다는 것이었죠.
개인적으로는 이렇게 공개해준 것만으로 어디냐 싶기도 했지만, 이왕.. 오픈하는거 자유롭게 이용하면 더 좋겠다는 의견이 지배적이었습니다.
실제로 Meta의 깃허브에 상업적으로 이용가능하게끔 배포해달라는 요청도 굉장히 많았구요.
그런데 이번에는 상업적으로 이용 가능하면서도, 기존보다 성능도 더 우월한 모델을 개발하여 공개했다고 합니다.
수많은 연구자/개발자들이 여기에 관심을 갖고 있고, 빠른 속도로 결과물들을 공유하고 있는 상황입니다.
그래서 오늘은 아주 얕은 수준으로 LLaMA 2 페이퍼에 나타난 내용들을 최대한 간단히 정리하고자 합니다.
특징
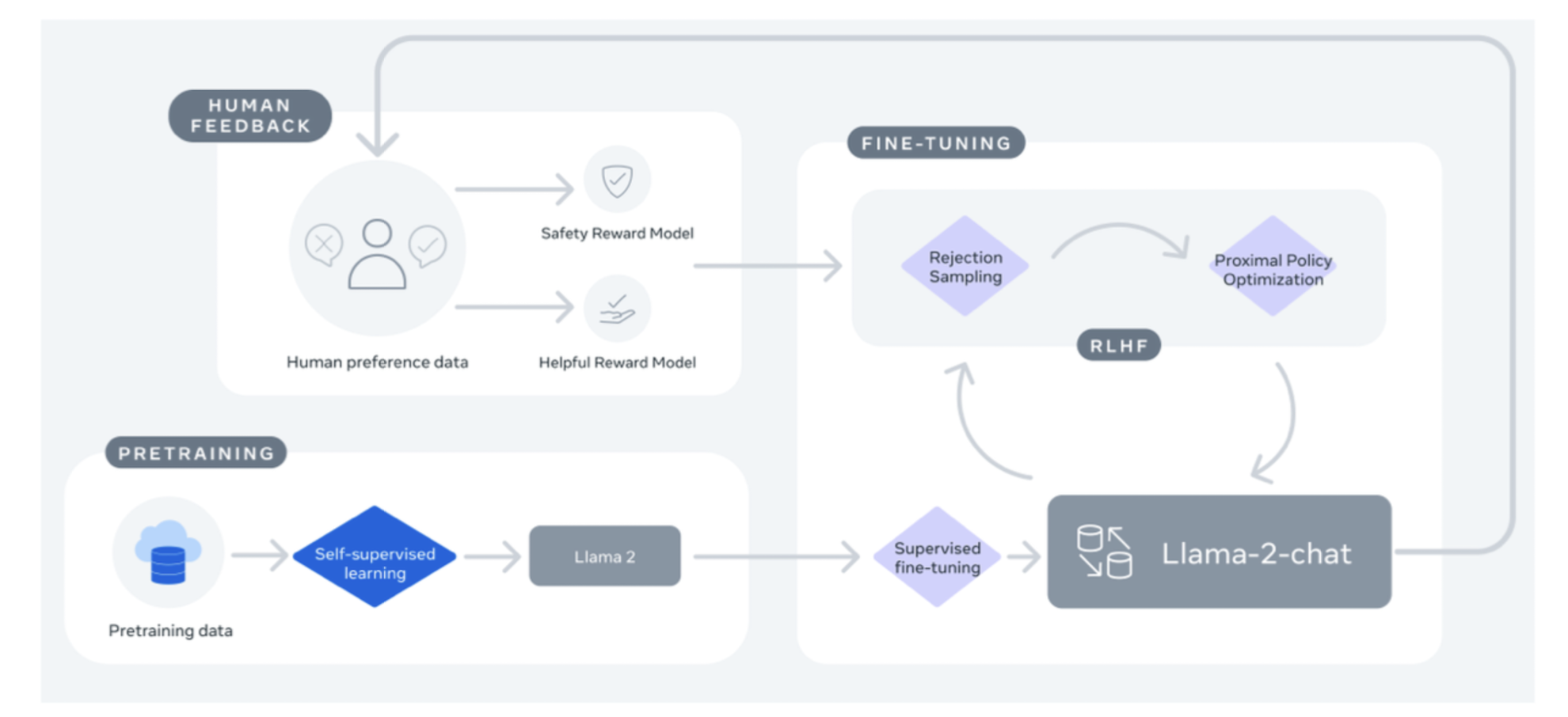
당연히 instruction tuning과 RLHF(Reinforcement Learning with Human Feedback)가 적용되었습니다.
