
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
여러 개의 LoRA 모듈을 구성하여 task 간 일반화 성능이 뛰어난 LoRA 허브를 제시.
few-shot 상황에서 in-context learning 능력이 준수함을 BBH(Big-Bench Hard) 벤치마크로 검증
- 배경
모델의 학습 가능한 파라미터수가 날이 갈수록 늘어나자 이를 최소화하며 동일한 성능을 유지하고자 하는 연구들이 이어지고 있습니다.
그중에서도 행렬 분해를 통해 학습 가능한 파라미터의 수를 획기적으로 줄이면서 기존의 성능에 버금가는 모델이 될 수 있도록 하는 학습 방식으로, LoRA가 가장 크게 주목을 받았죠.
하지만 이는 LLM이 가진 일반화 능력을 포기하고 특정 태스크나 도메인에 대해서만 좋은 성능을 보이게 된다는 한계를 지니고 있습니다.
본 논문에서는 여러 개의 LoRA 모듈이 합쳐서 학습하고, 특정 태스크에 대해 필요한 모듈을 사람이 지정하지 않고도 자동적으로 활용될 수 있도록 하는 LoRA Hub를 제안합니다.
- 특징
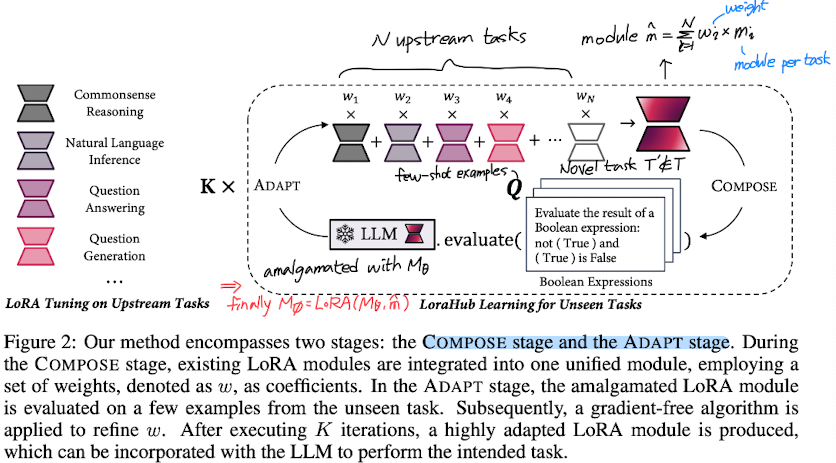
아키텍쳐는 크게 ADAPT, COMPOSE 두 단계로 나뉩니다.
COMPOSE
여러 개의 LoRA 모듈은 하나의 모듈로 통합되고 w라는 coefficient를 갖습니다.
이때 모듈의 개수는 task의 개수 N개 입니다.
ADAPT
한 개로 통합된 모듈은 파라미터가 고정된 LLM으로 평가받습니다.
이때 few-shot examples Q로를 이용하고, 통합된 모듈의 성능을 높이기 위해 w를 업데이트 합니다.
이는 gradient를 저장하는 방식인 경사 하강법과 달리, 이를 저장하지 않는 gradient-free algorithm입니다.
모델을 학습하는 데 있어서 upstream task는 굉장히 다양할 수 있습니다.
논문에서는 200개의 다른 태스크들을 통합하고, 그중에서 20개의 LoRA 모듈을 임의 선정하여 실험했다고 합니다.
LoRA를 적용하기 위해서 Huggingface의 PEFT 라이브러리를 사용했다고 합니다.
이 방식을 이용하면 unseen task에 대해 20개 미만의 예시가 주어지는 경우 lora tuning보다 월등한 성능을 보여줍니다.
- 개인적 감상
참신한(?) 아이디어에 비해서는 다소 아쉬운 성능을 보여준 것 같습니다.
정말 최근에 친구와 같이 이 아이디어에 대해 논의한 적이 있었는데 깜짝 놀랐어요.
뭐 여러 개의 어댑터를 만들어서 필요할 때 갖다쓰면 되지 않냐, 그게 말이 되냐 마냐 이런 이야기를 나눴는데 굉장히 유사한 개념의 논문이 벌써 나와서 신기했습니다.
예전에 VisualGPT나 HuggingGPT, Gorilla 등을 보는 기분인데요, 아무래도 없던 것을 새로 만들어 내는 것만큼이나 기존의 것들을 잘 활용하는 것도 엄청나게 중요하다는 생각이 듭니다.
한편으로는 LLM들에 대해 여러 기법을 편하게 적용할 수 있는 PEFT 라이브러리도 있으니 이를 적극적으로 활용하고 공부할 필요가 있다는 생각이 들었습니다.
