최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
multimodal 전용의 pair data 없이 frozen encoder로 feature를 추출하여,
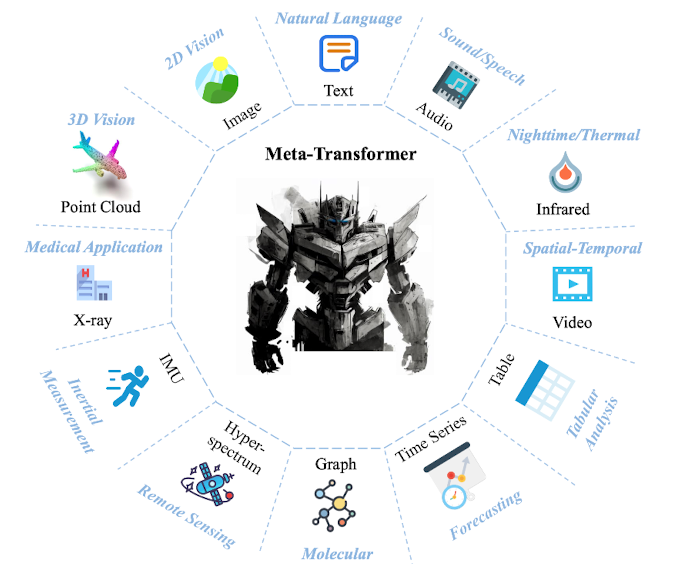
12개의 modality에 대해 동시에 이해할 수 있는 transformer 기반 모델, Meta-Transformer

- 배경
마치 인간의 뇌처럼, 인공지능 모델도 한 modality에서 얻은 지식을 다른 곳으로 전이할 수 있도록 하는 연구가 이어지고 있습니다.
하지만 근본적으로 다른 modality 데이터는 그 특징과 성질이 너무 다르기 때문에 쉽지 않은 문제죠.
그래서 지금까지는 대부분 image - text 수준을 벗어나는 연구가 거의 없었습니다.
그렇기 때문에 몇 달 전 Meta에서 6개의 modality에 대해 학습한 모델 ImageBind를 공개한 것이 굉장히 큰 화제가 되었죠.
본 논문은 최초로 12개의 modality 데이터를 동시에 encoding할 수 있는 multi-modal model을 공개했습니다.
- 특징
방금 언급한 것처럼 12개의 다른 modality에 해당하는 데이터를 동시에 encoding 할 수 있는 것이 가장 큰 특징입니다.
정확히는 세 개의 구성 요소가 있습니다.
- modality-specialist : data-to-sequence tokenization
- modality-shared encoder : extracting representations
- task-specific head : for downstream tasks
이때 가장 중요한 전제는 각 modality에 적합한 ‘parameter space’가 존재하고 이들의 교집합이 공집합이 아니다, 즉 공통 공간이 반드시 존재한다는 것입니다.

각 modality에 대해 수행한 태스크와, 사용한 벤치마크 데이터셋, 데이터 사이즈를 정리한 표는 다음과 같습니다.
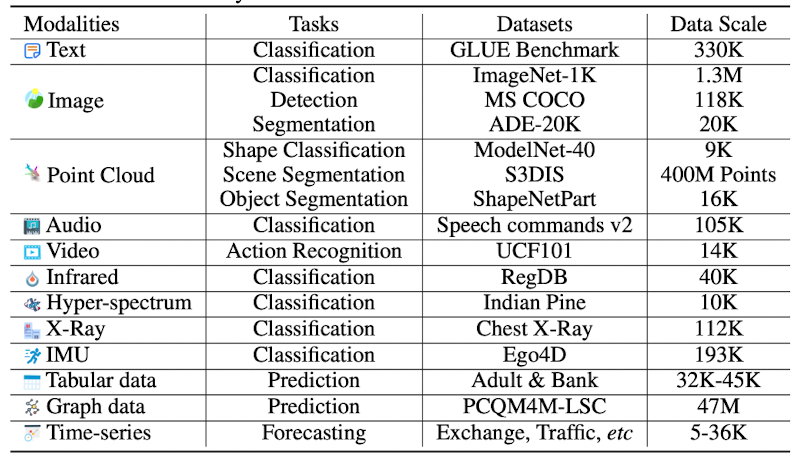
modality가 12 종류나 되다보니 실험 결과도 각각 정리가 되어 있는데, 자세한 결과를 확인하고 싶으신 분들은 논문을 직접 보시길 추천드립니다.
아주 간단히 결론적으로만 말하면, 일부에 대해서는 기존 SOTA 모델 이상의 성능을 보여줬고, 대부분은 거기에 준하는 성능을 보여줬다, 고 할 수 있습니다.
물론 이는 fine-tuning을 했을 때의 기준이고, 특정 태스크에 대해서는 zero-shot 의 성능과 fine-tuning의 성능이 비교되어 있기도 합니다.
어쨌든 쌍을 이루는 데이터셋으로 사전학습되지 않은 모델이 이정도로 좋은 성능을 발휘한다는 것 자체가 대단한 일이죠.
- 개인적 감상
그럼에도 아직까지 아쉬운 것은 높은 메모리 및 연산 요구량입니다.
아무래도 여러 개의 modality를 동시에 다루기 위해 encoder 사이즈가 modality 개수에 비례해서 커지기 때문입니다.
저자는 또한 시간적, 구조적 인지에 대해 취약한 것을 본 연구의 한계로 꼽았습니다.
위 표에서 알 수 있듯이, 각 modality를 대표하는 태스크들이긴 하지만 상대적으로 쉬운 난이도의 태스크들로 구성이 되어 있습니다.
따라서 이 모델이 정말로 여러 modality에 대해 폭넓게 이해하고 있는 것이 맞는지 확인할 필요가 있고, 이는 cross-modality에 대한 검증이 필요하다는 뜻으로 이해할 수 있습니다.
출처 : https://arxiv.org/abs/2307.10802
Meta-Transformer: A Unified Framework for Multimodal Learning
Multimodal learning aims to build models that can process and relate information from multiple modalities. Despite years of development in this field, it still remains challenging to design a unified network for processing various modalities ($\textit{e.g.
arxiv.org