이때 rejection sampling과 PPO(Proximal Policy Optimization)이 핵심 테크닉입니다.
- 사전 학습
public하게 이용 가능한 데이터를 사용했다고 합니다.
사용된 데이터의 양은 2T(Trillion) token입니다.
학습 방식에 대해 LLaMA 1과 비교하면, 입력으로 받는 context의 길이가 길어졌다는 것과 GQA(grouped-query attention)를 적용했다는 차이점이 있습니다.
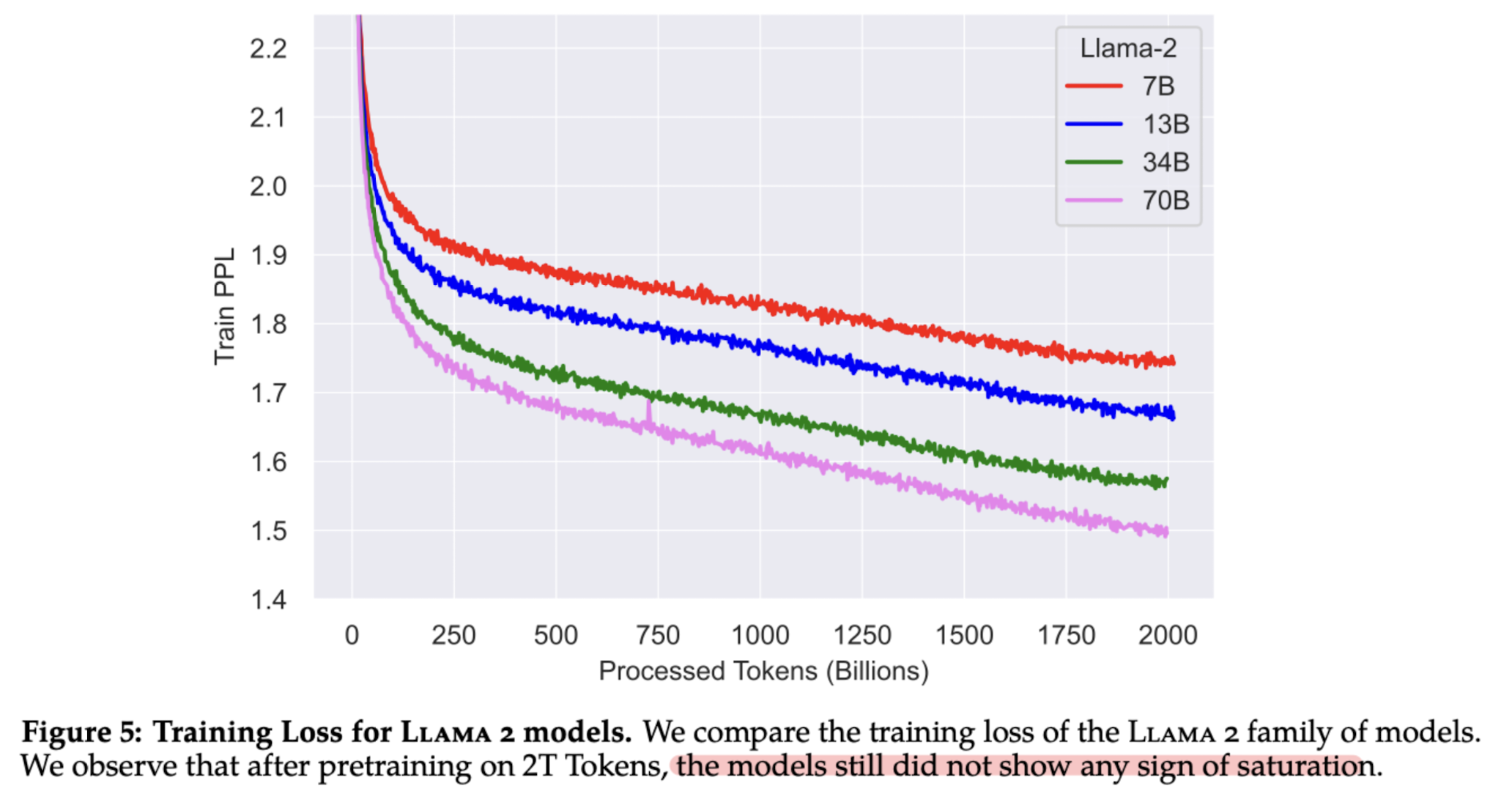
LLaMA 2 모델의 training loss를 시각화한 결과입니다.