개인적으로 부족하다고 생각한 것은 아직 업데이트 방식에 대해 이해하지 못한 것입니다.
gradient를 저장하지 않는데 어떤 방식으로 w 행렬을 업데이트 하는지 잘 파악이 안됩니다.
그래서 결과론적으로 이 방식이 효율적이더라, 이해하게 된 점이 아쉽습니다.


출처 : https://arxiv.org/abs/2307.13269
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition
Low-rank adaptations (LoRA) are often employed to fine-tune large language models (LLMs) for new tasks. This paper investigates LoRA composability for cross-task generalization and introduces LoraHub, a strategic framework devised for the purposive assembl
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
여러 개의 LoRA 모듈을 구성하여 task 간 일반화 성능이 뛰어난 LoRA 허브를 제시.
few-shot 상황에서 in-context learning 능력이 준수함을 BBH(Big-Bench Hard) 벤치마크로 검증
- 배경
모델의 학습 가능한 파라미터수가 날이 갈수록 늘어나자 이를 최소화하며 동일한 성능을 유지하고자 하는 연구들이 이어지고 있습니다.
그중에서도 행렬 분해를 통해 학습 가능한 파라미터의 수를 획기적으로 줄이면서 기존의 성능에 버금가는 모델이 될 수 있도록 하는 학습 방식으로, LoRA가 가장 크게 주목을 받았죠.
하지만 이는 LLM이 가진 일반화 능력을 포기하고 특정 태스크나 도메인에 대해서만 좋은 성능을 보이게 된다는 한계를 지니고 있습니다.
본 논문에서는 여러 개의 LoRA 모듈이 합쳐서 학습하고, 특정 태스크에 대해 필요한 모듈을 사람이 지정하지 않고도 자동적으로 활용될 수 있도록 하는 LoRA Hub를 제안합니다.
- 특징
아키텍쳐는 크게 ADAPT, COMPOSE 두 단계로 나뉩니다.
COMPOSE
여러 개의 LoRA 모듈은 하나의 모듈로 통합되고 w라는 coefficient를 갖습니다.
이때 모듈의 개수는 task의 개수 N개 입니다.
ADAPT
한 개로 통합된 모듈은 파라미터가 고정된 LLM으로 평가받습니다.
이때 few-shot examples Q로를 이용하고, 통합된 모듈의 성능을 높이기 위해 w를 업데이트 합니다.
이는 gradient를 저장하는 방식인 경사 하강법과 달리, 이를 저장하지 않는 gradient-free algorithm입니다.
모델을 학습하는 데 있어서 upstream task는 굉장히 다양할 수 있습니다.
논문에서는 200개의 다른 태스크들을 통합하고, 그중에서 20개의 LoRA 모듈을 임의 선정하여 실험했다고 합니다.
LoRA를 적용하기 위해서 Huggingface의 PEFT 라이브러리를 사용했다고 합니다.
이 방식을 이용하면 unseen task에 대해 20개 미만의 예시가 주어지는 경우 lora tuning보다 월등한 성능을 보여줍니다.
- 개인적 감상
참신한(?) 아이디어에 비해서는 다소 아쉬운 성능을 보여준 것 같습니다.
정말 최근에 친구와 같이 이 아이디어에 대해 논의한 적이 있었는데 깜짝 놀랐어요.
뭐 여러 개의 어댑터를 만들어서 필요할 때 갖다쓰면 되지 않냐, 그게 말이 되냐 마냐 이런 이야기를 나눴는데 굉장히 유사한 개념의 논문이 벌써 나와서 신기했습니다.
예전에 VisualGPT나 HuggingGPT, Gorilla 등을 보는 기분인데요, 아무래도 없던 것을 새로 만들어 내는 것만큼이나 기존의 것들을 잘 활용하는 것도 엄청나게 중요하다는 생각이 듭니다.
한편으로는 LLM들에 대해 여러 기법을 편하게 적용할 수 있는 PEFT 라이브러리도 있으니 이를 적극적으로 활용하고 공부할 필요가 있다는 생각이 들었습니다.
개인적으로 부족하다고 생각한 것은 아직 업데이트 방식에 대해 이해하지 못한 것입니다.
gradient를 저장하지 않는데 어떤 방식으로 w 행렬을 업데이트 하는지 잘 파악이 안됩니다.
그래서 결과론적으로 이 방식이 효율적이더라, 이해하게 된 점이 아쉽습니다.
출처 : https://arxiv.org/abs/2307.13269
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition
Low-rank adaptations (LoRA) are often employed to fine-tune large language models (LLMs) for new tasks. This paper investigates LoRA composability for cross-task generalization and introduces LoraHub, a strategic framework devised for the purposive assembl
arxiv.org