그래프를 보면 알 수 있는 것처럼, 모델의 능력이 아직 포화상태에 이르지 않았습니다.
즉, 사이즈를 키우면 성능이 더 증가할 여지가 남아있다고 볼 수 있습니다.
- 모델 평가
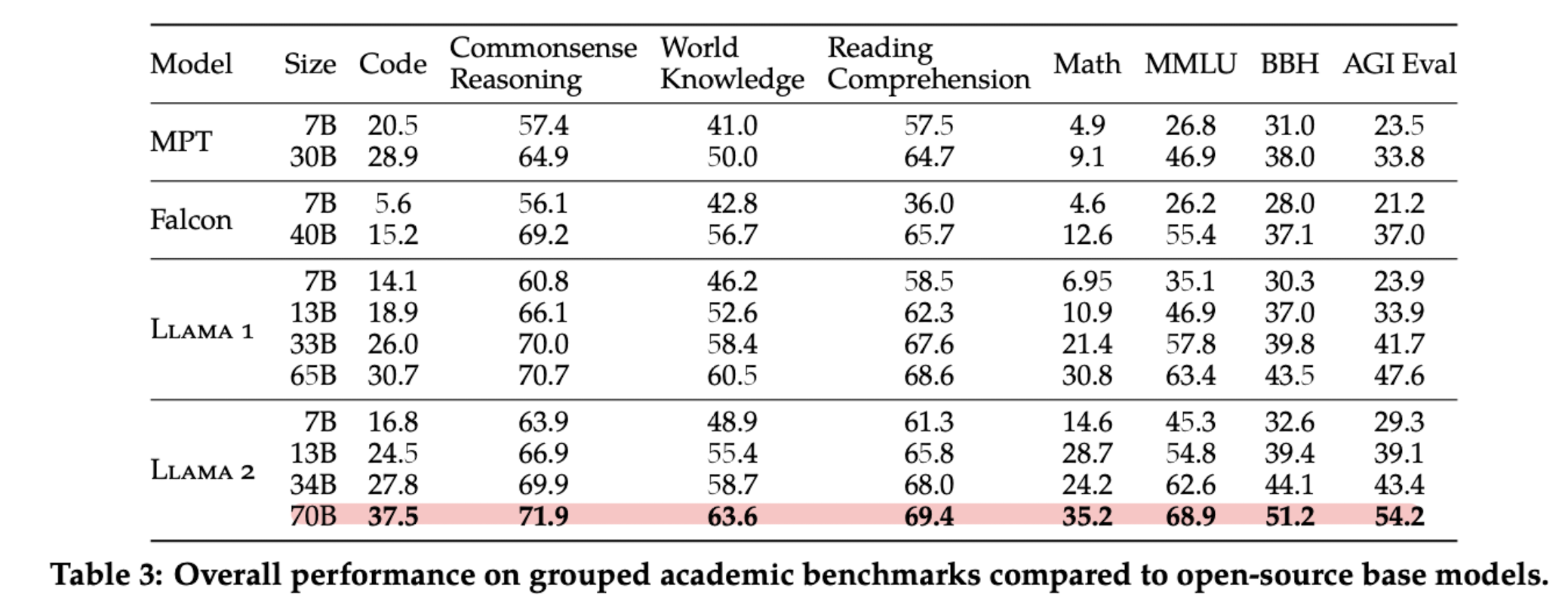
MPT(MosaicML Pretrained Transformer), Falcon 모델들과 비교한 결과를 공개했습니다.
평가 대상이 되는 태스크들은 ‘Code, Commonsense Reasoning, World Knowledge, Reading Comprehension, MATH, Popular Aggregated Benchmarks’ 등입니다.
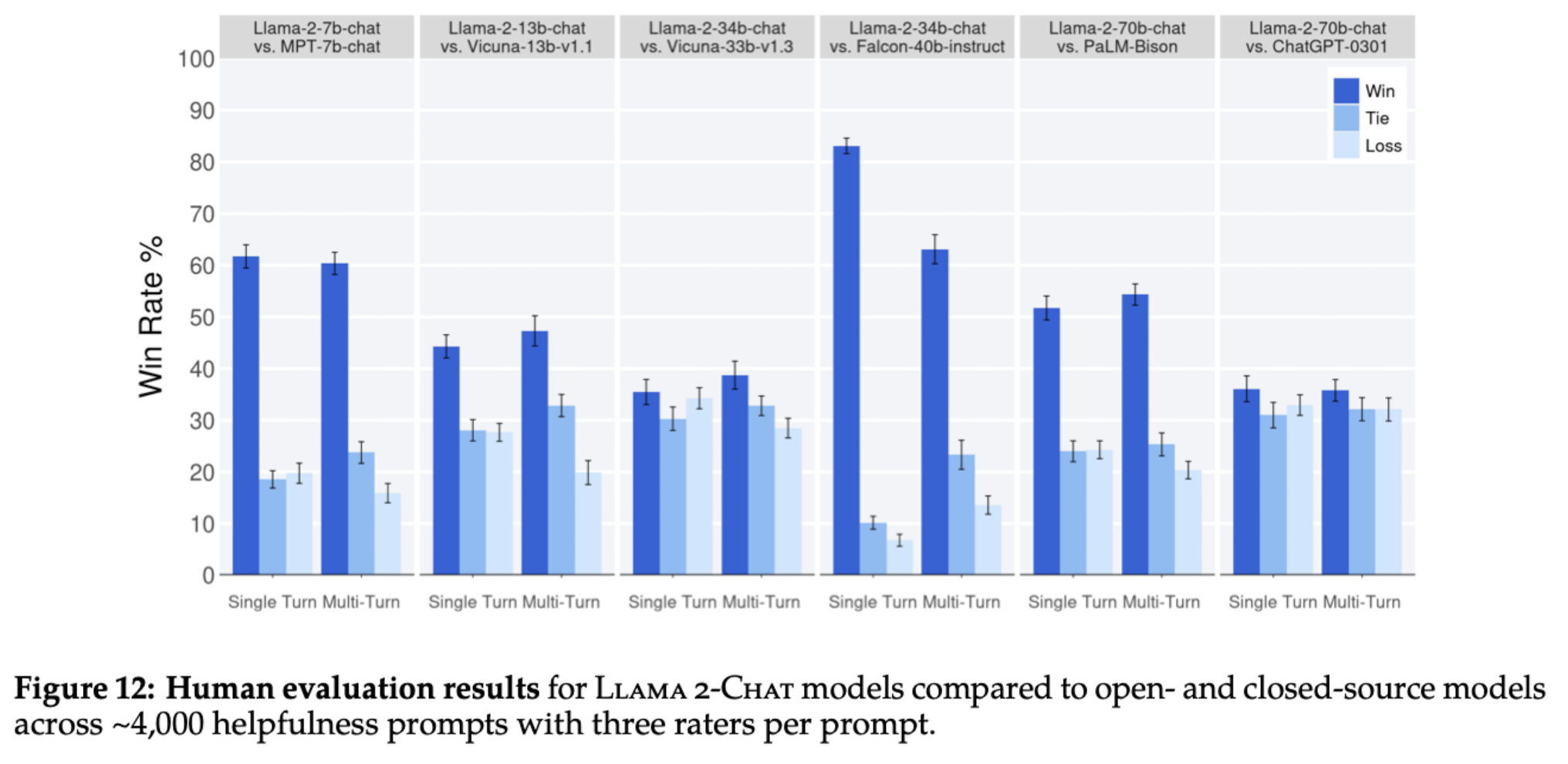
동일한 요청에 대해 여러 모델이 생성한 결과를 제시하고, 그중에 가장 선호되는 것을 파악한 결과입니다.
single-turn, multi-turn 둘 다 비교한 결과, LLaMA 2-CHAT은 오픈 소스 모델들(예를 들어 Falcon, MPT)에 비해 우월한 성능을 보여주었고, ChatGPT와의 비교에서는 이와 비등한 수준으로 확인되었습니다.
- Multi-Turn Consistency
챗봇의 경우 여러 턴의 대화가 이어지면 모델이 초기의 instruction을 까먹는 경향이 있습니다.
(ChatGPT도 여기에 대해 명백한 한계를 보이죠)
이를 해결하기 위해 Context Distillation에서 영감을 받아 GAtt(Ghost Attention)을 도입했다고 합니다.
- 한국어 데이터
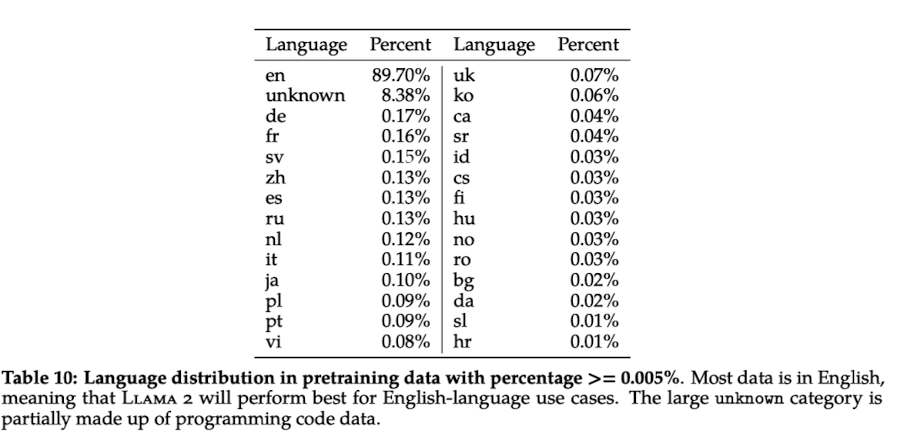
전체 데이터 중에서 단 0.6%만이 한국어 데이터에 해당합니다.
사실 이정도의 비중을 차지하고 있다는 점을 감안하면, ChatGPT와 같은 챗봇들이 학습한 것에 비해 엄청나게 좋은 성능을 보인다고도 볼 수 있겠죠.
참고로 학습된 한국어 데이터의 양은 이전에 비해 늘어난 것이라고 알려져 있고요, 실제로 한국어로 튜닝하여 추론해보면 이전보다 월등히 향상된 한국어 능력이 체감된다고 벌써부터 말이 나오고 있기도 합니다.
이는 주관적인 것일 수 있어서 연구 결과나 성과를 또 확인해 볼 필요가 있겠지만요.
- Safety & Helpfulness
논문을 읽으면서 좀 놀랐던 것이 모델의 안전성에 대해 엄청나게 꼼꼼히 다루고 있다는 점이었습니다.
Hallucination이 발생하지 않도록 애쓴 것은 두말 할 필요도 없고, 편향을 최대한 줄이기 위한 노력 등도 눈에 띄었습니다.
이를테면 성별, 지역 등에 의해 모델이 차별적인 출력 결과를 갖는지에 대해 면밀히 검토하고 이를 최소화하기 위해 노력했다는 것이죠.
LLM을 쉽사리 오픈소스로 공개하지 못하는 이유 중 하나가 이런 것 때문이라고 논문들에 밝히는 경우가 많은데, 결국 모델이 지닌 잠재력을 어떤 식으로 활용할지도 중요한 문제가 되는 것 같네요.
개인적 감상
요즘 계속해서 느끼는 것은 어느정도 기술적 성숙도가 충족되었고, 이를 최적화하여 사용하는 것에 대한 니즈가 가장 크다는 것입니다.
물론 성숙도가 높은 모델의 능력을 API로 활용하는 것이 비용적으로 이득일수도 있겠지만, 결국 이는 거대 공룡기업에 종속되는 지름길이고 특정 태스크에 특화시키기 어렵기도 하며 보안상 이슈를 피해갈 수 없기 때문입니다.
그렇기 때문에 현 상황에서 심지어 상업적으로도 이용가능한 오픈소스를 공개하여 많은 사람들이 이용할 수 있도록 한 Meta의 선택은 칭찬받아 마땅하다고 생각합니다.
일각에서는 이를 안전하지 않은 무책임한 선택이라고 비판할수도 있겠지만, 이를 악용한 사람들이 비판받아야 하는 것 아닌가 싶습니다.
위험성에 대해 충분히 인지하고 이를 완화하기 위한 노력이 충분히 드러난다고 생각합니다.
한편으로는 한국어 데이터를 활용하여 어떤 모델을 만들어 볼 수 있을지 굉장히 궁금해졌습니다.
사실 언어적인 특성이 다르기 때문에라고 보는 것이 맞을 수도 있겠지만, 어쨌든 한국어에 대해서는 많은 양의 데이터로 학습을 시킨다고 하더라도 뚜렷한 성과가 나타나지 않는 경우들이 많습니다.
최근 공개되었던 Eluther의 한국어 특화 모델도 생각보다 별로라는 평이 많더라구요.
그러다보니 성능이 끝내주는 영어 특화 모델의 출력물을 단순히 번역하는 방식으로 사용하는 것이 가장 효율적인고, 좋은 퍼포먼스로 이어진다는게 현재 정설에 가깝습니다.
개인적으로 무엇이 더 이득이 될 수 있을지는 지금 당장 판단하기는 어렵지만, 정말 한국어를 잘 학습한 모델이 등장할까가 궁금해집니다.
출처 : https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[GenAI, Meta]
LLaMA 모델을 발전시킨 LLaMA 2 모델과, 이를 대화 형식으로 fine-tuning한 LLaMA 2-CHAT 모델을 공개.
모델의 파라미터 개수는 7B부터 70B까지 다양함.
배경
ChatGPT를 필두로 LLM이 큰 주목을 받게 되었지만, 요즘은 사실 이 Meta에서 개발한 LLaMA 모델의 영향이 더욱 크다고 생각합니다.
OpenAI는 회사의 이름과 다르게 자신들의 기술을 베일 속에 꽁꽁 감춰두었고, 이런 기업들과 달리 Meta는 자신들의 모델 LLaMA를 오픈소스로 공개했죠.
물론 출시 초반에 모델의 가중치가 토렌트를 통해 공유되었던 것은 본인들의 의도한 바는 아니겠지만요.
어쨌든 LLaMA 모델이 파라미터 사이즈에 비해서 엄청나게 좋은 성능을 보여주면서 이런 모델을 backbone으로 삼아 tuning하는 연구들이 굉장히 많이 이뤄졌습니다.
스탠포드 대학에서 개발한 Alpaca도 엄청난 화제였고, ShareGPT라는 사이트에서 ChatGPT 유저들의 채팅 기록을 학습 데이터로 사용해 개발한 Vicuna도 크게 주목 받았죠.
하나 아쉬운 점으로 지적되었던 것이 이 모델을 상업적으로 이용할 수 없다는 것이었죠.
개인적으로는 이렇게 공개해준 것만으로 어디냐 싶기도 했지만, 이왕.. 오픈하는거 자유롭게 이용하면 더 좋겠다는 의견이 지배적이었습니다.
실제로 Meta의 깃허브에 상업적으로 이용가능하게끔 배포해달라는 요청도 굉장히 많았구요.
그런데 이번에는 상업적으로 이용 가능하면서도, 기존보다 성능도 더 우월한 모델을 개발하여 공개했다고 합니다.
수많은 연구자/개발자들이 여기에 관심을 갖고 있고, 빠른 속도로 결과물들을 공유하고 있는 상황입니다.
그래서 오늘은 아주 얕은 수준으로 LLaMA 2 페이퍼에 나타난 내용들을 최대한 간단히 정리하고자 합니다.
특징
당연히 instruction tuning과 RLHF(Reinforcement Learning with Human Feedback)가 적용되었습니다.
이때 rejection sampling과 PPO(Proximal Policy Optimization)이 핵심 테크닉입니다.
- 사전 학습
public하게 이용 가능한 데이터를 사용했다고 합니다.
사용된 데이터의 양은 2T(Trillion) token입니다.
학습 방식에 대해 LLaMA 1과 비교하면, 입력으로 받는 context의 길이가 길어졌다는 것과 GQA(grouped-query attention)를 적용했다는 차이점이 있습니다.
LLaMA 2 모델의 training loss를 시각화한 결과입니다.
그래프를 보면 알 수 있는 것처럼, 모델의 능력이 아직 포화상태에 이르지 않았습니다.
즉, 사이즈를 키우면 성능이 더 증가할 여지가 남아있다고 볼 수 있습니다.
- 모델 평가
MPT(MosaicML Pretrained Transformer), Falcon 모델들과 비교한 결과를 공개했습니다.
평가 대상이 되는 태스크들은 ‘Code, Commonsense Reasoning, World Knowledge, Reading Comprehension, MATH, Popular Aggregated Benchmarks’ 등입니다.
동일한 요청에 대해 여러 모델이 생성한 결과를 제시하고, 그중에 가장 선호되는 것을 파악한 결과입니다.
single-turn, multi-turn 둘 다 비교한 결과, LLaMA 2-CHAT은 오픈 소스 모델들(예를 들어 Falcon, MPT)에 비해 우월한 성능을 보여주었고, ChatGPT와의 비교에서는 이와 비등한 수준으로 확인되었습니다.
- Multi-Turn Consistency
챗봇의 경우 여러 턴의 대화가 이어지면 모델이 초기의 instruction을 까먹는 경향이 있습니다.
(ChatGPT도 여기에 대해 명백한 한계를 보이죠)
이를 해결하기 위해 Context Distillation에서 영감을 받아 GAtt(Ghost Attention)을 도입했다고 합니다.
- 한국어 데이터
전체 데이터 중에서 단 0.6%만이 한국어 데이터에 해당합니다.
사실 이정도의 비중을 차지하고 있다는 점을 감안하면, ChatGPT와 같은 챗봇들이 학습한 것에 비해 엄청나게 좋은 성능을 보인다고도 볼 수 있겠죠.
참고로 학습된 한국어 데이터의 양은 이전에 비해 늘어난 것이라고 알려져 있고요, 실제로 한국어로 튜닝하여 추론해보면 이전보다 월등히 향상된 한국어 능력이 체감된다고 벌써부터 말이 나오고 있기도 합니다.
이는 주관적인 것일 수 있어서 연구 결과나 성과를 또 확인해 볼 필요가 있겠지만요.
- Safety & Helpfulness
논문을 읽으면서 좀 놀랐던 것이 모델의 안전성에 대해 엄청나게 꼼꼼히 다루고 있다는 점이었습니다.
Hallucination이 발생하지 않도록 애쓴 것은 두말 할 필요도 없고, 편향을 최대한 줄이기 위한 노력 등도 눈에 띄었습니다.
이를테면 성별, 지역 등에 의해 모델이 차별적인 출력 결과를 갖는지에 대해 면밀히 검토하고 이를 최소화하기 위해 노력했다는 것이죠.
LLM을 쉽사리 오픈소스로 공개하지 못하는 이유 중 하나가 이런 것 때문이라고 논문들에 밝히는 경우가 많은데, 결국 모델이 지닌 잠재력을 어떤 식으로 활용할지도 중요한 문제가 되는 것 같네요.
개인적 감상
요즘 계속해서 느끼는 것은 어느정도 기술적 성숙도가 충족되었고, 이를 최적화하여 사용하는 것에 대한 니즈가 가장 크다는 것입니다.
물론 성숙도가 높은 모델의 능력을 API로 활용하는 것이 비용적으로 이득일수도 있겠지만, 결국 이는 거대 공룡기업에 종속되는 지름길이고 특정 태스크에 특화시키기 어렵기도 하며 보안상 이슈를 피해갈 수 없기 때문입니다.
그렇기 때문에 현 상황에서 심지어 상업적으로도 이용가능한 오픈소스를 공개하여 많은 사람들이 이용할 수 있도록 한 Meta의 선택은 칭찬받아 마땅하다고 생각합니다.
일각에서는 이를 안전하지 않은 무책임한 선택이라고 비판할수도 있겠지만, 이를 악용한 사람들이 비판받아야 하는 것 아닌가 싶습니다.
위험성에 대해 충분히 인지하고 이를 완화하기 위한 노력이 충분히 드러난다고 생각합니다.
한편으로는 한국어 데이터를 활용하여 어떤 모델을 만들어 볼 수 있을지 굉장히 궁금해졌습니다.
사실 언어적인 특성이 다르기 때문에라고 보는 것이 맞을 수도 있겠지만, 어쨌든 한국어에 대해서는 많은 양의 데이터로 학습을 시킨다고 하더라도 뚜렷한 성과가 나타나지 않는 경우들이 많습니다.
최근 공개되었던 Eluther의 한국어 특화 모델도 생각보다 별로라는 평이 많더라구요.
그러다보니 성능이 끝내주는 영어 특화 모델의 출력물을 단순히 번역하는 방식으로 사용하는 것이 가장 효율적인고, 좋은 퍼포먼스로 이어진다는게 현재 정설에 가깝습니다.
개인적으로 무엇이 더 이득이 될 수 있을지는 지금 당장 판단하기는 어렵지만, 정말 한국어를 잘 학습한 모델이 등장할까가 궁금해집니다.
출처 : https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/